改进BERT的中文评论情感分类模型.docx
版权申诉
18 浏览量
2022-06-24
13:33:39
上传
评论
收藏 429KB DOCX 举报


0引言
近年来,深度学习在图像和语音处理领域取得显著进展
[1]
,然而在自然语言处理领域的研究中尚未取
得较大突破。情感分类是自然语言处理任务中的一个子任务,其本质上是对带有情感色彩的主观性文
本进行分析、处理、归纳和推理的过程,例如对电影和电视剧的评论、网购产品评价、微博微信等社
交平台在某一热点事件上的评论等。情感分析有助于使用者获得产品的客观评价并合理地进行舆情监
测,结合本国互联网电商和社交平台的迅速发展以及广大网民热衷于发表网络评论的国情,中文评论
情感分类研究具有重要意义。如何以深度学习网络为基础,构建高效的中文评论情感分类模型已经成
为中文评论情感分类研究的热点问题。
深度学习网络在情感分析方面常用到卷积神经网络(Convolutional Neural Network,CNN)和
循环神经网络(Recurrent Neural Networks,RNN)
[2]
,其中 RNN 是主流网络,因为 RNN 在当
前节点的输出值由当前时刻的输入和上一时刻的输出共同决定,这样使得 RNN 能够充分学习文本前
后文信息。在循环神经网络应用方面常见的是其变体 LSTM
[3]
(Long Short Term Memory),这
种变体可以学习长期依赖信息。GRU(Gated Recurrent Unity)是 LSTM 的一个变体,它进一步
减 少 了 LSTM 网 络 内 部 的 门结 构 , 提 高 了 网 络模 型 的 学 习 效 率 。 双 向循 环 神 经 网 络 BiLSTM
[4]
(Bidirectional Recurrent Neural Networks)和 BiGRU
[5]
(Bidirectional Gated Recurrent
Unity)通过建立双向网络连接,将文本从两个方向同时输入,使模型可以更充分地获取句子间的语
义信息,以这两种网络为基础的情感分类模型都取得了较好效果。
随 着 计 算 机 硬 件 的 发 展 , 一 些 网 络 结 构 更 深 、 更 复 杂 的 深 度 学 习 模 型 也 应 运 而 生 , BERT
[6]
(Bidirectional Encoder Representation from Transformers )就是其中的代表。它是一种基
于 Transformer 中的 Encoder 部分,通过在 Encoder 中引入 Masked Language Model 的预训
练 方 法 , 随 机 MASK 句 子 中 的 部分 Token , 然 后训 练 模 型 从 MASK 的 两 个 方 向预 测 被 去 掉 的
