《基于模板的文字识别结果结构化处理技术》在线公开课主要探讨了如何通过模板匹配和深度学习技术,有效地将文字识别结果转化为结构化的数据,以便更好地服务于各类业务场景。以下是该课程涉及的主要知识点:
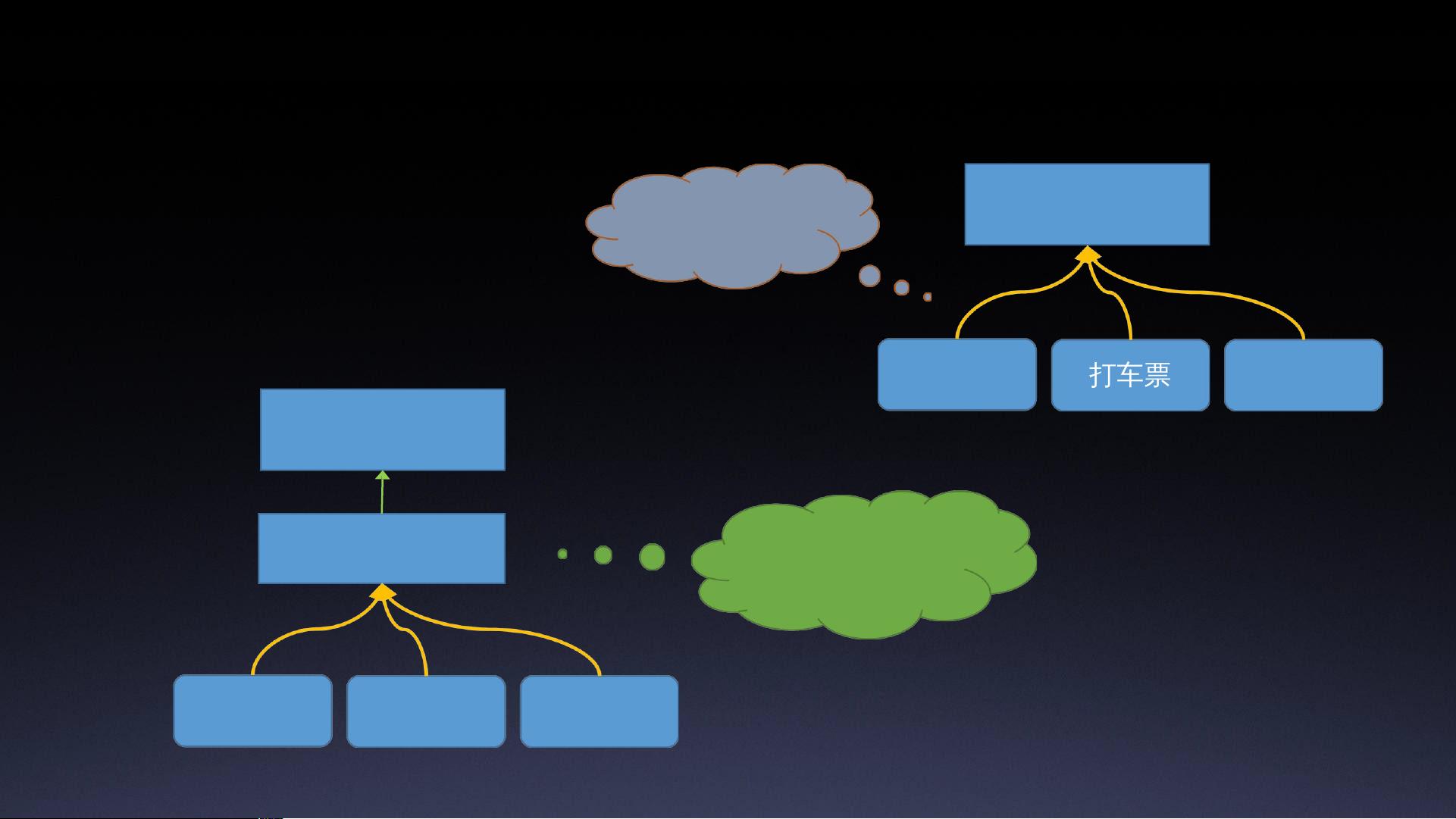
1. **文字识别行业现状**:当前的文字识别技术主要包括通用文字识别和专用垂类识别。通用文字识别能够识别各种文本,但输出结果通常是按行排列,缺乏结构化;而专用垂类识别则可以提供结构化的输出,适用于特定类型的文档如身份证、发票等,但训练成本高,周期长。
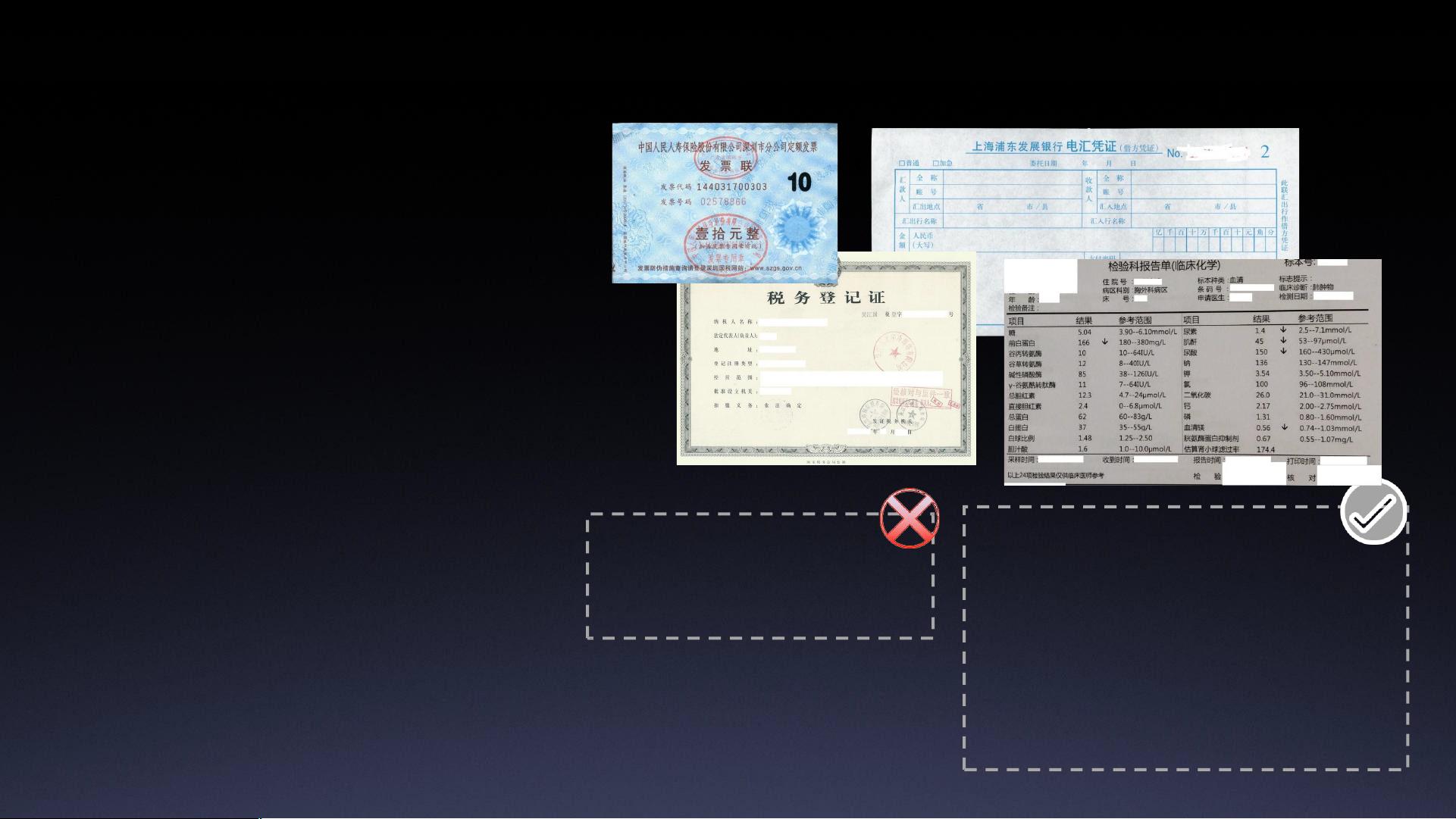
2. **基于模板的文字识别结构化方案**:通过预设的模板,可以对不同格式的单据进行结构化处理。这种方法首先需要将图片进行摆正,使其与模板对齐,然后进行文字识别和匹配,最终形成结构化数据。例如,发票识别中,将始发站、到达站、车次等关键信息提取出来,以键值对的形式表示。
3. **基于深度学习的文字识别**:深度学习模型,如 Faster R-CNN 和 CTPN,被用于文字检测和识别。Faster R-CNN 用于单字检测,将其视为物体检测任务;CTPN 则用于文本行检测,视作序列标注任务。这些模型能够提高文字识别的准确性。
4. **基于模板的图片摆正**:利用透视投影技术,找到图片中的参照字段,计算出最佳的透视投影矩阵,使待识别区域与模板尽可能对齐。此过程可能需要多次摆正,以达到最佳匹配度。
5. **多类型结构化**:面对多种类型的文档,如定额发票、电汇凭证等,需要进行模板分类。通过迁移学习,可以利用预训练的CNN模型,结合图像和文字特征,进行快速有效的分类。
6. **模板匹配和多次摆正**:计算匹配程度,如果一次摆正不够理想,则会积累多个透视投影矩阵,形成级联,通过不断调整,找到最接近模板的摆正结果。
7. **结构化识别结果**:固定识别区和表格识别区是结构化处理的关键。对于固定识别区,根据单字位置和待识别区的交并比确定归属;对于表格,自底向上构建,先列后行,以适应少量变形。
8. **模板分类**:利用迁移学习,将已训练好的模型应用于新的分类任务,减少训练数据量和时间。同时结合图像和文字特征,提升分类的准确性和效率。
这门课程详细讲解了如何利用模板和深度学习技术解决文字识别的结构化问题,旨在提高自动化处理文档和票据的能力,降低人工成本,提高工作效率。在实际应用中,这样的技术对于金融、医疗、行政等行业具有广泛的应用前景。