基于改进BERT算法的专利实体抽取研究—以石墨烯为例.docx
版权申诉
21 浏览量
2022-12-15
14:22:46
上传
评论
收藏 442KB DOCX 举报


专利文档中含有大量作者所进行的创新性工作,这些内容所蕴含的知识代表先进技
术,对专利文档的分析可以获得专利所研究领域的技术及生产工艺发展情况。但是由于专
利文档数量的庞大性,如果每一篇都需要人工分析和信息提取的话,则工作量非常大,同
时也会受到操作者本身技术能力的影响,因此采用自动获取技术是专利分析的第一要素。
自然语言处理在近些年来成功应用到诸多文档处理相关领域,获得了显著效果。基于实体
关系的知识图谱技术也是采用符合人类社会模型认知的方式来深入挖掘实际事物之间的联
系,进而完成知识演进。专利文本中核心的文档主要是说明书和权利要求,这两部分包含
了专利的大多数信息,权利要求以科学术语定义该专利或专利申请所给予的保护范围。说
明书则是对发明或者实用新型的结构、技术要点、使用方法做出清晰、完整的介绍,它包
含了背景技术、发明内容、附图说明、具体实施方案等项目。本文将采用两种算法进行专
利信息的抽取,实现对专利文本中的核心涉及物及关键工艺的认知。
在专利知识抽取方面,国内有学者探索了基于规则、模板、机器学习、本体等多种抽
取的方法。文献[1]研究了专利摘要信息抽取的技术、步骤,结合词典、规则和统计模型方
法,针对隐马尔可夫标注算法进行了合理改进,在抽取结果处理上提出了一套技术关键词
识别模型及其算法。文献[2]提出了针对英文专利的,基于模板的自动获取方法。文献[3]提
出一个基于本体的中文专利摘要抽取模型。文献[4]在领域专利术语抽取的基础上,研究较
大规模术语层次关系的解析,构建了含有层次关系的领域知识本体。文献[5]研究了使用不
完备的语料库,在无人工参与的情况下,采用条件随机场的方法对字进行角色的标注,并
设计术语识别的模型,取得了较好的效果,从专利中抽取的知识可用于辅助技术或产品创
新。文献[6]研究了基于同义词群提取的技术特征,用于外观设计专利的分析。国外在专利
标注和知识抽取方面也有研究,文献[7]根据专利文档的结构和语义描述,对专利进行语义
标注,帮助生物学家更好的利用专利信息。文献[8]基于文档结构以及专利文档内容的语义
结构,利用自然语言和本体技术,对专利进行语义标注,便于对专利检索更好的分析。文
中还描述了专利分析人员分析过程中用到的一系列文本挖掘技术方案,包括文本切分、摘
要抽取、特征项选择、词语关联、聚类、主题识别和信息映射等。结果证明自动抽取的概
要相比其他片段更能表达原来的意思。这些技术有助于提高专利分析中用到的分类、组
织、知识分享和现有技术检索。文献[9]提出了一种基于语义要素统计和关键短语抽取的中
文专利挖掘方法,用于从中文专利文档中抽取关键短语。该抽取技术基于“HowNet”的语义
知识结构,利用统计的方法计算专利文档中的备选短语计算值。实验证明,该方法比单纯
的频次统计方法有更高的精确率和召回率。文献[10-11]介绍了一种词间关系抽取的方法,
结合模板和统计指标来抽取词间的两种类型的层次关系:“IS-A”和“PART-OF”。
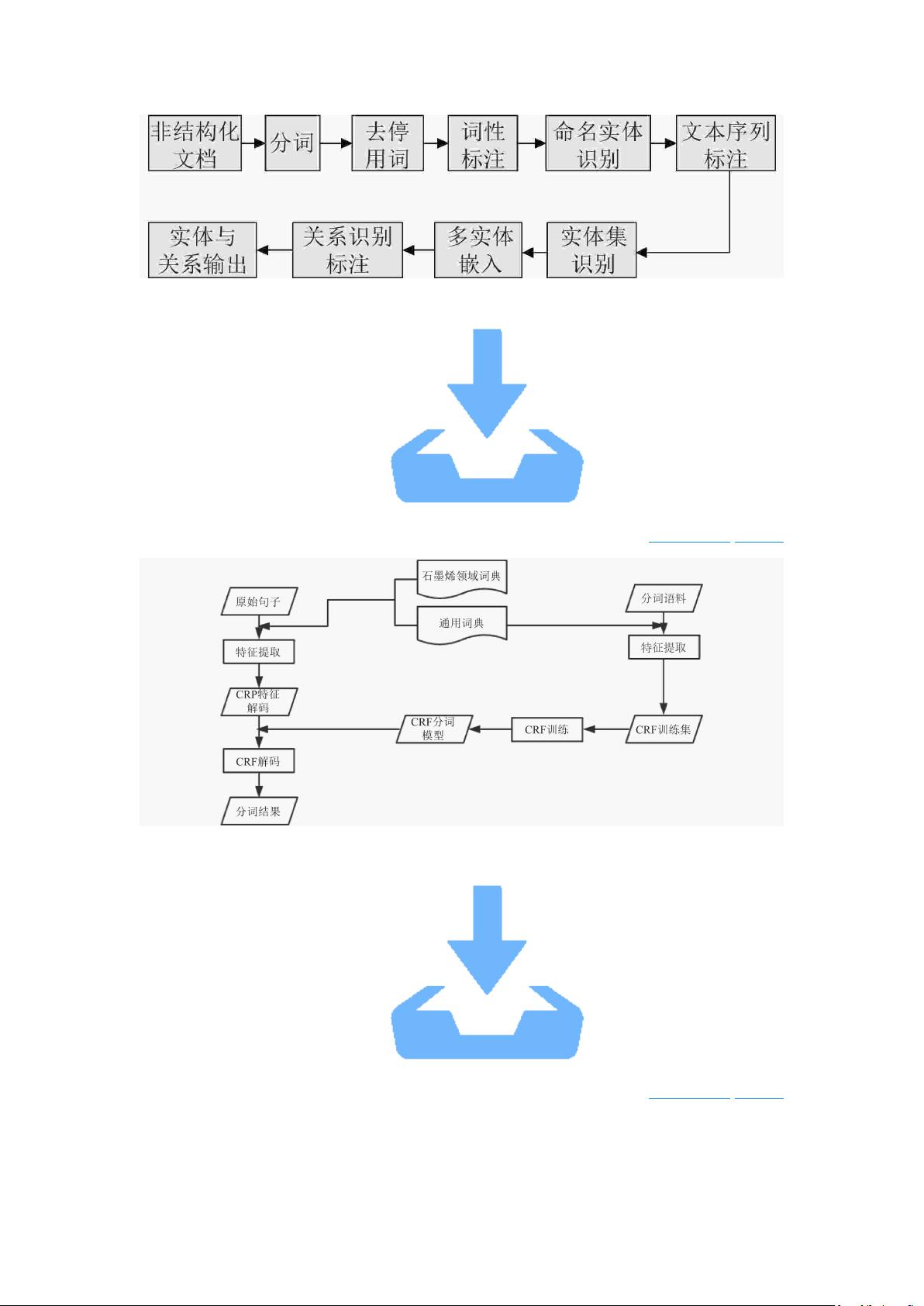
1. 经典实体信息抽取技术
1.1 专利实体及实体关系内容

剩余15页未读,继续阅读
资源评论


罗伯特之技术屋
- 粉丝: 3907
- 资源: 1万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP











