
《RapidMiner 数据分析与挖掘实战》第 7 章
第 7 章 数据预处理
在数据挖掘中,海量的原始数据中存在着大量不完整(有缺失值)、不一致、有异常
的数据,严重影响到数据挖掘建模的执行效率,甚至可能导致挖掘结果的偏差,所以进行
数据清洗就显得尤为重要,数据清洗完成后接着进行或者同时进行数据集成、转换、规约
等一系列的处理,该过程就是数据预处理。数据预处理一方面是要提高数据的质量,另一
方面是要让数据更好地适应特定的挖掘技术或工具。统计发现,在数据挖掘的过程中,数
据预处理工作量占到了整个过程的 60%。
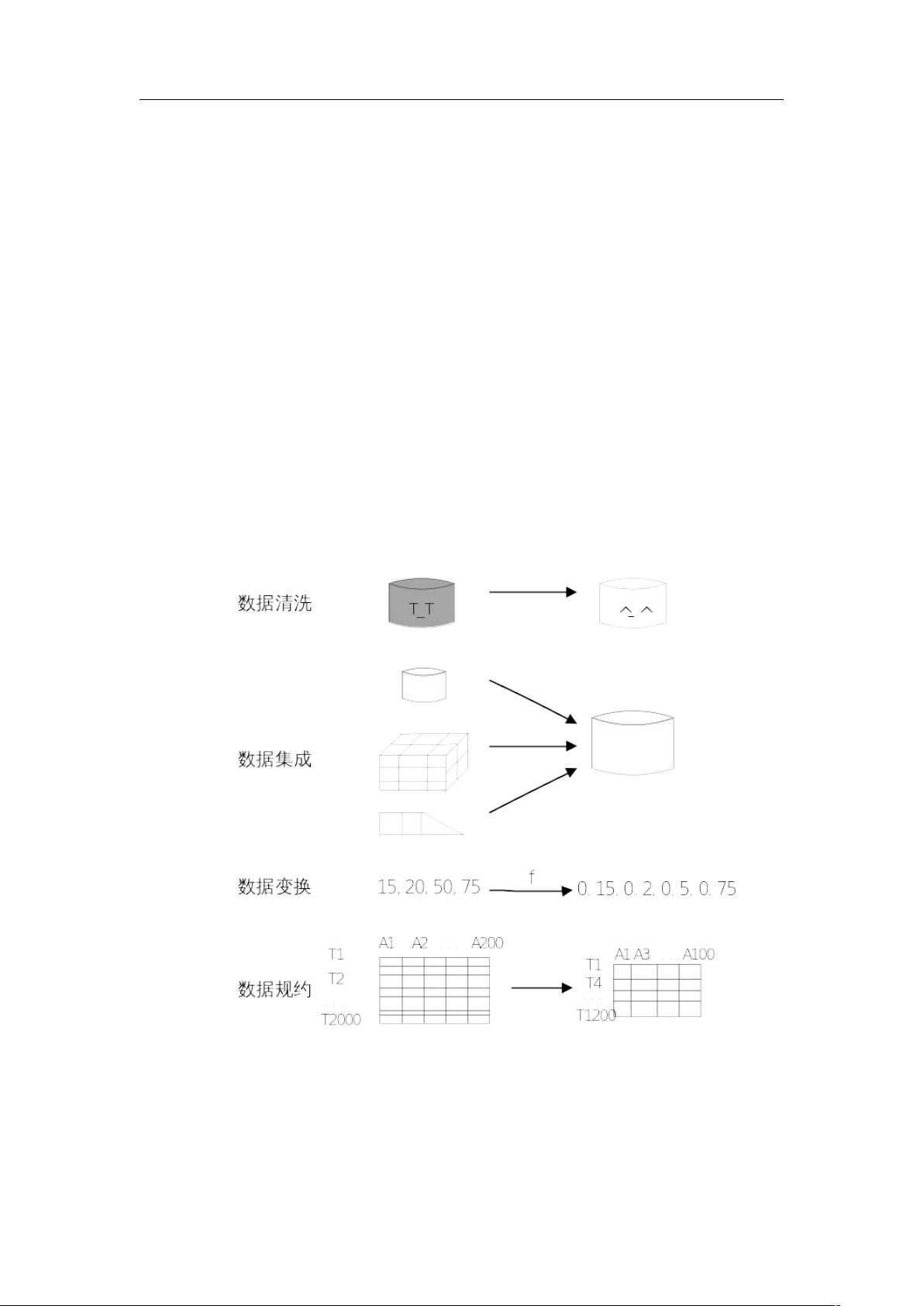
数据预处理的主要内容包括数据清洗,数据集成,数据变换和数据规约。处理过程如
图 7-1 所示。
图 7-1数据预处理过程示意图
47



剩余24页未读,继续阅读






评论0
最新资源