

系统辨识基础 第 4 讲
第 2 章 随机信号的描述与分析
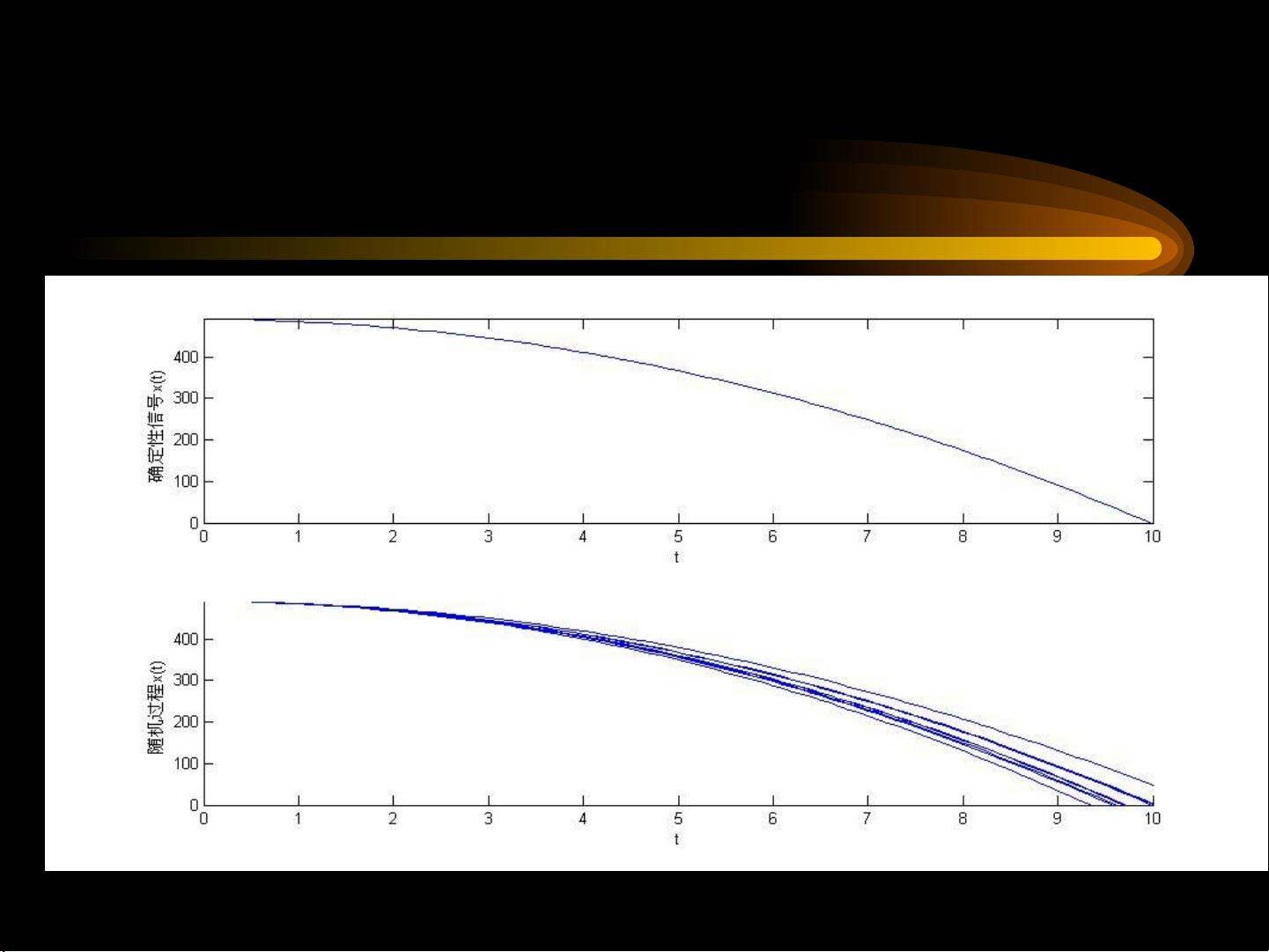
2.1 随机过程的基本概念及其数学描述(第 4
讲)
2.2 谱密度函数(第 4 讲)
2.3 线性过程在随机输入下的响应(第 5 讲)
2.4 白噪声及其产生方法(书 2.5 )(第 5 讲)
2.5 M 序列的产生及其性质(书 2.6 ) ( 第 6 讲 )



剩余63页未读,继续阅读
资源评论


ok272733314
- 粉丝: 1
- 资源: 15









最新资源
- 嵌入式第二课 GPIO口的认识与使用
- 焊丝送丝设备sw18全套技术资料100%好用.zip
- 计算机网络校园网课程设计
- Cisco-300-410.pdf
- 回旋提升式柔性链输送机sw16可编辑全套技术资料100%好用.zip
- 机加工磨床sw16可编辑全套技术资料100%好用.zip
- website-fgmalatest.zip
- 奖牌徽章边角自动打磨机_x_t全套技术资料100%好用.zip
- 鸡蛋自动分配机sw19全套技术资料100%好用.zip
- 激光打标+视觉贴标+视觉装夹扣生产线x_t全套技术资料100%好用.zip
- 精密电子切割机sw17全套技术资料100%好用.zip
- 武汉理工大学通信原理课程设计(2ASK抗噪声性能分析matlab代码)
- 计算机网络校园网课程设计
- 中国空间站的发展历史学习空间站知识宣传介绍PPT.pptx
- 计算机网络校园网课程设计
- 面向一年级的航天知识及我国航天发展科普
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