Token,同时借助 Encoder 中的多头注意力机制使模型能动态且并行地获取词向量,最后通过残差
连接和多个 Encoder 结构的堆叠,使模型能充分学习到文本的语义,从而产生较好的实验结果。本
文所用的 RoBERTa
[7]
(A Robustly Optimized BERT Pretraining Approach )模型是一种鲁棒
性更强的 BERT 模型,它主要优化了 MASK 策略,同时使用更大规模的数据训练模型,使模型适应性
更强,任务完成效果更好。
1相关工作
基于传统深度学习网络的情感分类模型在处理文本时不能直接处理文本信息,因为模型内部都是用来
处理数值的函数,其实验所用文本需要转化成词向量的形式,即先将文本转化成数值的形式再将其交
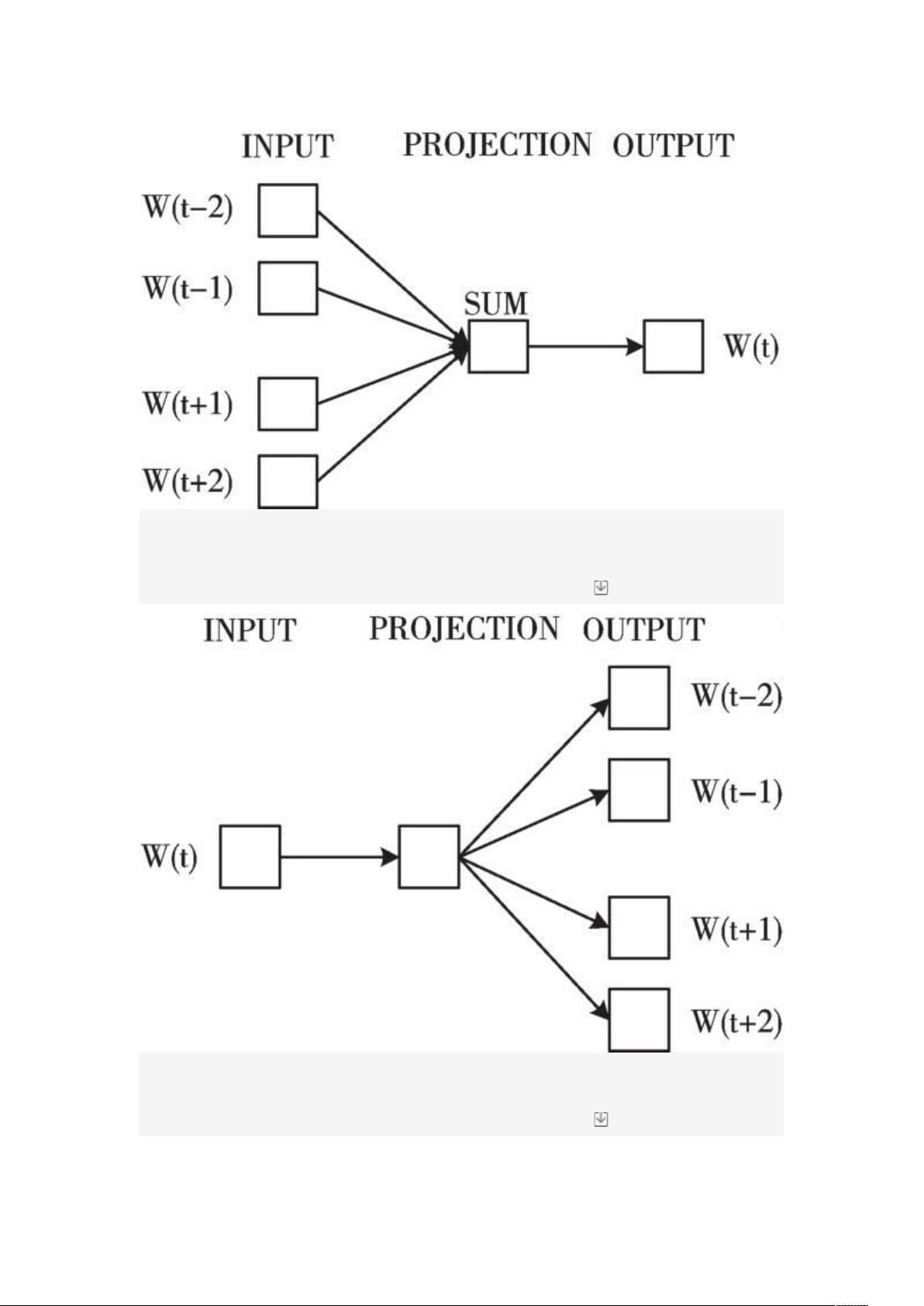
给所用网络作进一步任务处理,该过程也称为词嵌入。目前最流行的词嵌入模型就是 Word2Vec
[8]
,
它是一种有效创建词向量的方法,自 2013 年以来就一直存在。其原理的通俗解释就是将一个词放到
不同的维度标准中进行评分,每种评分代表其在这个维度的一个相似度,所用维度越多,词本身的特
点也就被挖掘得越充分。
在 Word2Vec 得到词向量的基础上,下游连接循环神经网络和 Softmax 层进行文本的情感分类是常
见的处理步骤。梁军等
[9]
在情感分析中引入 LSTM 网络,实现了比传统 RNN 更好的效果;任勉等
[10 ]
提出一种基于双向长短时记忆循环神经网络模型( BiLSTM),通过双向传播机制获取文本中完整的
上下文信息,比传统循环神经网络 LSTM 模型分类效果更好,能达到更高的召回率和准确率;吴小华
等
[11 ]
提出结合 Self-Attention
[12 ]
自注意力机制可以减少外部参数依赖,使模型能学到更多的文本自身
关键特征,解决了双向循环神经网络分类效果依赖分词正确率的问题,提高了分类效果;曹宇等
[13]
将
BiGRU 应用于中文情感分类,模型训练速度比 BiLSTM 快 1.36 倍,并且取得了较高的 F1 值;王伟
等
[14 ]
提出自注意力机制与双向 GRU 结合的 BiGRU-attention 的文本情感分类模型,实现了相较于
BiLSTM-attention 更高的正确率,同时模型训练时间也有效缩短;胡朝举等
[15]
提出一种基于深层注

剩余14页未读,继续阅读
资源评论


罗伯特之技术屋
- 粉丝: 3691
- 资源: 1万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP











