基于改进的路网聚类结合PSOWNN的交通流预测.docx
版权申诉
16 浏览量
2022-12-15
14:16:27
上传
评论
收藏 1.47MB DOCX 举报


1. 引言
近年来,城市智能交通系统成为一个热点研究课题,而城市道路交通流预测对于城市
交通系统能否提供准确高效的出行服务具有重要意义.各专家学者针对这一研究方向提出了
众多预测模型.其中基于统计理论的模型有卡尔曼滤波、ARIMA 模型以及非参数回归模型
等
[1-3]
,基于智能算法的预测模型有神经网络、支持向量机、模糊理论等
[4-6]
.而单一的预测模
型已不能满足特定复杂交通环境中越来越高的精度要求,所以为了进一步考虑复杂交通环
境中的交通流量影响因子,于是将交通网络中复杂周边交通环境及交通流量数据本身特性
与智能算法相结合进行城市交通流预测成为一个重要研究领域.如芮兰兰等人
[7]
通过对交通
流时间序列数据的聚类和分割,再使用泛化能力强的极限学习机进行仿真,以保证数据之
间更高的相似性,但数据来源单一其未考虑到交通流量预测中数据的空间特性.陆文琦等人
[8]
将路网时空特性进行充分考虑后,再采用 ARIMA 模型和 PSO 优化的 BP 神经网络模型
分别对交通流进行短时速度预测,得到最终的组合预测模型,但未考虑交通流数据间的相
关性,忽视了数据冗余现象,进而影响模型整体的预测精度.邴其春等人
[9]
提出通过灰色关
联度分析确定交通流预测影响因子, 然后采用粒子群优化算法构建非参数投影寻踪回归模
型,但未进一步考虑到交通流数据非平稳特性,导致其在非平稳数据段未能达到更好的预
测效果.
本文针对以上研究的不足在构建预测模型时,利用基于交通流量数据相关性分析的路
网聚类算法搜集预测点周边符合一定交通空间特性且与预测点交通流量数据相关系数较高
的观测点,剔除了相关系数低的冗余数据,精简样本数据的数量.再构建一种交通流量分段
加权新型适应度函数给整体样本数据中非平稳数据段给予更大的调节力度,以此进一步来
提高非平稳数据段的预测精度.
2. 基于交通流量数据相关性分析改进的路网聚类算法
在路网主要交通道路中随机设置交通流量数据观测点,本文聚类算法的改进在于将各
观测点的交通流数据与预测点的交通流数据间的相关系数作为路网聚类依据之一.首先通过
设置凝聚度 α、扩展度 β 作为聚类条件,使路网的研究限制在预设路网实际距离范围内,
舍去范围之外的点,从而保证了路网空间实际距离的关联性,同时再在此基础上,考虑路
网聚类中的交通流量数据间的相关性,精简了样本输入数据.
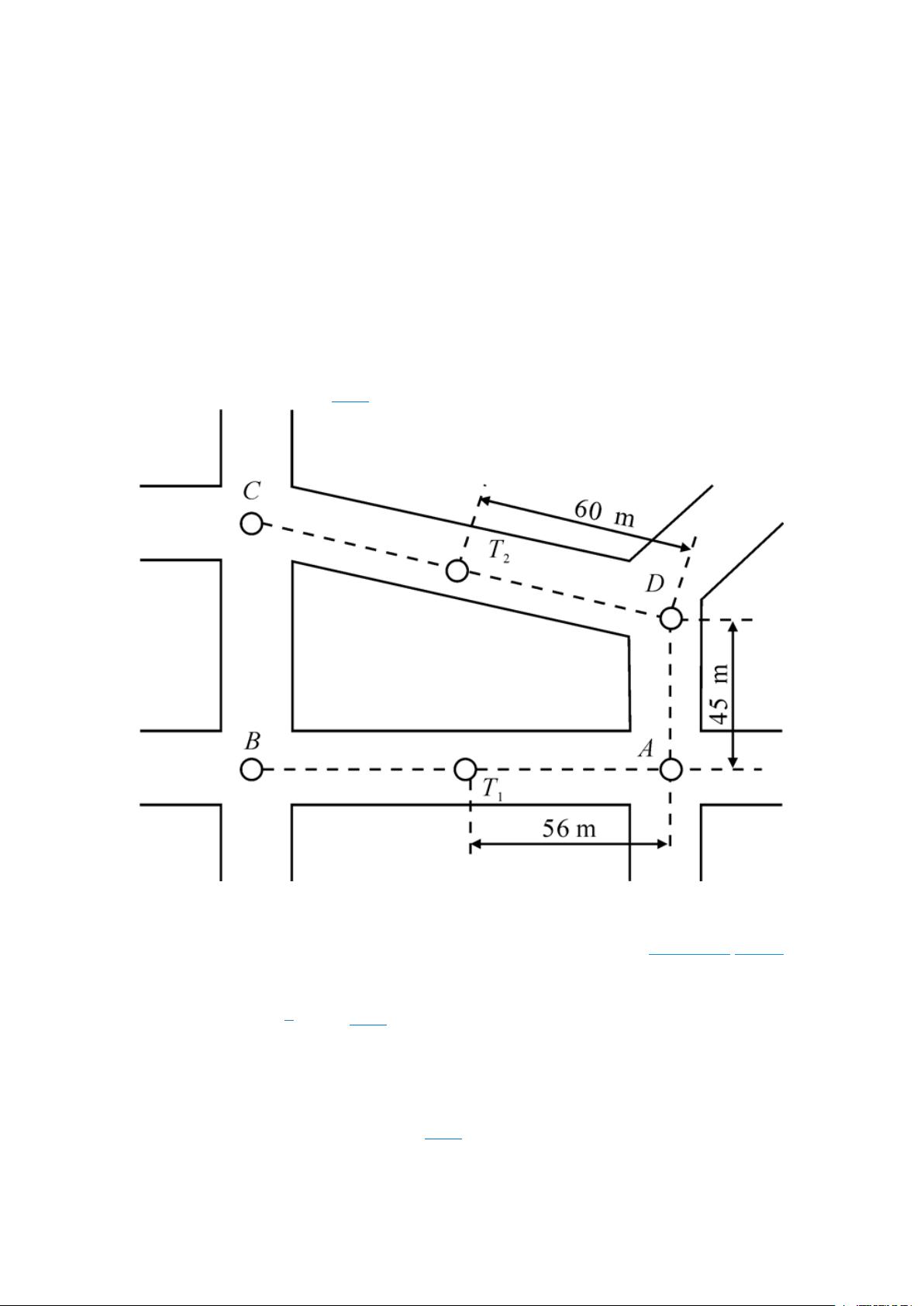
本文取[α, β]范围内与预测点交通流量数据相关系数大于 0.7 的所有观测点,完成聚类
C(见 4.2 节).为简化交通网络复杂性,将路网中的路口看作一个节点,而节点与节点间的路
段作为一段弧.因此一个路网可以由一个无向带权图 G=(V, E, W)来表示,其中 V 为各路口
节点集合,E 表示各路段弧的集合,W 为各段弧权值的集合.

剩余14页未读,继续阅读
资源评论


罗伯特之技术屋
- 粉丝: 3648
- 资源: 1万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP











