YOLOv9: Learning What You Want to Learn
Using Programmable Gradient Information
Chien-Yao Wang
1,2
, I-Hau Yeh
2
, and Hong-Yuan Mark Liao
1,2,3
1
Institute of Information Science, Academia Sinica, Taiwan
2
National Taipei University of Technology, Taiwan
3
Department of Information and Computer Engineering, Chung Yuan Christian University, Taiwan
kinyiu@iis.sinica.edu.tw, ihyeh@emc.com.tw, and liao@iis.sinica.edu.tw
Abstract
Today’s deep learning methods focus on how to design
the most appropriate objective functions so that the pre-
diction results of the model can be closest to the ground
truth. Meanwhile, an appropriate architecture that can
facilitate acquisition of enough information for prediction
has to be designed. Existing methods ignore a fact that
when input data undergoes layer-by-layer feature extrac-
tion and spatial transformation, large amount of informa-
tion will be lost. This paper will delve into the important is-
sues of data loss when data is transmitted through deep net-
works, namely information bottleneck and reversible func-
tions. We proposed the concept of programmable gradi-
ent information (PGI) to cope with the various changes
required by deep networks to achieve multiple objectives.
PGI can provide complete input information for the tar-
get task to calculate objective function, so that reliable
gradient information can be obtained to update network
weights. In addition, a new lightweight network architec-
ture – Generalized Efficient Layer Aggregation Network
(GELAN), based on gradient path planning is designed.
GELAN’s architecture confirms that PGI has gained su-
perior results on lightweight models. We verified the pro-
posed GELAN and PGI on MS COCO dataset based ob-
ject detection. The results show that GELAN only uses
conventional convolution operators to achieve better pa-
rameter utilization than the state-of-the-art methods devel-
oped based on depth-wise convolution. PGI can be used
for variety of models from lightweight to large. It can be
used to obtain complete information, so that train-from-
scratch models can achieve better results than state-of-the-
art models pre-trained using large datasets, the compari-
son results are shown in Figure 1. The source codes are at:
https://github.com/WongKinYiu/yolov9.
1. Introduction
Deep learning-based models have demonstrated far bet-
ter performance than past artificial intelligence systems in
various fields, such as computer vision, language process-
ing, and speech recognition. In recent years, researchers
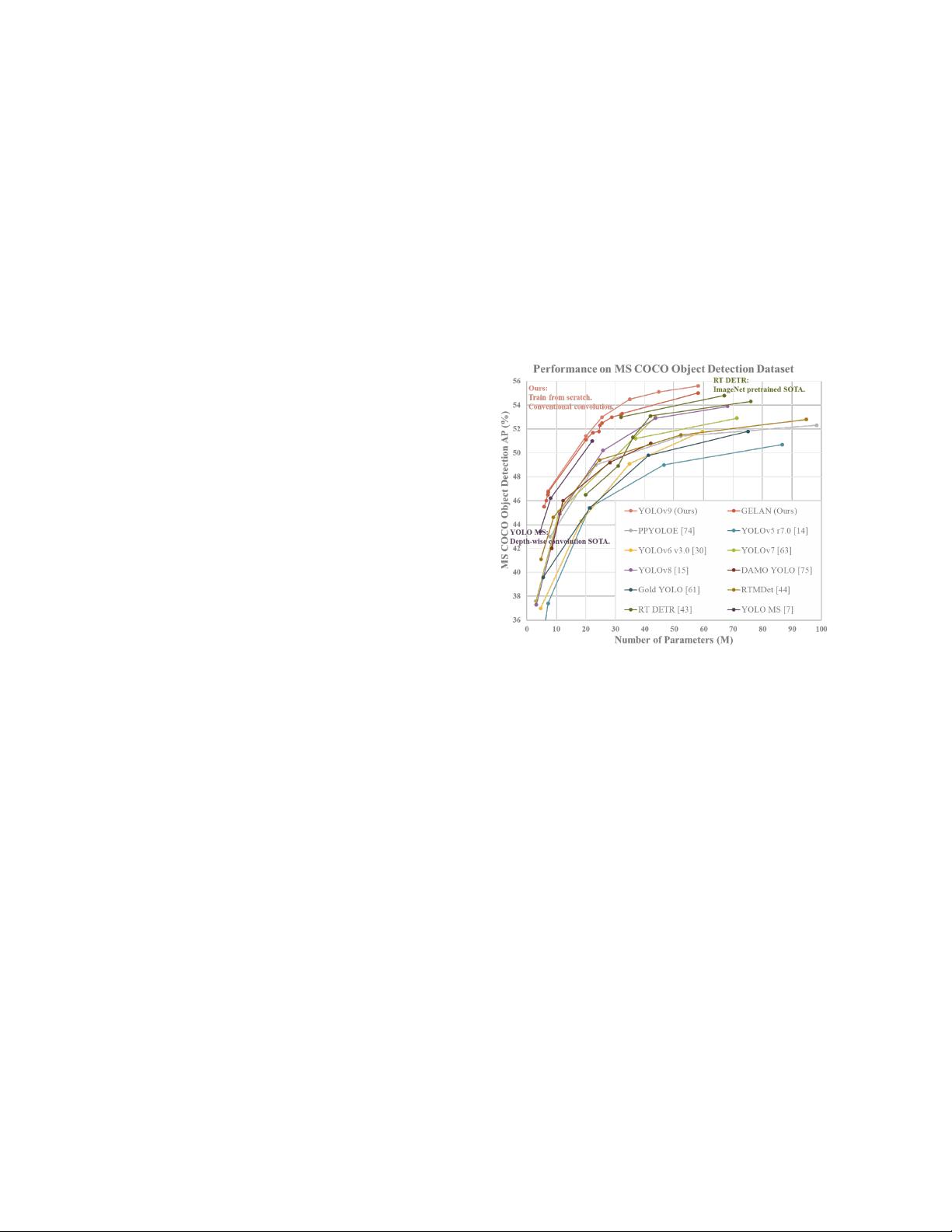
Figure 1. Comparisons of the real-time object detecors on MS
COCO dataset. The GELAN and PGI-based object detection
method surpassed all previous train-from-scratch methods in terms
of object detection performance. In terms of accuracy, the new
method outperforms RT DETR [43] pre-trained with a large
dataset, and it also outperforms depth-wise convolution-based de-
sign YOLO MS [7] in terms of parameters utilization.
in the field of deep learning have mainly focused on how
to develop more powerful system architectures and learn-
ing methods, such as CNNs [21–23, 42, 55, 71, 72], Trans-
formers [8, 9, 40, 41, 60, 69, 70], Perceivers [26, 26, 32, 52,
56, 81, 81], and Mambas [17, 38, 80]. In addition, some
researchers have tried to develop more general objective
functions, such as loss function [5, 45, 46, 50, 77, 78], la-
bel assignment [10, 12, 33, 67, 79] and auxiliary supervi-
sion [18, 20, 24, 28, 29, 51, 54, 68, 76]. The above studies
all try to precisely find the mapping between input and tar-
get tasks. However, most past approaches have ignored that
input data may have a non-negligible amount of informa-
tion loss during the feedforward process. This loss of in-
formation can lead to biased gradient flows, which are sub-
sequently used to update the model. The above problems
can result in deep networks to establish incorrect associa-
tions between targets and inputs, causing the trained model
to produce incorrect predictions.
1
arXiv:2402.13616v1 [cs.CV] 21 Feb 2024