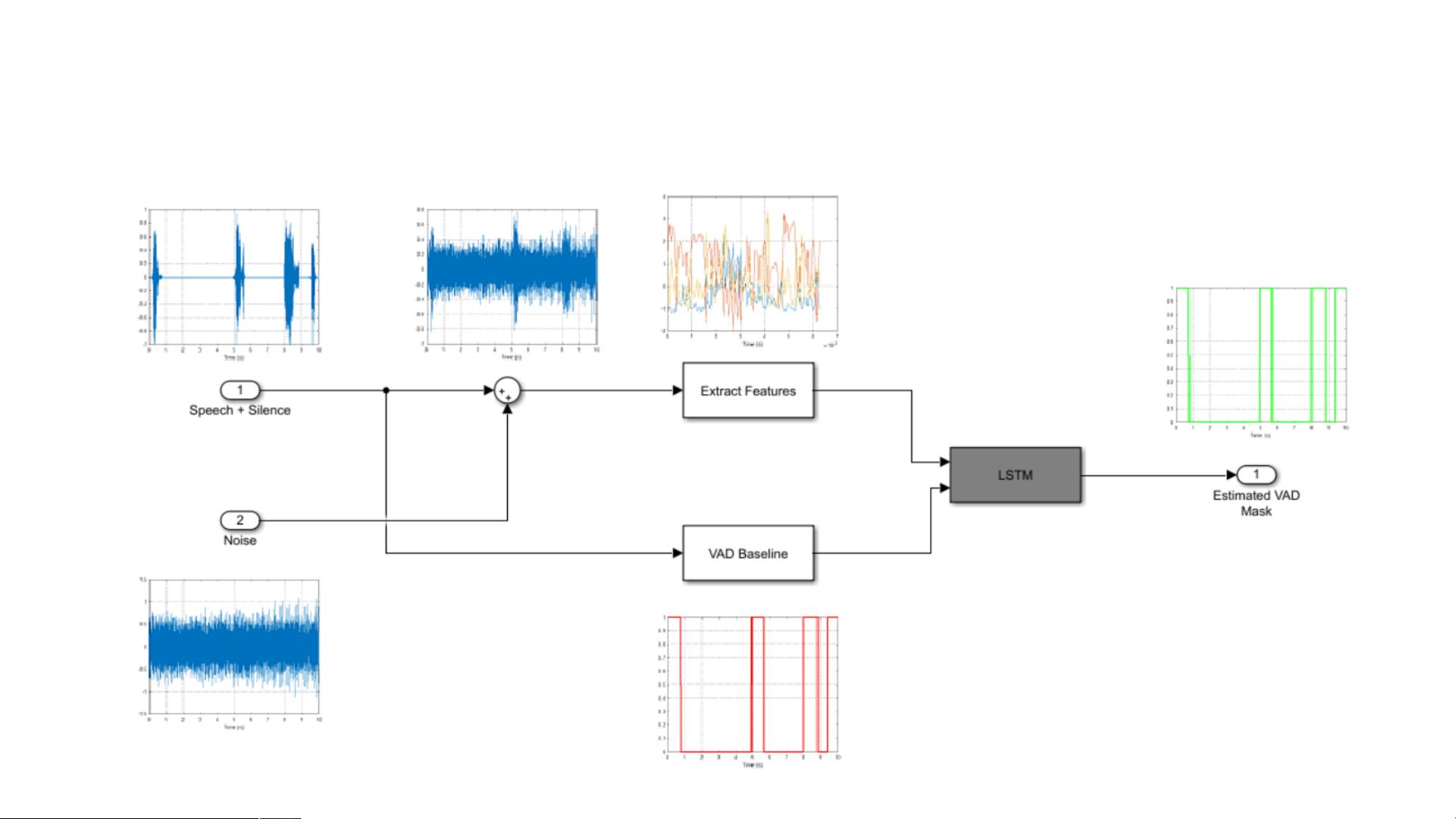
VOICE ACTIVITY DETECTION IN
NOISE USING DEEP LEARNING
Jigar Rajpopat
MMI 705 – Current Trends in Music Engineering I (1
st
December 2020)

 检测噪声中的语音活动的深度学习模型_matlab实现(包含完整源码+数据+项目说明).zip (7个子文件)
检测噪声中的语音活动的深度学习模型_matlab实现(包含完整源码+数据+项目说明).zip (7个子文件)  main.m 11KB helperFeatureVector2Sequence.m 926B main_mfcc.m 12KB main_reduce_batch_size.m 11KB
main.m 11KB helperFeatureVector2Sequence.m 926B main_mfcc.m 12KB main_reduce_batch_size.m 11KB 项目说明.txt 315B
项目说明.txt 315B fp_ML.pptx 14.6MB main_remove_layer.m 11KB
fp_ML.pptx 14.6MB main_remove_layer.m 11KB