实验二、聚类分析.pdf
版权申诉
169 浏览量
2021-10-12
14:50:02
上传
评论
收藏 466KB PDF 举报

实验二、聚类分析
一、实验目的
通过计算机编程实现并验证谱系聚类法的模式分类能力,了解和掌握最小距离归类
原则在模式识别中的重要作用与地位。
二、实验内容
1)用 C 或 Matlab 实现谱系聚类算法,并对给定的样本集进行分类;
2)通过改变实验参数,观察和分析影响谱系聚类算法的分类结果与收敛速度的因
素;
三、实验原理、方法和手段
人类认识世界往往首先将被认识的对象进行分类,聚类分析是研究分类问题的多元
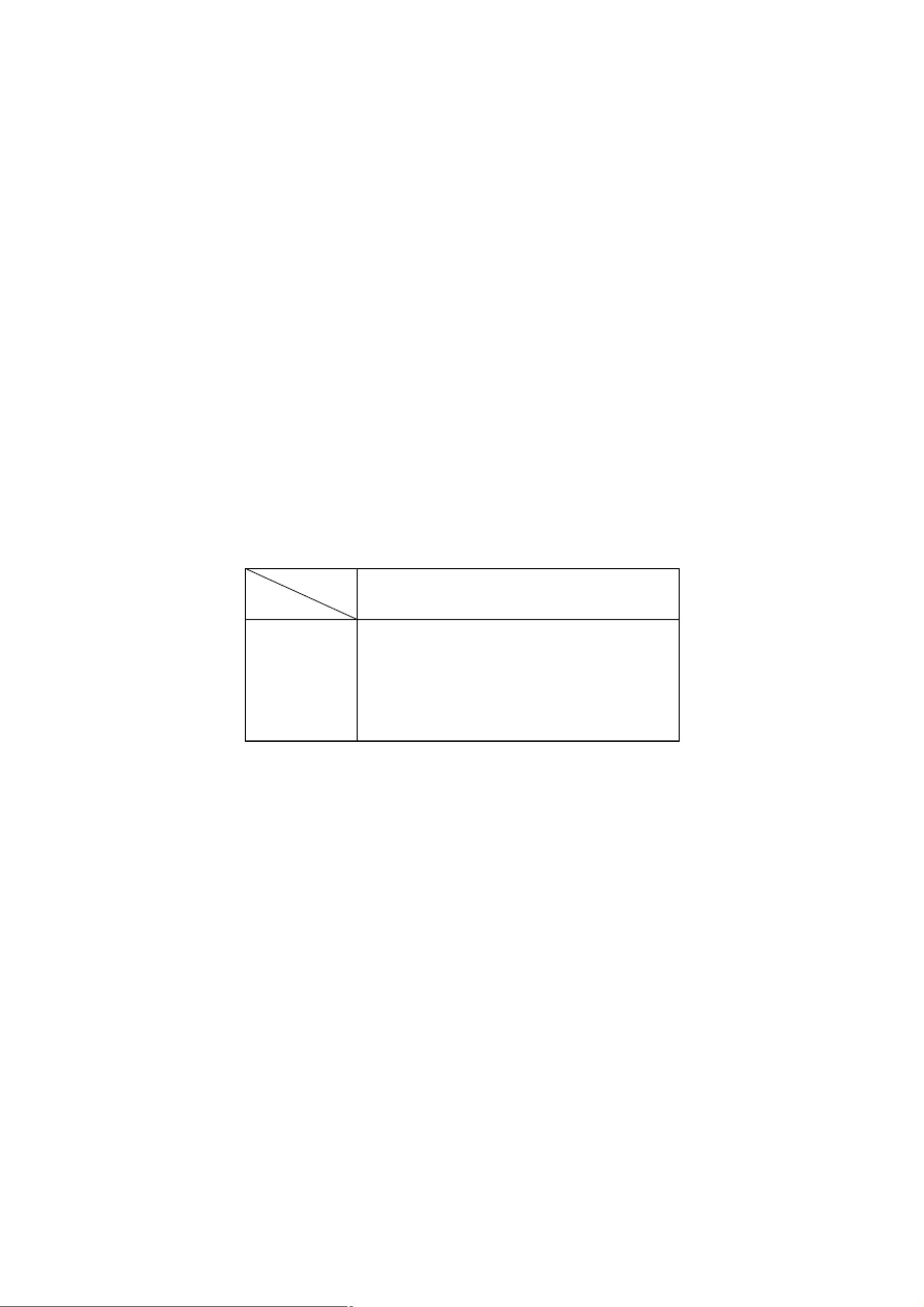
数据分析方法,是数值分类学中的一支。多元数据形成数据矩阵,见下表 1。在数据矩
阵中,共有 n 个样品 x
1
,x
2
,…,x
n
(列向),p 个指标(行向)。聚类分析有两种类型:
按样品聚类或按变量(指标)聚类。
表 1 数据矩阵
样品
x
1
, x
2
, ... , x
j
, ... , x
n
指标
x
1
x
2
x
p
x
11
x
21
x
22
x
2 p
...
...
...
x
j1
x
j 2
x
jp
...
...
...
x
n1
x
n2
x
np
x
12
x
1 p
聚类分析的基本思想是在样品之间定义距离,在变量之间定义相似系数,距离或相
似系数代表样品或变量之间的相似程度。按相似程度的大小,将样品(或变量)逐一归
类,关系密切的类聚到一个小的分类单位,然后逐步扩大,使得关系疏远的聚合到一个
大的分类单位,直到所有的样品(或变量)都聚集完毕,形成一个表示亲疏关系的谱系
图,依次按照某些要求对样品(或变量)进行分类。
⑴ 分类统计量----距离与相似系数
① 样品间的相似性度量----距离
用样品点之间的距离来衡量各样品之间的相似性程度(或靠近程度)。设
d( x
i
, x
j
)
是
样品
x
i
, x
j
之间的距离,一般要求它满足下列条件:
1) d(x
i
, x
j
) 0 , 且 d( x
i
, x
j
) 0 x
i
x
j
;
2) d( x
i
, x
j
) d( x
j
, x
i
) ;
3) d( x
i
, x
j
) d( x
i
, x
k
) d( x
k
, x
j
).
在聚类分析中,有些距离不满足 3),我们在广义的角度上仍称它为距离。
欧氏距离
1
资源评论













