sas与聚类分析.pdf
版权申诉
23 浏览量
2022-11-13
18:06:23
上传
评论
收藏 923KB PDF 举报

1 聚类分析介绍
1.1 基本概念
聚类就是一种寻找数据之间一种内在结构的技术。聚类把全体数据实例组织
成一些相似组,而这些相似组被称作聚类。处于相同聚类中的数据实例彼此相同,
处于不同聚类中的实例彼此不同。聚类技术通常又被称为无监督学习,因为与监
督学习不同,在聚类中那些表示数据类别的分类或者分组信息是没有的。
通过上述表述,我们可以把聚类定义为将数据集中在某些方面具有相似性的
数据成员进行分类组织的过程。因此,聚类就是一些数据实例的集合,这个集合
中的元素彼此相似,但是它们都与其他聚类中的元素不同。在聚类的相关文献中,
一个数据实例有时又被称为对象,因为现实世界中的一个对象可以用数据实例来
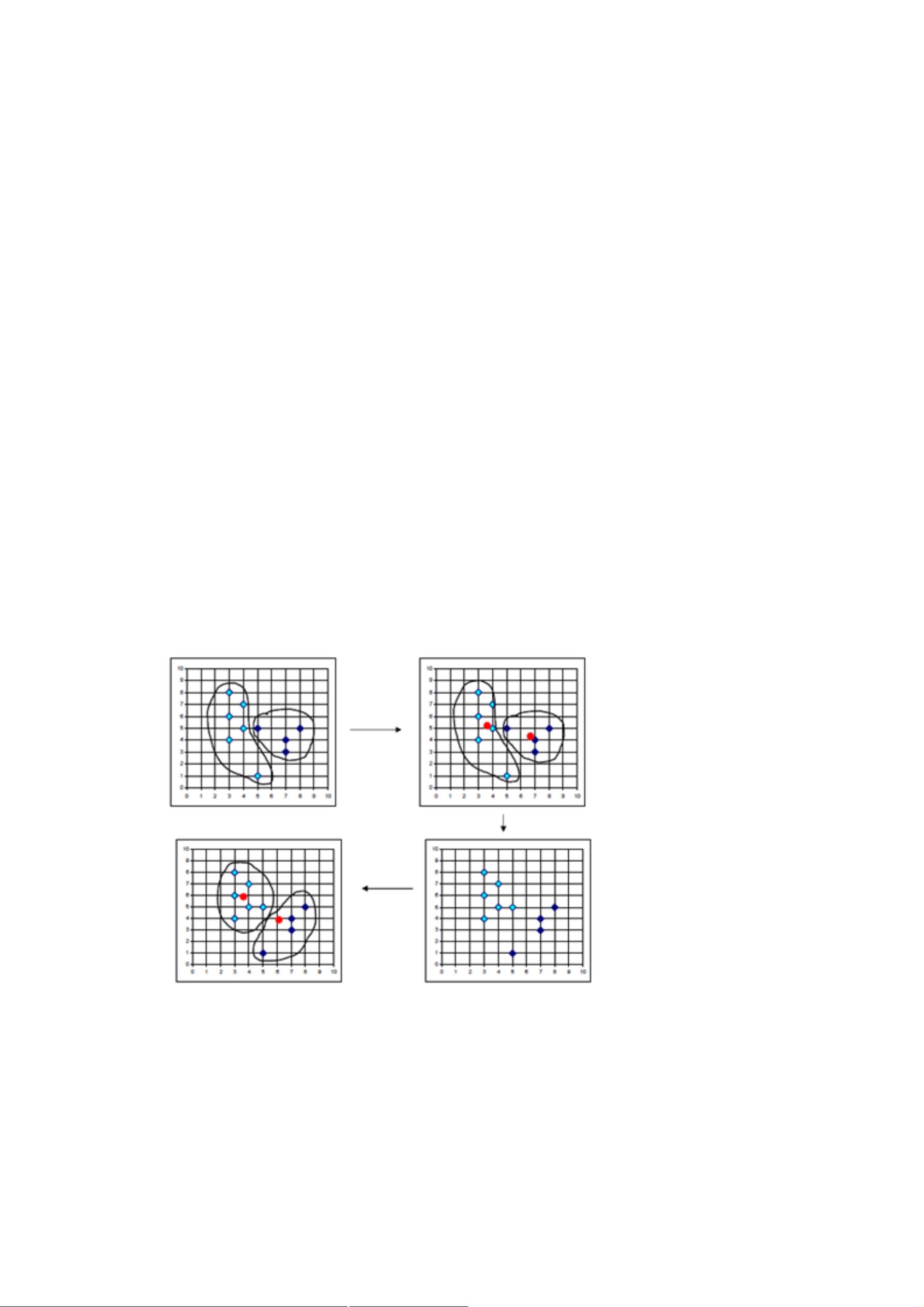
描述。同时,它有时也被称作数据点(Data Point),因为我们可以用 维空间
的一个点来表示数据实例,其中 表示数据的属性个数。下图显示了一个二维数
据集聚类过程,从该图中可以清楚地看到数据聚类过程。虽然通过目测可以十分
清晰地发现隐藏在二维或者三维的数据集中的聚类,但是随着数据集维数的不断
增加,就很难通过目测来观察甚至是不可能。
1.2 算法概述
目前在存在大量的聚类算法,算法的选择取决于数据的类型、聚类的目的和
具体应用。大体上,主要的聚类算法分为几大类。



剩余18页未读,继续阅读
资源评论


G11176593
- 粉丝: 6702
- 资源: 3万+











