规划问题算法-就业问题的数学建模分析.pdf
版权申诉
106 浏览量
2022-05-01
19:59:44
上传
评论
收藏 854KB PDF 举报


全
全
国
国
第
第
六
六
届
届
研
研
究
究
生
生
数
数
学
学
建
建
模
模
竞
竞
赛
赛
题 目
就业问题的数学建模分析
摘 要
就业问题分析的难点在于涉及面广、影响因素多、数据量大,因此本文分宏
观、中观、微观三个层次,通过聚类分析、主成分分析和相关分析,从影响就业
的因素中归纳出 6 个关键性的就业因素影响指标。依据 6 个指标与城镇登记失业
率的高度相关性,建立了城镇登记失业率由 6 个指标线性组合构成的预测模型。
考虑到我国城镇登记失业率定义的局限性,按照国际标准对失业率进行重新建
模,并以 2008 年的失业率数据对比分析了国际国内两种失业率定义的合理性。
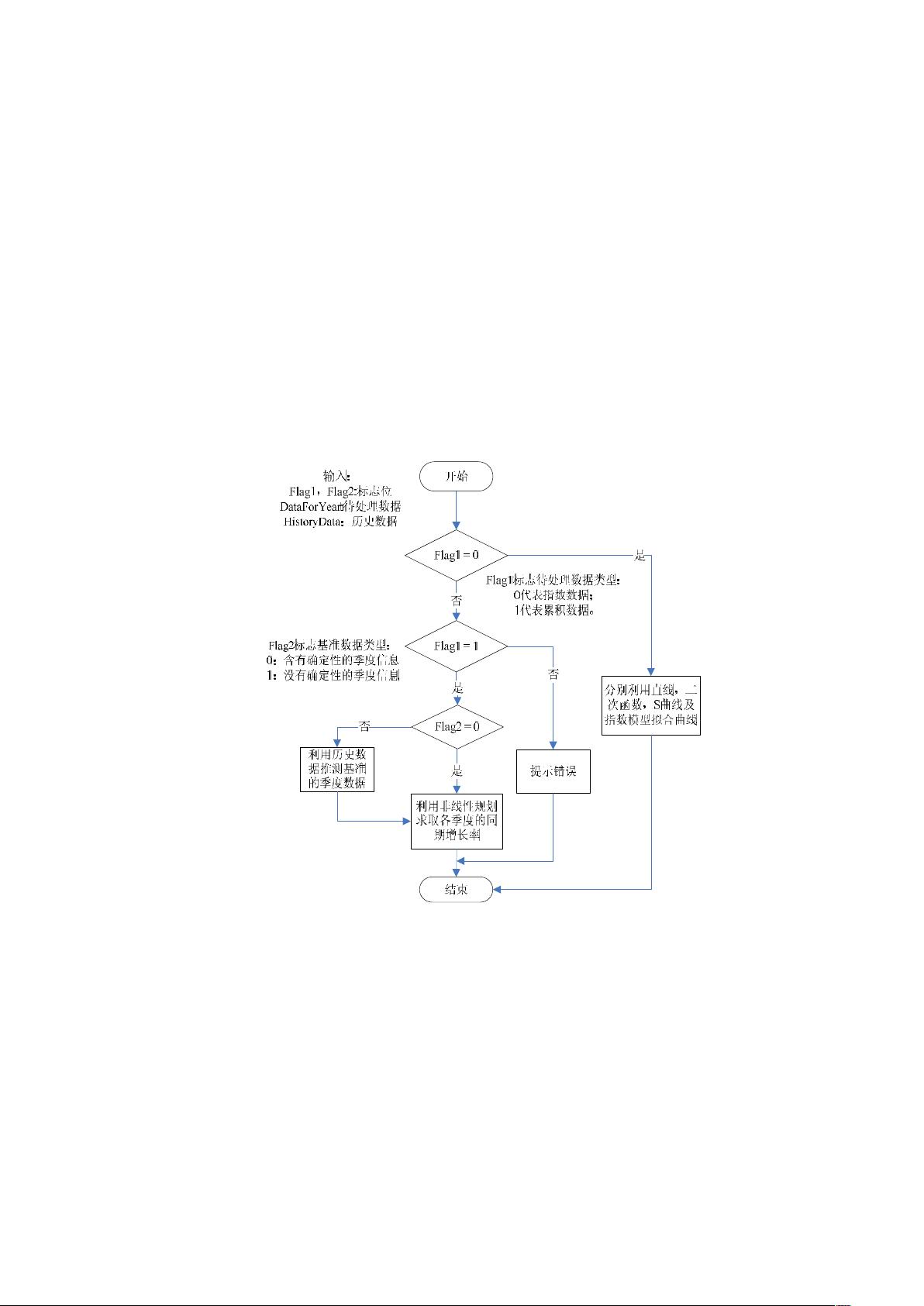
考虑到地区和行业的差异,以 2001~2007 年的数据分别分地区和分行业建立
了失业率预测模型和从业人数预测模型,提出了地区内部失业率、预期岗位裕量、
行业内部失业率、国家投资回报指数的概念,并以 2008 年的数据验证了模型的
准确性。依据分地区精确预测模型和分行业精确预测模型分别对 2009 年和 2010
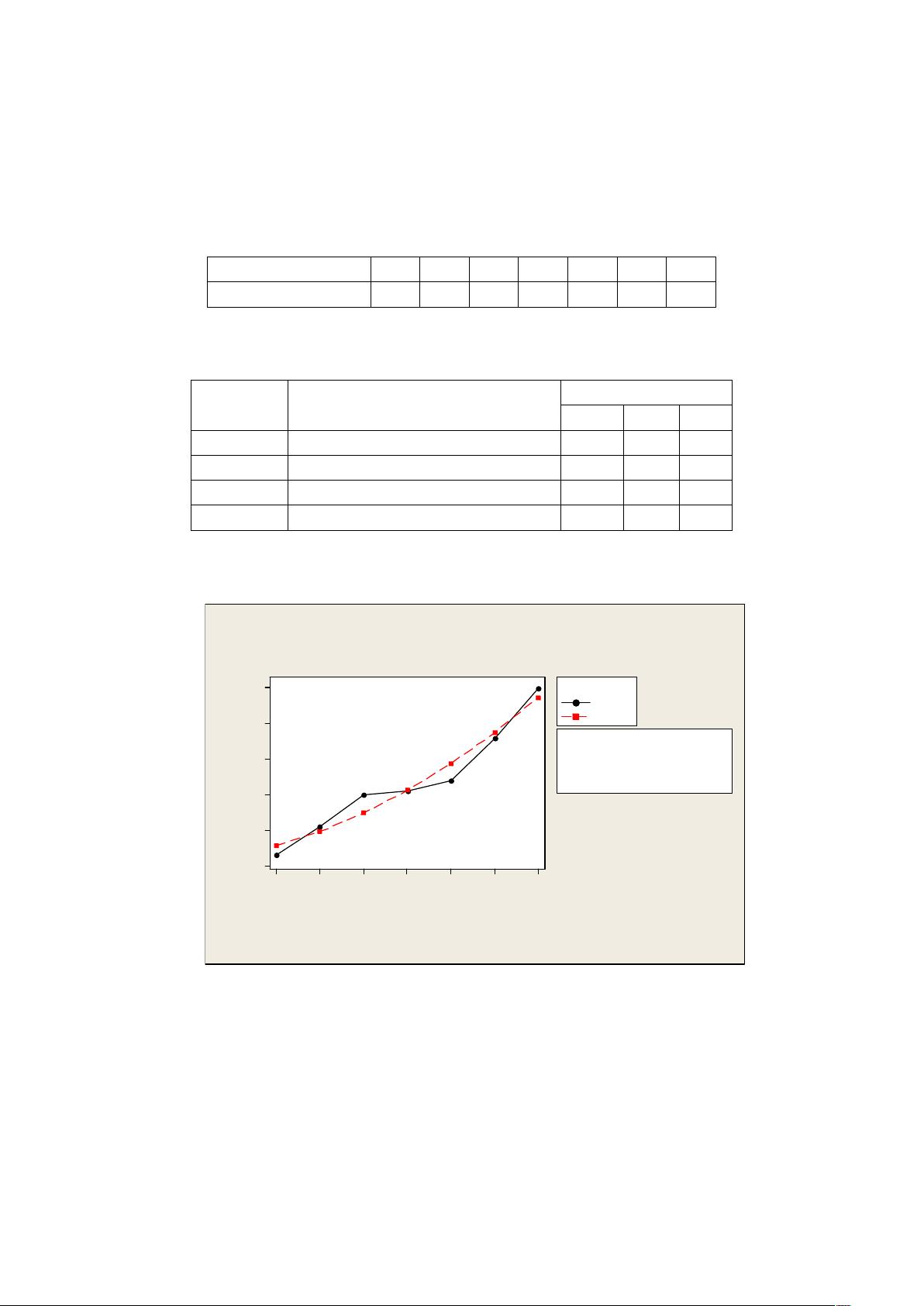
年上半年的失业率和从业人数进行了预测,分地区预测失业率的结果:2009 年
第一季度为 4.38%,第二季度为 4.82%,第三季度为 4.33%,第四季度为 4.91%,
2010 年第一季度为 4.57%,第二季度为 4.92%;分行业预测的结果为:2009 年
第一季度为 4.32%,第二季度为 4.83%,第三季度为 4.42%,第四季度为 4.09%,
2010 年第一季度为 4.85%,第二季度为 4.70%。
依据分地区精确预测模型和分行业精确预测模型得到的预期岗位裕量和国
家投资回报指数两个指标,对行业和地区进行了划分,总结出从促进就业的角度
对政府单位投资反应最灵敏的十大行业和十大地区,并与国家十大产业振兴计划
对比分析,验证了国家政策的科学合理性和模型的准确有效性。
关键词:主成分分析 聚类分析 预测模型 预期岗位裕量 投资回报指数
参赛队号
9000221
队员姓名
沈新民 李杰 曹建平
参赛密码
(由组委会填写)


剩余53页未读,继续阅读
资源评论


普通网友
- 粉丝: 12w+
- 资源: 9335









最新资源
- git使用文档(一步一步教你使用Git仓库管理代码)
- 进制转换(通用版).cpp
- linux实践之从DistroWatch排名第三的EndeavourOS转到排名第五的Manjaro工作机迁移
- Discuz模板+资讯博客课程干货+商业版(GBK+UTF)
- 基于Selenium的Java爬虫实战(内含谷歌浏览器Chrom和Chromedriver版本123.0.6292.0)
- RB308A-SOT23-5 单节锂电池保护IC 深圳市可芯电子有限公司.pdf
- Ubuntu下安装JDK
- 基于Selenium的Java爬虫实战(内含谷歌浏览器Chrom和Chromedriver版本123.0.6291.0)
- Android基础之用Eclipse建立工程
- WZLR(2).ipynb
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


