机器学习常用算法公式推导与分析1
需积分: 0 59 浏览量
2022-08-08
22:45:39
上传
评论
收藏 3.9MB DOCX 举报


1.PCA 降维的公式及原理分析:
假设对称矩阵 A 的所有特征值都不一样,那么:
A
=
U
∧
𝑈
𝑇
-> 对角矩阵
∧
=
𝑈
𝑇
𝐴𝑈
对于矩阵 Y,它的协方差
𝐶
𝑌
=
1
𝑛
𝑌
𝑌
𝑇
假设 Y=QX(此时不考虑降维),则
𝐶
𝑌
=
1
𝑛
𝑄𝑋
(𝑄𝑋)
𝑇
=
1
𝑛
𝑄𝑋
𝑋
𝑇
𝑄
𝑇
=
Q
𝐶
𝑥
𝑄
𝑇
PCA 的本质:让协方差最小,方差最大,这样可以去相关 -> 协方差矩阵的对角元最大,非
对角元为 0->对角矩阵满足
我们已经得到两个公式:
𝐶
𝑌
=
Q
𝐶
𝑥
𝑄
𝑇
和
∧
=
𝑈
𝑇
𝐴𝑈
,假设 Q =
𝑈
𝑇
可以得到:
𝐶
𝑌
=
𝑈
𝑇
𝐶
𝑥
𝑈
,因为协方差矩阵
𝐶
𝑥
是对称半正定矩阵(特征值>=0)
所以可以得到:当 Q =
𝑈
𝑇
时,
𝐶
𝑌
是对角矩阵,因此如果 Q 少取几行就实现了降维
2.极大似然估计公式及原理分析:
极大似然估计起源于贝叶斯
假设特征为 D,标签为 A,P 为概率
贝叶斯公式为:P(A|D) =
𝑃(𝐷|𝐴)𝑃(𝐴)
𝑃(𝐷)
当样本给定的时候 P(D)为常量,同时假定先验概率 P(A)是符合正态分布的,那么我们可以
得到:
P(A|D) 是正比于 P(D|A),其中 P(D|A)就是极大似然函数
对于机器学习的意义:将已知特征求标签的概率转化为已知标签求特征的概率,从无监督问
题变成了有监督问题
但是极大似然的最大问题是:不同参数的 P(A)不一定是相等的,只能说在样本不够大的时
候是近似相等的
贝叶斯算法考虑了先验概率 P(A),但同时要求先验概率要准确
极大似然的两个假设:
1. 已经发生的事件是独立重复事件,符合同一分布
2. 已经发生的事件是可能性(似然)最大的事件
3.模型调优
1. 过拟合:找更多的数据来学习,增大正则化系数,减少特征个数(不一定有效)
2. 欠拟合:找更多的特征,减少正则化系数
3. 权重分析:特征对最后结果的影响
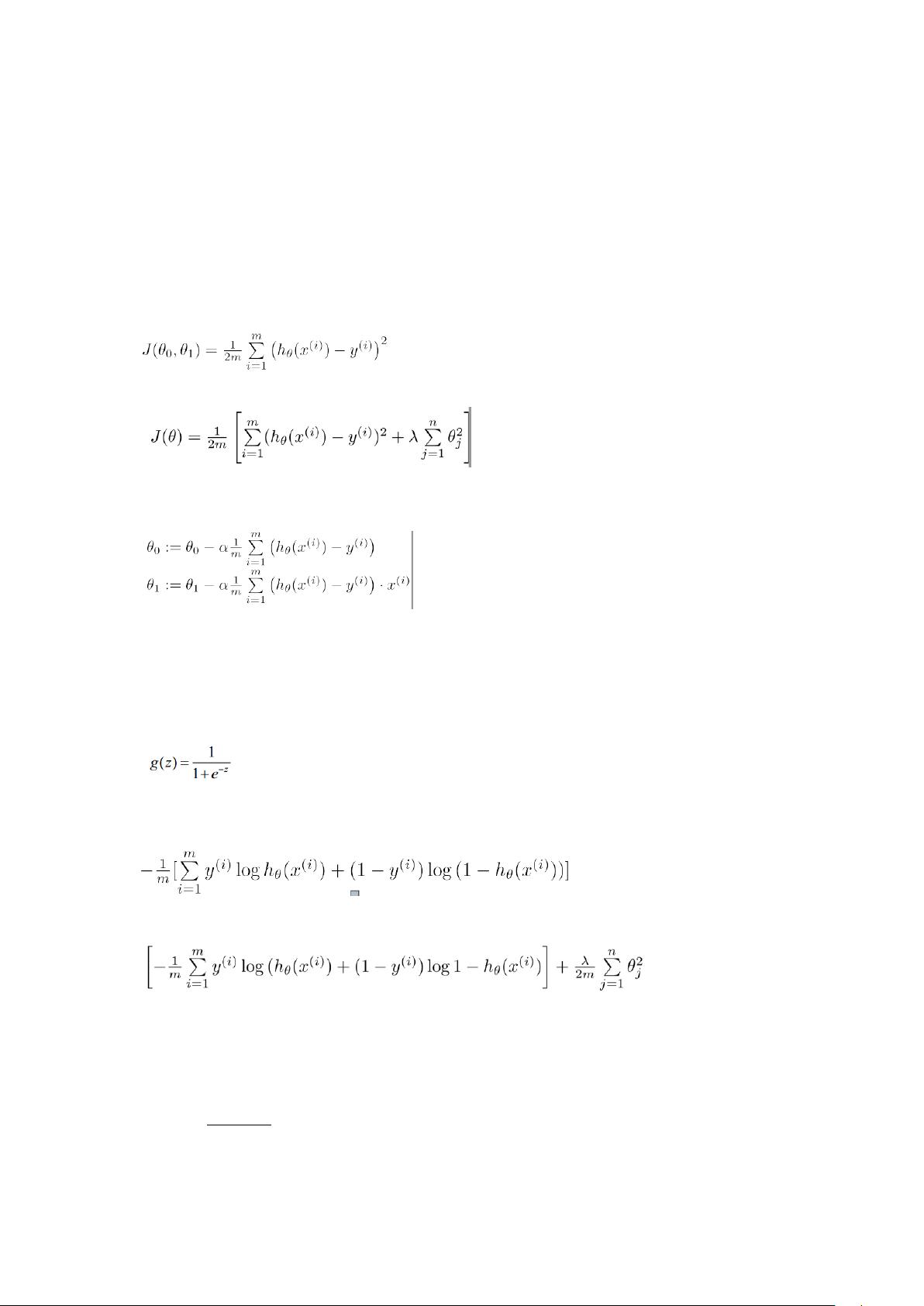

剩余17页未读,继续阅读













评论0