

1. 导言
在前几个章节中,我们学习了关于回归和分类的算法,同时也讨论了如何将这些方法集成为强大的算法的集成学
习方式,分别是Bagging和Boosting。本章我们继续讨论集成学习方法的最后一个成员--Stacking,这个集成方
法在比赛中被称为“懒人”算法,因为它不需要花费过多时间的调参就可以得到一个效果不错的算法,同时,这种
算法也比前两种算法容易理解的多,因为这种集成学习的方式不需要理解太多的理论,只需要在实际中加以运用
即可。 stacking严格来说并不是一种算法,而是精美而又复杂的,对模型集成的一种策略。Stacking集成算法可
以理解为一个两层的集成,第一层含有多个基础分类器,把预测的结果(元特征)提供给第二层, 而第二层的分类
器通常是逻辑回归,他把一层分类器的结果当做特征做拟合输出预测结果。在介绍Stacking之前,我们先来对简
化版的Stacking进行讨论,也叫做Blending,接着我们对Stacking进行更深入的讨论。
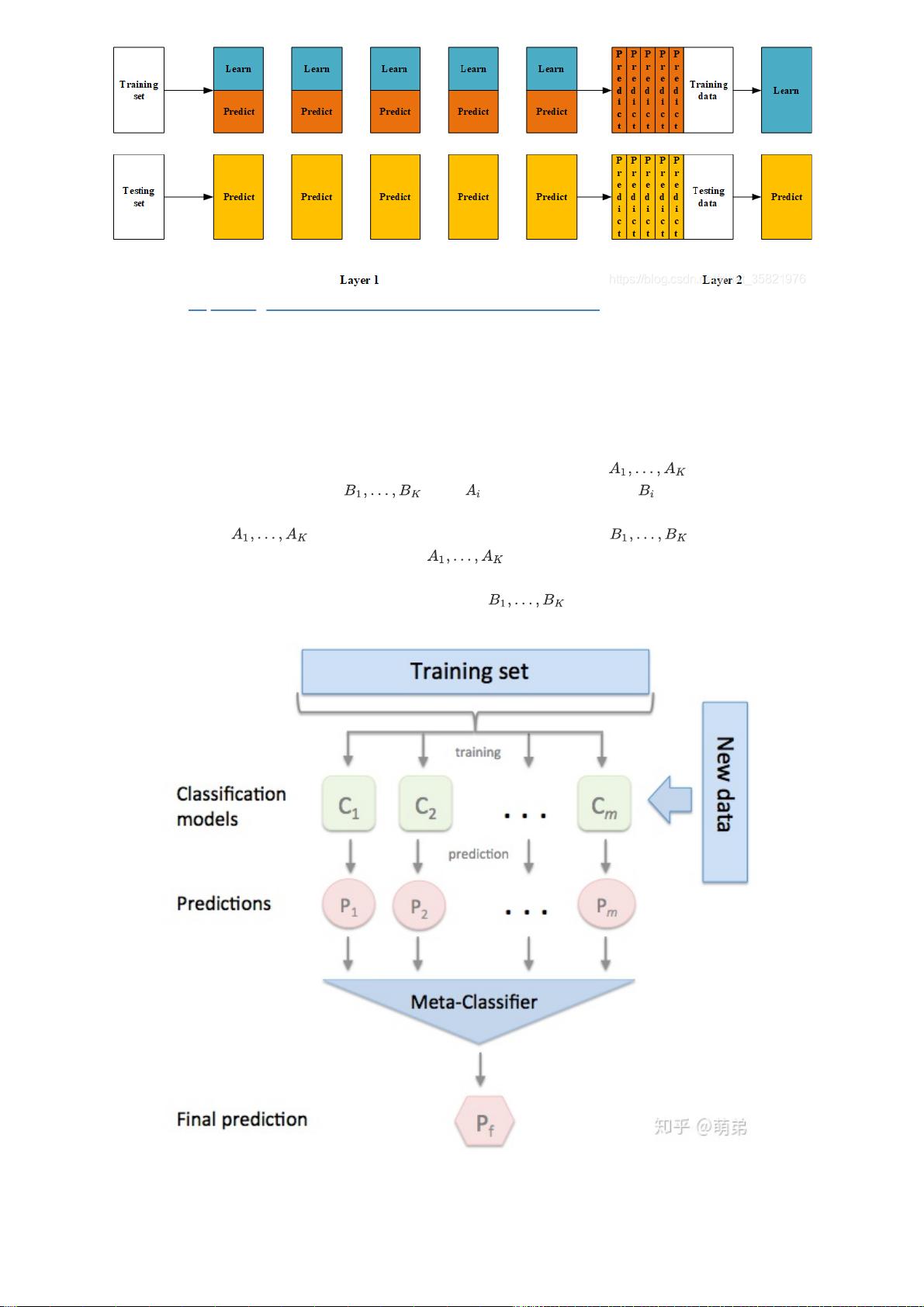
2. Blending集成学习算法
不知道大家小时候有没有过这种经历:老师上课提问到你,那时候你因为开小差而无法立刻得知问题的答案。就
在你彷徨的时候,由于你平时人缘比较好,因此周围的同学向你伸出援手告诉了你他们脑中的正确答案,因此你
对他们的答案加以总结和分析最终的得出正确答案。相信大家都有过这样的经历,说这个故事的目的是为了引出
集成学习家族中的Blending方式,这种集成方式跟我们的故事是十分相像的。如图:(图片来源:https://blog.cs
dn.net/maqunfi/article/details/82220115)


剩余62页未读,继续阅读













评论0