
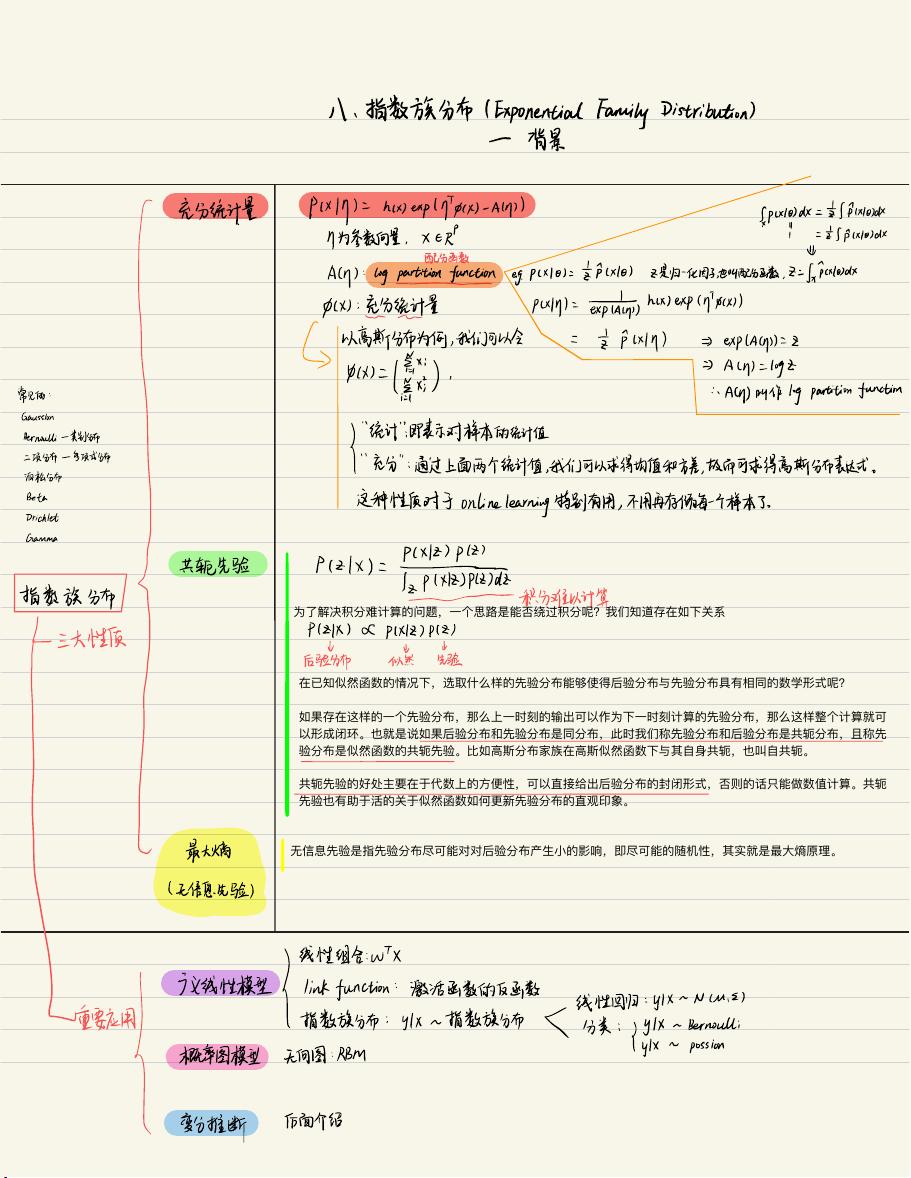
为了解决积分难计算的问题,⼀个思路是能否绕过积分呢?我们知道存在如下关系
在已知似然函数的情况下,选取什么样的先验分布能够使得后验分布与先验分布具有相同的数学形式呢?
如果存在这样的⼀个先验分布,那么上⼀时刻的输出可以作为下⼀时刻计算的先验分布,那么这样整个计算就可
以形成闭环。也就是说如果后验分布和先验分布是同分布,此时我们称先验分布和后验分布是共轭分布,且称先
验分布是似然函数的共轭先验。⽐如⾼斯分布家族在⾼斯似然函数下与其⾃身共轭,也叫⾃共轭。
共轭先验的好处主要在于代数上的⽅便性,可以直接给出后验分布的封闭形式,否则的话只能做数值计算。共轭
先验也有助于活的关于似然函数如何更新先验分布的直观印象。
⽆信息先验是指先验分布尽可能对对后验分布产⽣⼩的影响,即尽可能的随机性,其实就是最⼤熵原理。
⼋、
指数
族
分布
IExponentialF amigDistributi.nl
-
背景
充分
统计
量
以
1
7
)
⼆
hhpl
忤
化
)
-
A
1
7
"
他
⽐
1
0
)
𣏴
形成
1
0
⽐
⼀
川
为
参数
向量
,
XERP
1
-
1
⽉
⽐
1
0
)
⽐配
分
函数
业
A
(
7
)
:
hgparttnf-g.PL
ㄨ
1
0
1
⼆胡
⽐
1
0
)
⼜
是
归
化
因⼦
,
也
叫
配
分
函数
,
2
我
应
⼼
⽐
灿
:
炁
分
焦
计量
pcxlgke xp .ly
⼼
城
们
㶭
↳
以
⾼
斯
分布
为
何
,
我们
可
上
⼆
⽖
⼆⽉
⽐
1715
唙
州
》
=
2
1
0
以上
(
Ěì
A
以
⼆
192
常⻅的
:
点
砂
'
i
M
)
叫作
lgpartitonfunctim
䲜
湖
怖
|
统
试
即
表示
对
样本
的
统计
值
1
⼀项
分布
⼀
多项式
分布
I
"
充分
"
:
通过
上⾯
两个
统计
值
,
我们
可以
求得
均值
和
⽅差
,
故⽽
可
求
得
⾼
斯
分布
表达式
。
泊松分布
Beta
这种
性质
对于
onhneleamig
特别
有⽤
,
不⽤
再
存储
每个
样本
了
。
𡆇
ālii
:
鬣
𧅤
煍
"
I.
䆐
𠠬
-_-
线性
组合
nix
⼴义
线性
模型
中
liwkfunctioni
激活
函数
的
反
函数
重
鞻
概率
图
模型
䨻
䰞
"
以
指数
族
分布
下
㼂
管
器
戀
!
变
分
推断
后⾯
介绍

我要WhatYouNeed
- 粉丝: 48
- 资源: 287









最新资源
- DBCHM-oracle
- gitee_cli-git
- UnetCD-unet
- selenium-selenium
- xdoj-frontend-xdoj
- mindrl-强化学习
- 永磁同步电机三闭环控制Simulink仿真 电流内环 转速 位置外环 参数已经调好 原理与双闭环类似 有资料,仿真
- 元胞自动机机模拟城镇开发边界(UGB)增长 确定其组成的主要元素:元胞、元胞空间、元胞状态、元胞邻域及转变规则 分析模拟城市空间结构;确定模型的参数:繁殖参数、扩散参数、传播参数及受规划约束参数,C
- Maxwell和Simplorer联合仿真-永磁同步电机SVPWM控制 本仿真用AnsysEM实现永磁同步电机(PMSM)的仿真模拟,控制方式采用空间矢量控制,闭环方式采用电流环速度环双闭环控制
- KalmanFilterer-卡尔曼滤波
- 感应电机故障检测 Matlab simulink仿真搭建,附赠参考文献 提供以下帮助 波形纪录 参考文献 仿真文件 原理解释 仿真原理结构和整体框图
- 正弦波高频注入仿真模型
- 微环谐振腔的光学频率梳matlab仿真 微腔光频梳仿真 包括求解LLE方程(Lugiato-Lefever equation)实现微环中的光频梳,同时考虑了色散,克尔非线性,外部泵浦等因素,具有可延展
- hpwf-pycharm配置python环境
- DB-Docker-rabbitmq
- 考虑寿命损耗的微网电池储能容量优化配置 关键词:两阶段鲁棒优化 KKT条件 CCG算法 寿命损耗 风电、光伏、储能以及燃气轮机 微网中电源 储能容量优化配置 matlab代码 参考文档: 1
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0