参赛队号:#33154
4
Abstract
The new coronavirus pneumonia 2019-nCoV has brought profound disasters to China
and the whole world, and has also caused an irreversible impact on the world economy. The
virus is highly contagious and harmful, and requires us to be highly vigilant. The current
epidemic situation in China is basically under control, but in order to avoid asymptomatic
infections causing the epidemic to counterattack, it is necessary for us to use relevant
mathematical algorithms, combined with the background of big data, to carry out relevant
analysis and propose countermeasures.
First, we classify and preprocess the data given in the attachment, including data integrity,
redundancy, and correlation analysis, which is the basis of subsequent modeling.
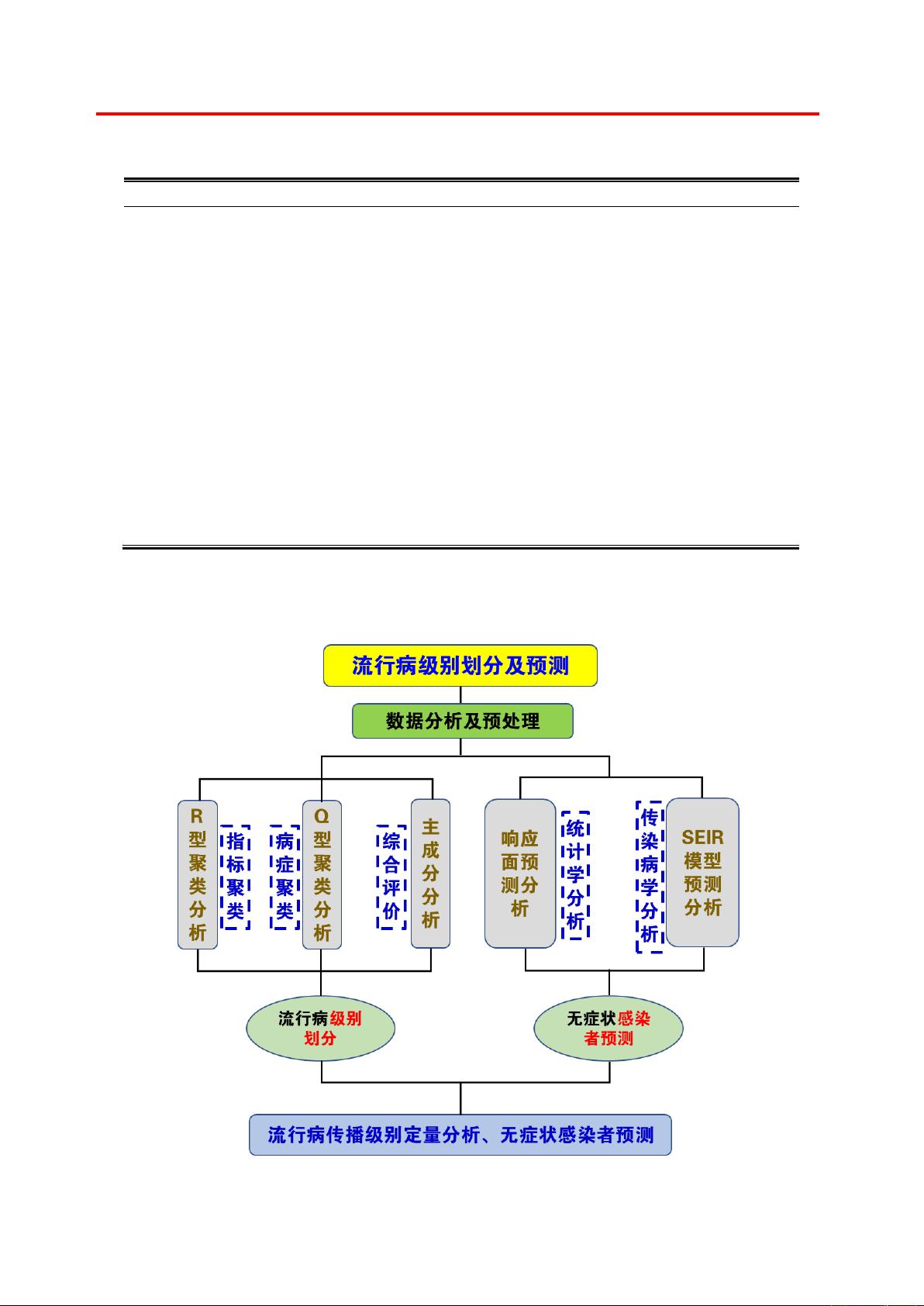
In response to question 1, we selected 16 relatively famous epidemics and considered 14
evaluation indicators. First, we selected the R-type clustering method to reduce the
dimensionality of the indicators; then, based on the epidemiological classification of the
epidemic, the Q-type clustering method was used to divide the 16 diseases into four categories:
sporadic, outbreak, popularity and pandemic, to achieve quantitative identification between all
levels. Finally, we conducted a comprehensive evaluation of different types of epidemics
according to the principal component analysis method, and reasonably quantified the
boundaries between "epidemic" and "pandemic" diseases.
For problem two, according to the cluster analysis results in problem one and the
established principal component evaluation model, the infection degree in different regions is
graded, and then the corresponding sampling countermeasures are given according to the
classification results. In the prediction of asymptomatic infections, taking Hubei Province as
an example, the analysis is carried out from two aspects of statistics and epidemiology.
Statistical methods, we chose the response surface prediction model, and obtained the
sensitivity of four factors to the number of asymptomatic infections: basic infection number
R0> cure rate Rc> number of patients P> latent period T; epidemiology The revised SEIR
model was selected, and the prediction results indicated that the control measures will
continue to be implemented, and the number of newly-increased asymptomatic infections will
drop to zero around mid to late May. This is basically consistent with the previous response
surface prediction results, indicating that the prediction model is reasonable and the prediction
results are of higher accuracy.
Finally, we wrote a letter of recommendation to WHO, explaining our understanding of
the virus and giving relevant countermeasures.
Key words: Cluster analysis; Principal component analysis; Response surface prediction;
Modified SEIR model; 2019-nCoV