

XAPP1052 (v3.2) September 29, 2011 www.xilinx.com 1
© Copyright 2008–2011 Xilinx, Inc. Xilinx, the Xilinx logo, Artix, ISE, Kintex, Spartan, Virtex, Zynq, and other designated brands included herein are trademarks of Xilinx in the
United States and other countries. PCI, PCIe, and PCI Express are trademarks of PCI-SIG and used under license. All other trademarks are the property of their respective
owners.
Summary This application note discusses how to design and implement a Bus Master design using
Xilinx® Endpoint PCI Express® solutions. A performance demonstration reference design
using Bus Mastering is included with this application note. The reference design can be used to
gauge achievable performance in various systems and act as a starting point for an application-
specific Bus Master Direct Memory Access (DMA). The reference design includes all files
necessary to target the Integrated Blocks for PCI Express on the Virtex®-6 and Spartan®-6
FPGAs, the Endpoint Block Plus Wrapper Core for PCI Express using the Virtex-5 FPGA
Integrated Block for PCI Express, and the Endpoint PIPE for PCI Express targeting the Xilinx
Spartan-3 family of devices. Also provided with the BMD hardware design is a kernel mode
driver for both Windows and Linux along with both a Windows 32-bit and Linux software
application. Source code is included for both Linux and Windows drivers and applications.
Note:
The BMD hardware design, software drivers, and applications are provided as is with no implied
warranty or support.
Overview The term Bus Master, used in the context of PCI Express, indicates the ability of a PCIe® port
to initiate PCIe transactions, typically Memory Read and Write transactions. The most common
application for Bus Mastering Endpoints is for DMA. DMA is a technique used for efficient
transfer of data to and from host CPU system memory. DMA implementations have many
advantages over standard programmed input/output (PIO) data transfers. PIO data transfers
are executed directly by the CPU and are typically limited to one (or in some cases two)
DWORDs at a time. For large data transfers, DMA implementations result in higher data
throughput because the DMA hardware engine is not limited to one or two DWORD transfers.
In addition, the DMA engine offloads the CPU from directly transferring the data, resulting in
better overall system performance through lower CPU utilization.
There are two basic types of DMA hardware implementations found in systems using PCI
Express: System DMA implementation and Bus Master DMA (BMD) implementation.
System DMA implementations typically consist of a shared DMA engine that resides in a
central location on the bus and can be used by any device that resides on the bus. System DMA
implementations are not commonly found anymore and very few root complexes and operating
systems support their use.
A BMD implementation is by far the most common type of DMA found in systems based on PCI
Express. BMD implementations reside within the Endpoint device and are called Bus Masters
because they initiate the movement of data to (Memory Writes) and from (Memory Reads)
system memory.
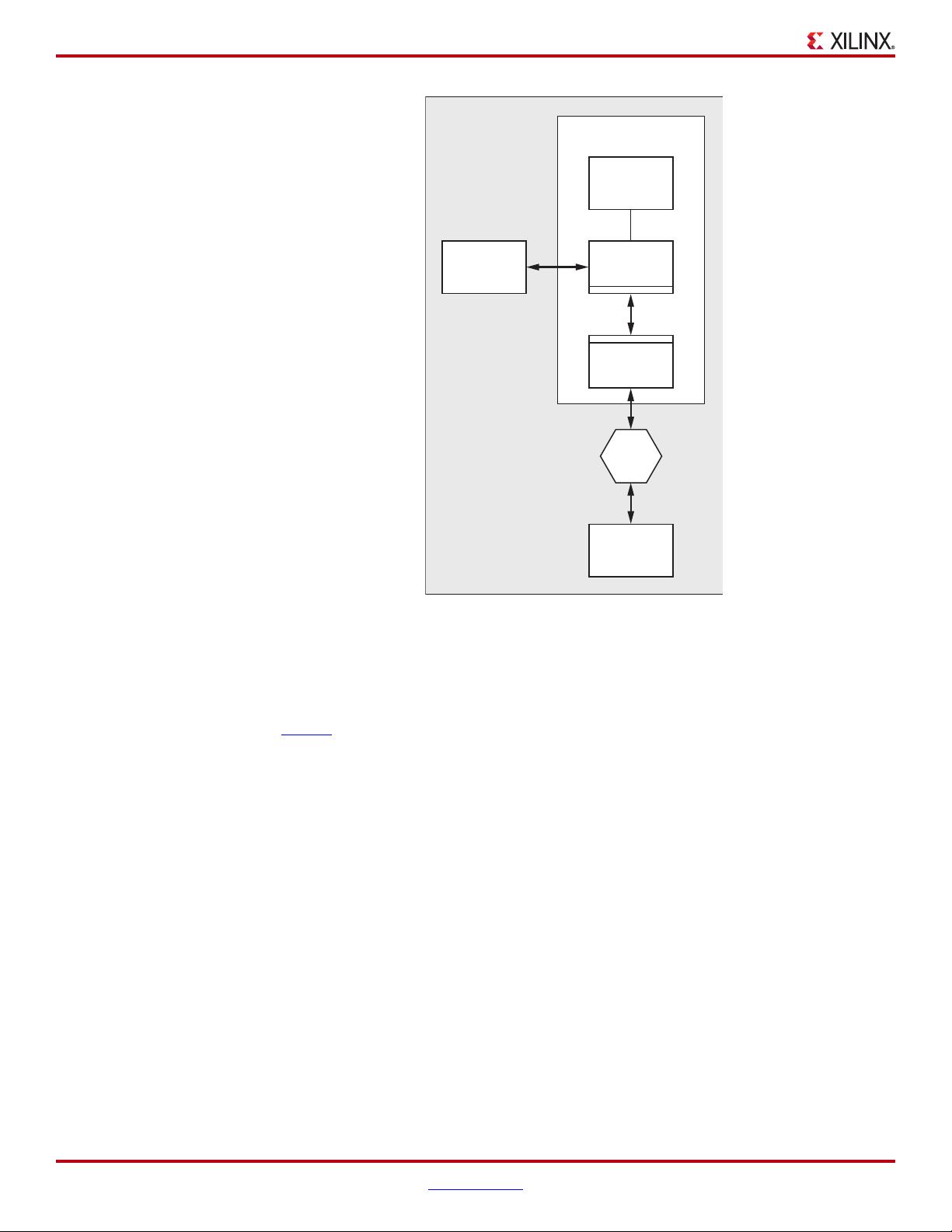
Figure 1 shows a typical system architecture that includes a root complex, PCI Express switch
device, and an integrated Endpoint block for PCI Express. A DMA transfer either transfers data
from an integrated Endpoint block for PCI Express buffer into system memory or from system
memory into the integrated Endpoint block for PCI Express buffer. Instead of the CPU having to
initiate the transactions needed to move the data, the BMD relieves the processor and allows
other processing activities to occur while the data is moved. The DMA request is always
initiated by the integrated Endpoint block for PCI Express after receiving instructions and buffer
location information from the application driver.
Application Note: Virtex-6, Virtex-5, Spartan-6 and Spartan-3 FPGA Families
XAPP1052 (v3.2) September 29, 2011
Bus Master Performance Demonstration
Reference Design for the Xilinx Endpoint
PCI Express Solutions
Author: Jake Wiltgen and John Ayer



剩余39页未读,继续阅读
资源评论













