融合互注意力机制与BERT的中文问答匹配技术研究.docx
版权申诉
101 浏览量
2022-06-18
11:27:28
上传
评论
收藏 290KB DOCX 举报


0 引言
问答匹配的基本定义是给定一个问题和对应的答案池 ,答案池中包含多个正
确答案和错误答案,最终可从答案池中找到最佳的候选答案集。
近些年来,基于深度神经 网 络 模型的问答匹 配模型应用愈 加 广 泛。 2015
年,FENG
[1
]
等人设计了 6 种卷积神经网络结构以及 8 种相似度度量函数,在保险领
域数据集上 Top-1 准确率达到 65.3%。2016 年,TAN
[2
]
等人将卷积神经网络、双
向长短期记忆网络以及注意力机制以不同的形式联合构成 4 个模型,Top-1 准确
率达到 69%。DOS
[3
]
等人提出了基于注意力池化的双向长短期记忆网络算法
(Attentive Pooling Bi-directional Long Short-Term Memory,AP-BiLSTM ),
该 算 法 在 双 向 长 短 期 记 忆 网 络 ( Bi-directional Long Short-Term
Memory,BiLSTM)输出的特征向量基础上,对问题和答案向量做双向的注意力机
制,使问题和答案进行充分的交互。LIU
[4
]
等人提出基于注意力的神经匹配模型
(Attention-Based Neural Matching Model,ANMM )算法,提出权值共享以及
基于问题的注意力机制来学习问题中每个词的重要性。 2017 年,TAY
[5
]
等人首次
提出采 用 全 息组合来模拟 问题和答案向 量 之 间的关系 , 参数量少且 性 能 优异
2018 年 ,TAY
[6
]
等 人 提 出 了 双 曲 空 间 词 嵌 入 问 答 匹 配 算 法 ( Hyperbolic
Embeddings Question Answering,HyperQA ),提出了将问答句的词嵌入映射
到双曲空间而不是欧式空间。WANG
[7
]
