
《RapidMiner 数据分析与挖掘实战》第 7 章
47
第 7 章 数据预处理
在数据挖掘中,海量的原始数据中存在着大量不完整(有缺失值)、不一致、有异常的
数据,严重影响到数据挖掘建模的执行效率,甚至可能导致挖掘结果的偏差,所以进行数据
清洗就显得尤为重要,数据清洗完成后接着进行或者同时进行数据集成、转换、规约等一系
列的处理,该过程就是数据预处理。数据预处理一方面是要提高数据的质量,另一方面是要
让数据更好地适应特定的挖掘技术或工具。统计发现,在数据挖掘的过程中,数据预处理工
作量占到了整个过程的 60%。
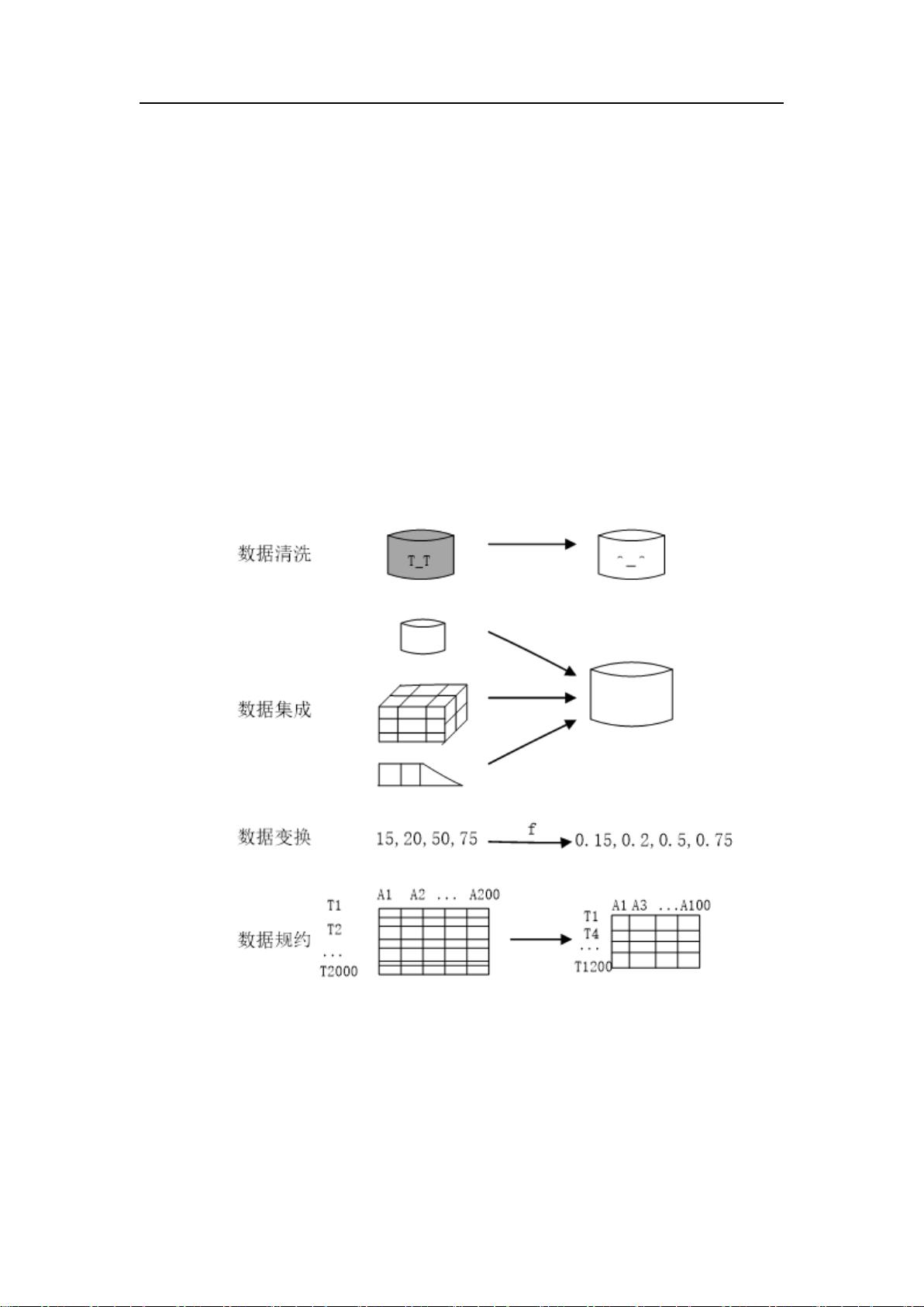
数据预处理的主要内容包括数据清洗,数据集成,数据变换和数据规约。处理过程如图
7-1 所示。
图 7- 1 数据预处理过程示意图
7.1 数据清洗
数据清洗主要是删除原始数据集中的无关数据、重复数据,平滑噪声数据,筛选掉与挖
掘主题无关的数据,处理缺失值、异常值等。



剩余22页未读,继续阅读
资源评论


passionSnail
- 粉丝: 475
- 资源: 7849

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
- comtrade录波文件格式详解-1999中文版
- inode for mac客户端,H3C
- Python 实现CSO-BP布谷鸟优化算法优化BP神经网络多输入单输出回归预测的详细项目实例(含完整的程序,GUI设计和代码详解)
- PFC-FLAC耦合断层模型简化版:球体与有限元层间交互的干货指南,PFC-FLAC耦合模型简化版:带有断层特性的有限元分析与实践教程,该模型是“PFC- FLAC耦合带有断层的模型”的简化版: 即p
- 2000-2022年上市公司人工智能水平数据/上市公司人工智能词频统计数据(年报词频统计).xlsx
- 基于DSP TMS320F28335的Matlab Simulink嵌入式模型:自动生成CCS工程代码实现永磁同步电机双闭环控制,基于Matlab Simulink开发的TMS320F28335芯片嵌
- Python 基于扩散因子搜索的GRNN广义回归神经网络时间序列预测的详细项目实例(含完整的程序,GUI设计和代码详解)
- Python 实现SA-ELM模拟退火算法优化极限学习机时间序列预测的详细项目实例(含完整的程序,GUI设计和代码详解)
- COMSOL模拟中考虑浆液粘度时变性的随机裂隙注浆过程:多孔介质与优势裂隙通道内的流变行为研究,COMSOL模拟浆液在多孔介质与裂隙中复杂流动行为的时变粘度特性研究,COMSOL注浆( 1coms
- Python 实现ELM极限学习机时间序列预测的详细项目实例(含完整的程序,GUI设计和代码详解)
- numpy-2.2.0-cp311-cp311-win32.whl
- VPet,虚拟宠物收集的资料
- 基于Comsol仿真模型的锂枝晶生长过程研究:多场耦合与C++程序模拟的元胞自动机法及LBM对流影响分析,基于Comsol仿真模型的锂枝晶生长过程研究:多场耦合与C++程序模拟的元胞自动机法及LBM对
- TMS320F28P550SJ9学习笔记5:结构体寄存器方式配置 LED
- MATLAB驱动直线电机创新应用:仿真示波器曲线与数据分析验证法效能,MATLAB直线电机仿真与数据验证:创新方法的有效证明及文档化展示,MATLAB直线电机创新点,通过仿真示波器的曲线或者数据能证
- linux与unix shell编程指南
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


