2023年美赛特等奖论文-C-2314151-解密.pdf
版权申诉
12 浏览量
2024-05-06
22:05:56
上传
评论
收藏 2.13MB PDF 举报


Problem Chosen
C
2023
MCM/ICM
Summary Sheet
Team Control Number
2314151
Breaking the Wordle
Summary
As Wordle has become popular on social media, more and more users have played the scrabble
game. How do time and word attributes affect the number of reports, distribution of attempts, and
other report-related information? Therefore, a modeling analysis was conducted using the game data
from 2022.
Before building the model, we cleaned and normalized the given data and identified word at-
tributes such as the number of repeated letters, number of vowel letters, number of consonant letters,
commonness, and frequency. Preliminary preparations were made for model building and solving.
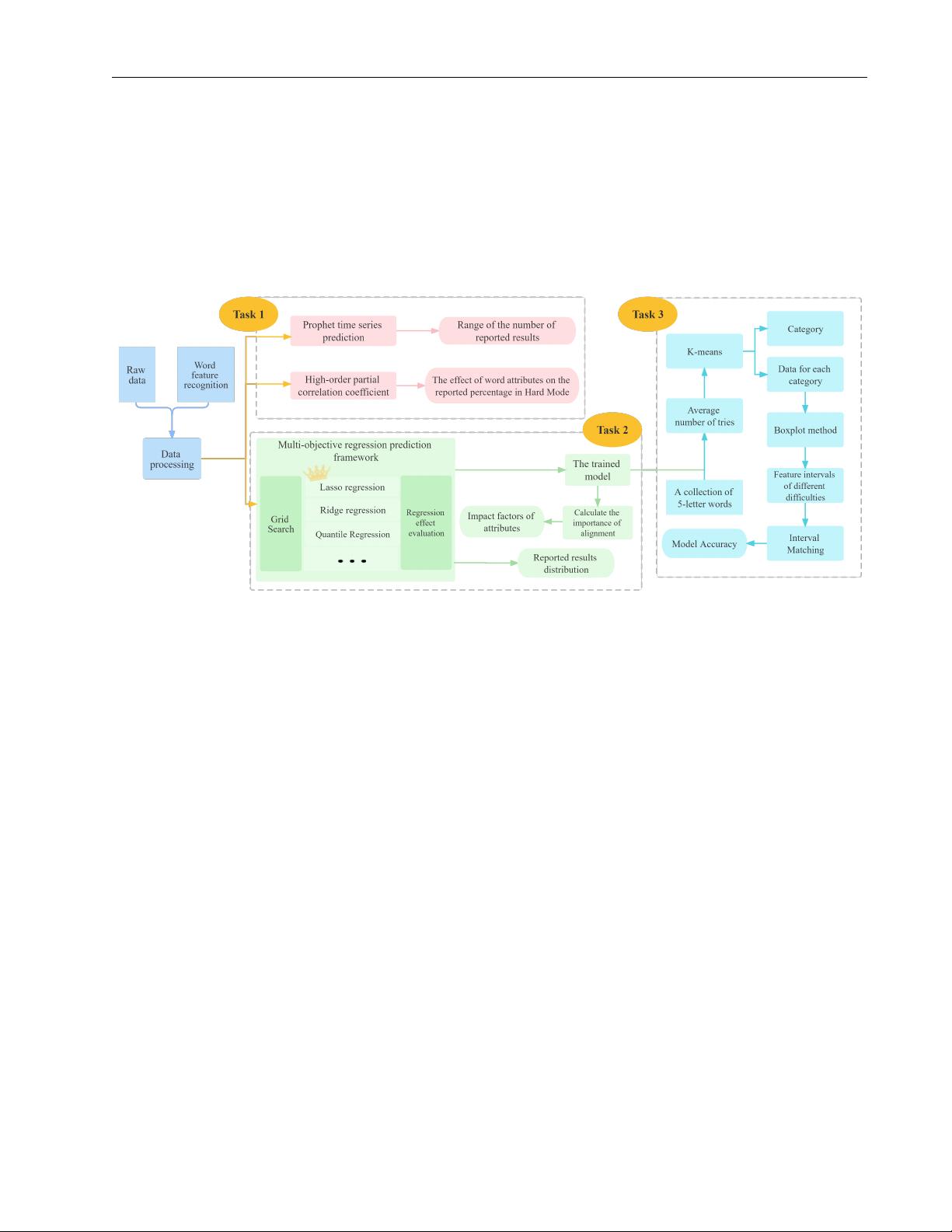
First, to predict the number of future reports, a prophet-based time-series prediction model was
built, considering the effects of trends, seasonality, and holidays. The predictions yielded a range
of report numbers for March 1, 2023: [10355,18742]. Regarding the variation of report numbers,
during the week, the number of reports tends to be highest on Wednesdays and lowest on weekends.
In exploring the effect of word attributes on the proportion of difficulty reports, we calculated higher-
order partial correlation coefficients for both, controlling for the interaction between word attributes,
and found that the number of vowel letters, the number of non-repeats, and word commonness were
negatively correlated. The number of consonant letters and the number of non-repeats was positively
correlated.
Secondly, an optimized multi-objective regression prediction framework was developed to
explore the effects of word attributes on the distribution of reported outcomes. The framework chose
the optimal lasso regression to predict the test set with an RMSE of 0.80. The distribution of the
number of attempts to predict ’EERIE’ was (0, 4, 17, 34, 30, 13, 2). The ranking importance of each
attribute was calculated, and it was found that the number of consonant letters, number of vowel letters,
and frequency had a more significant influence on the distribution of reported results with the influence
factors of 4.226, 3.993, and 1.253, respectively.
Next, the above model was used to predict the distribution of reported outcomes for each word in
the 5-letter word set. Then, K-means was used to classify the words into high (≥4.37), medium (4.13-
4.37), and low (<4.13) difficulty categories based on the average number of attempts, and it was found
that the Number of duplicates, Maximum of repeats, Prevalence and Frequency differed significantly
across categories. Moreover, the interval of each attribute was divided. According to the established
model, ’EERIE’ is difficult. The model’s accuracy is 91.36 %by matching the attribute intervals for
different difficulty words, and it can be inferred that the established model and the divided attribute
intervals are reasonable.
Finally, the sensitivity analysis results demonstrate that our model is robust and reliable. In addition,
The study of the data set also revealed the declining popularity of Wordle and the increasing percentage
of difficult mode challenges, and provided the New York Times with suggestions for restoring the
game’s popularity.
Keywords: Wordle analysis, Prophet, High-order partial correlation, Multi-objective regression
forecasting, K-means



剩余24页未读,继续阅读
资源评论













