

下面是一个基于 TensorFlow 2.0 的-2 中文训练教程,帮助您训练出自
己的中文 GPT-2 模型。请注意,该教程需要一定程度的 Python 编程经
验和机器学习知识。
.
准备工作
.
在开始训练之前,需要准备以下工具和库:
�
TensorFlow 2.0 或更高版本
�
�
Python 3.6 或更高版本
�
�
BPE 中文分词库
�
�
huggingface/transformers 库
�
 chatgptGPT3训练-gpt文本生成模型.zip (1个子文件)
chatgptGPT3训练-gpt文本生成模型.zip (1个子文件)  chatgptGPT3训练-gpt文本生成模型.docx 68KB
chatgptGPT3训练-gpt文本生成模型.docx 68KB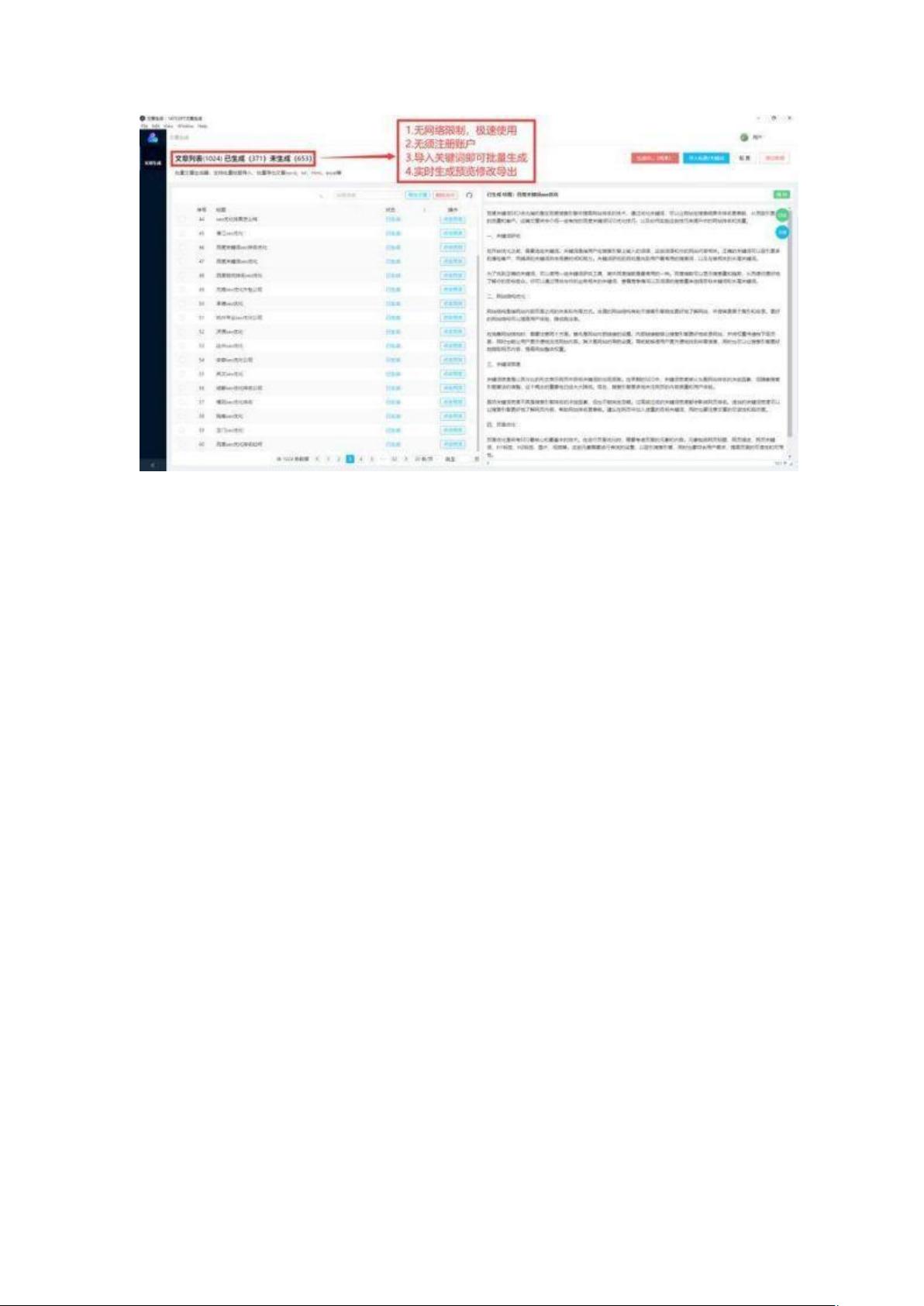













- 1
- 2
前往页