等人提出了将问句的每个时间步与答案句
的所有时间步以多重视角相匹配,从而使问答句在多种层面上产生交互。SHEN
[8
]
等人利用单词级相似度矩阵及软对齐注意力机制这两种新颖而有效的策略来明
确地计算每个单词的权重。2018 年,TAY
[9
]
等人将注意力机制看作特征提取器,采
用了多种注意力机制在 Ubuntu 数据集对话语料库上相比之前的模型效果提升了
9% 。 陈 柯 锦
[10
]
等 人 使 用 卷 积 神 经 网 络 ( Convolutional Neural
Networks,CNN)以及 LSTM 分别提取问题答案的多尺度特征 ,然后使用多种相
似度特征学习模型对多尺度特征聚合,得到联合相似度。2019 年,陈志豪
[11
]
等人
提出联合注意力机制和字嵌入医疗问答匹配模型,通过字嵌入可以解决医疗术语
难以分词的问题。2020 年,谢正文
[12
]
等人提出使用自注意力机制削弱单文本内部
的噪声词权重,同时使用互注意力机制捕捉问题答案句间更细粒度的交互特征,有
效削弱噪声词的影响。2021 年,张仰森
[13
]
等人提出一种分阶段式的注意力模型,
该模型关注问题的类别、关键词和问题的语义信息。
以上的问答匹配算法,大多是基于传统的神经网络对问题和答案进行语义特
征提取,但是传统的神经网络往往有一定的局限性 ,BiLSTM 虽然能兼顾文本词序
以及文本的长距离依赖特征,但随着信息量的增大仍然存在信息损失。针对传统
问答匹配模型对中文词向量表示不够精确,文本间交互特征提取不充分的问题,本
文 提 出 了 基 于 注 意 力 的 双 向 编 码 表 征 算 法 ( BERT-Bilstm-Attention,BERT-
BA)。
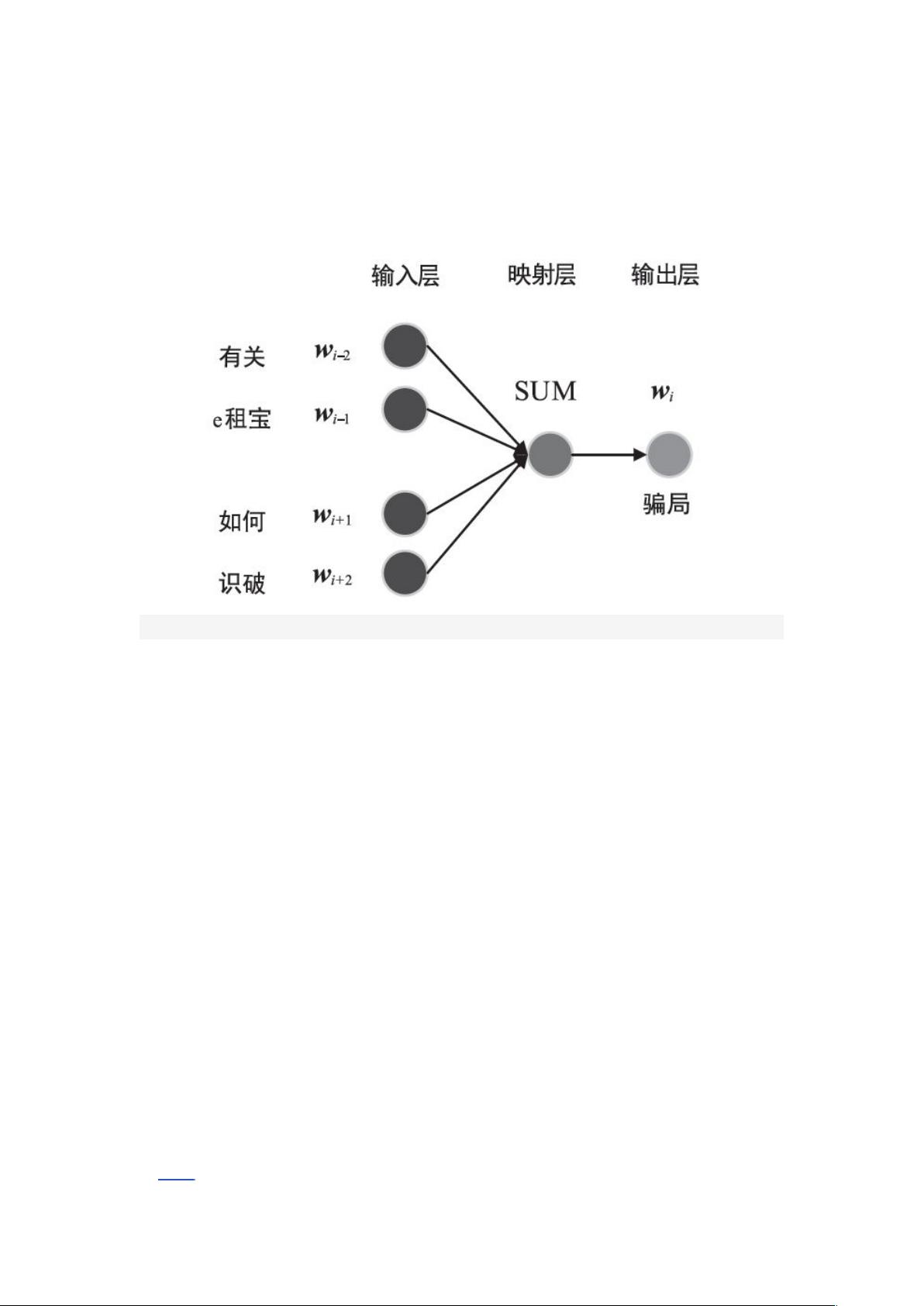
1 问答匹配模型架构

剩余10页未读,继续阅读
资源评论


罗伯特之技术屋
- 粉丝: 3652
- 资源: 1万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP











