2019-2019-D-VAE, A Variational Autoencoder for Directed Acyclic
需积分: 0 72 浏览量
2022-08-04
13:16:17
上传
评论
收藏 2.34MB PDF 举报


D-VAE: A Variational Autoencoder for Directed
Acyclic Graphs
Muhan Zhang, Shali Jiang, Zhicheng Cui, Roman Garnett, Yixin Chen
Department of Computer Science and Engineering
Washington University in St. Louis
{muhan, jiang.s, z.cui, garnett}@wustl.edu, chen@cse.wustl.edu
Abstract
Graph structured data are abundant in the real world. Among different graph types,
directed acyclic graphs (DAGs) are of particular interest to machine learning re-
searchers, as many machine learning models are realized as computations on DAGs,
including neural networks and Bayesian networks. In this paper, we study deep
generative models for DAGs, and propose a novel DAG variational autoencoder
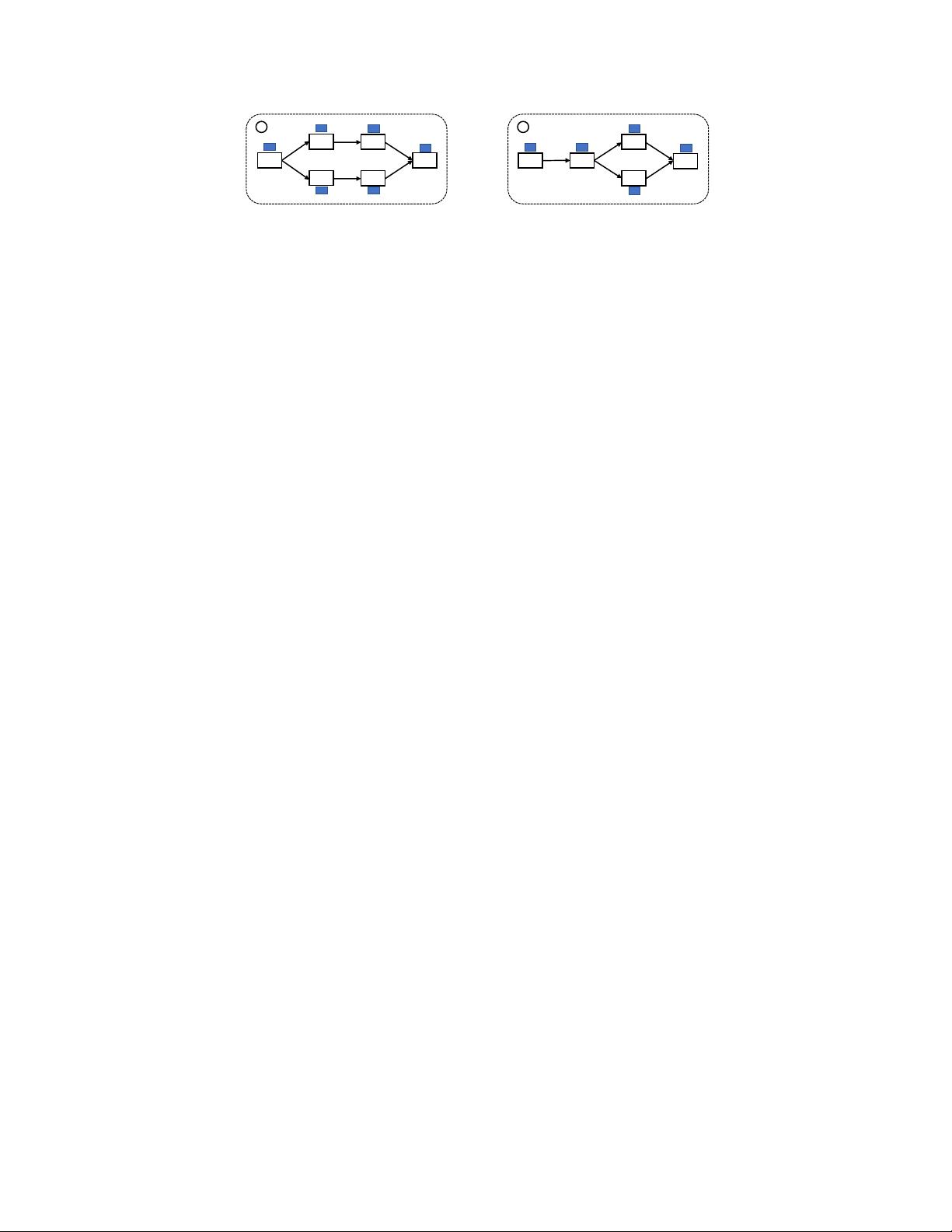
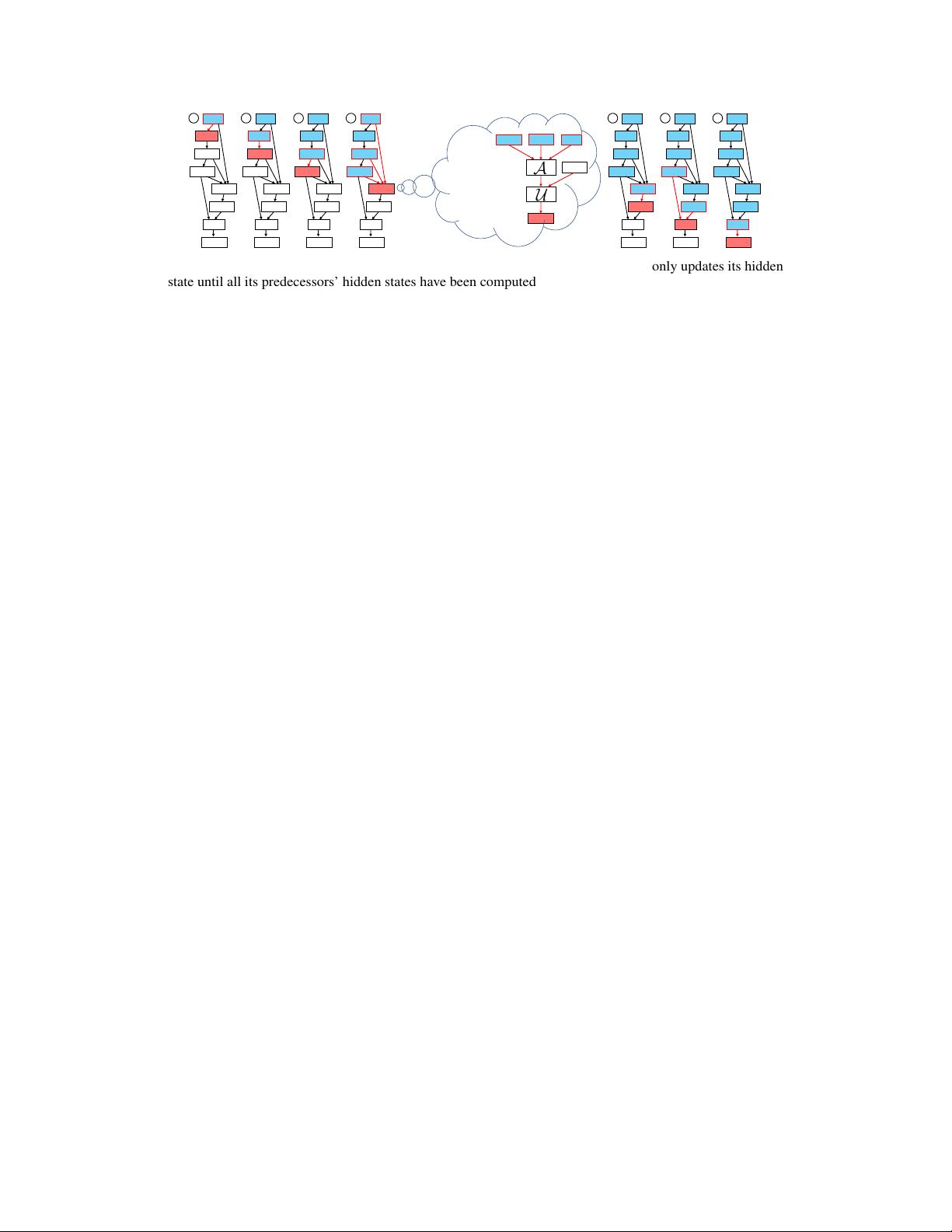
(D-VAE). To encode DAGs into the latent space, we leverage graph neural networks.
We propose an asynchronous message passing scheme that allows encoding the
computations defined by DAGs, rather than using existing simultaneous message
passing schemes to encode local graph structures. We demonstrate the effectiveness
of our proposed D-VAE through two tasks: neural architecture search and Bayesian
network structure learning. Experiments show that our model not only generates
novel and valid DAGs, but also produces a smooth latent space that facilitates
searching for DAGs with better performance through Bayesian optimization.
1 Introduction
Many real-world problems can be posed as optimizing of a directed acyclic graph (DAG) representing
some computational task. In machine learning, deep neural networks are DAGs. Although they have
achieved remarkable performance on a wide range of learning tasks, tremendous efforts need to be
devoted to designing their architectures, which is essentially a DAG optimization task. Similarly,
optimizing the connection structures of Bayesian networks is also a critical problem in learning
graphical models [
1
]. DAG optimization is pervasive in other fields as well. For example, in
electronic circuit design, engineers need to optimize directed network structures not only to realize
target functions, but also to meet specifications such as power usage and operating temperature.
DAGs, as well as other discrete structures, cannot be optimized directly with traditional gradient-
based techniques, as gradients are not available. Bayesian optimization, a state-of-the-art black-box
optimization technique, requires a kernel to measure the similarity between discrete structures as
well as a method to explore the design space and extrapolate to new points. Principled solutions to
these problems are still lacking. Recently, there has been increased interest in training generative
models for discrete data types such as molecules [
2
,
3
], arithmetic expressions [
4
], source code [
5
],
general graphs [
6
], etc. In particular, Kusner et al.
[3]
developed a grammar variational autoencoder
(GVAE) for molecules, which is able to encode and decode molecules into and from a
continuous
latent space
, allowing one to optimize molecule properties by searching in this well-behaved space
instead of a discrete space. Inspired by this work, we propose to train variational autoencoders for
DAGs, and optimize DAG structures in the latent space based on Bayesian optimization.
Existing graph generative models can be classified into three categories: token-based, adjacency-
matrix-based, and graph-based approaches. Token-based graph generative models [
2
,
3
,
7
] represent a
graph as a sequence of tokens (e.g., characters, grammar production rules) and model these sequences
Preprint. Work in progress.
arXiv:1904.11088v2 [cs.LG] 9 May 2019

剩余19页未读,继续阅读













评论0