2023年美赛特等奖论文-C-2322645-解密.pdf
版权申诉
62 浏览量
2024-05-06
22:06:00
上传
评论
收藏 1.4MB PDF 举报


Problem Chosen
C
2023
MCM/ICM
Summary Sheet
Team Control Number
2322645
With the rising popularity of Wordle, people have eagerly taken to Twitter
to report their results daily by the tens of thousands. Three very natural
questions arise regarding this data: (1) Can we use this data to predict the
difficulty of a given target word in Wordle? (2) Can we use this data to
predict future Wordle player reporting trends? (3) How does the difficulty
of given target word affect player reporting and results? In our paper, we
develop a comprehensive Bayesian model consisting of three submodels which
predict the distribution of the number of guesses, number of reported results
on Twitter and the number of reporting players playing in hard mode.
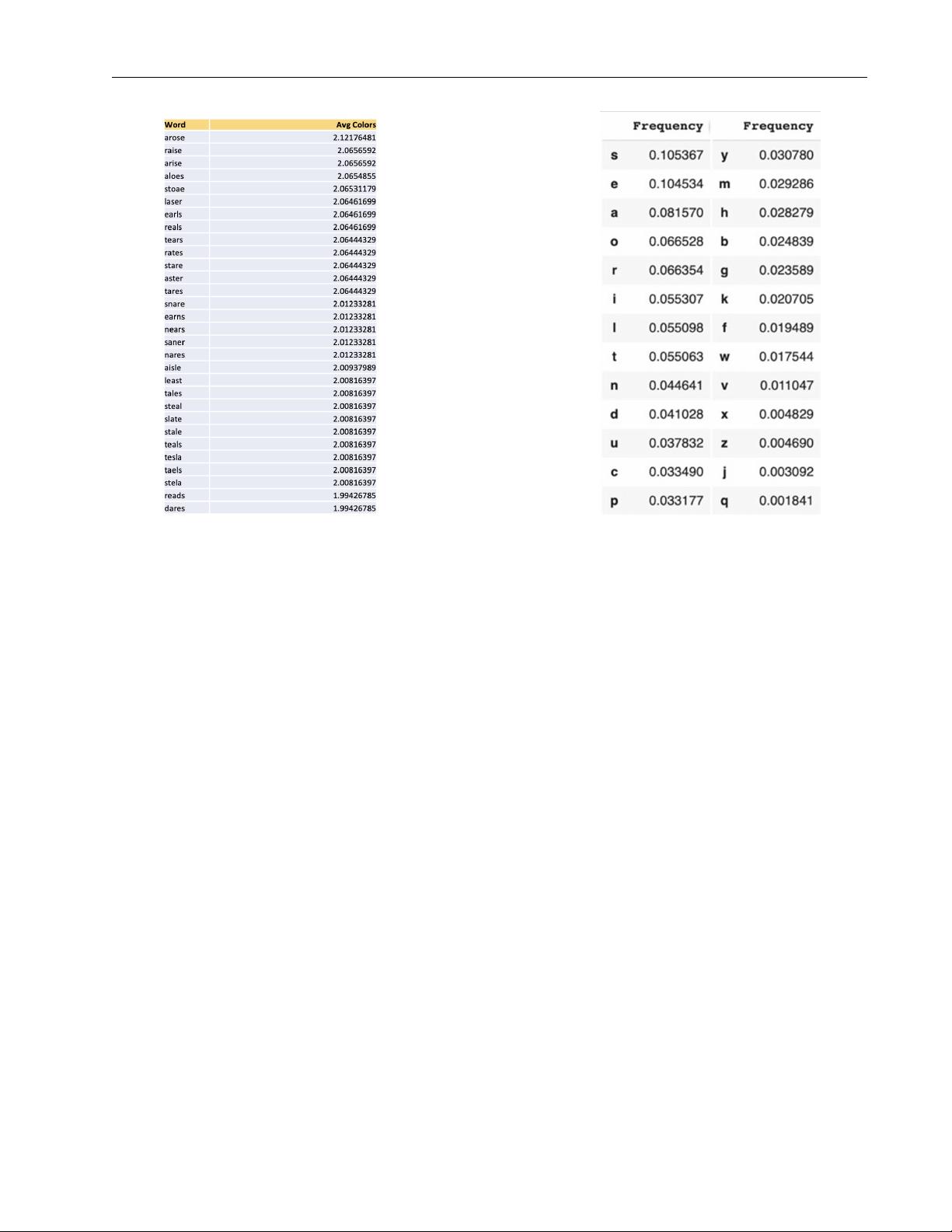
Initially, we decompose words into quantifiable traits associated with rel-
evant difficulty characteristics. Most notably, we formulate a novel Wordle-
specific entropy measure we call Subset Entropy which effectively quantifies
the average amount of information revealed by typical players after initial
guesses. We also develop a method to represent the distribution of player
attempts, and hence the observed difficulty of a word, using just two values
α, β corresponding to the cumulative mass function of the Beta distribution.
We use a preliminary Lasso regression to isolate the most relevant predictors
of word difficulty, which we then use in our Bayesian model.
Our Bayesian model predicts, for a given date and word, the reported
difficulty of a word, the number of player reports, and the number of players
reporting playing in hard-mode. To accomplish these three tasks, it is made
up of three submodels which are conditionally independent given the data,
making it efficient to sample from its posterior using Markov Chain Monte-
Carlo (MCMC).
We find that a word having a higher number of unique letters, usage
frequency in English, average number of revealed yellow squares over all
guesses, and Subset Entropy all make a word easier for players to guess. We
also find that higher word difficulty decreases the number of player reports.
Under the assumption that the Times choose words randomly, this can be
interpreted as a causal effect.
Our model is able to predict outcomes for new data and retrodict for old
data. Our model gives gives a 95% prediction interval that between 20238
and 27876 players will report results for “eerie” on March 1, 2023 and that
it will be in the 50th percentile of difficulty. Most notably, our model does
not just provide such simple point estimates and prediction intervals, but
full posterior distributions.
Keywords: Entropy, Lasso regression, MCMC, Bayesian methods,
Causal inference



剩余21页未读,继续阅读
资源评论













