
实验三:机器翻译
一、数据集
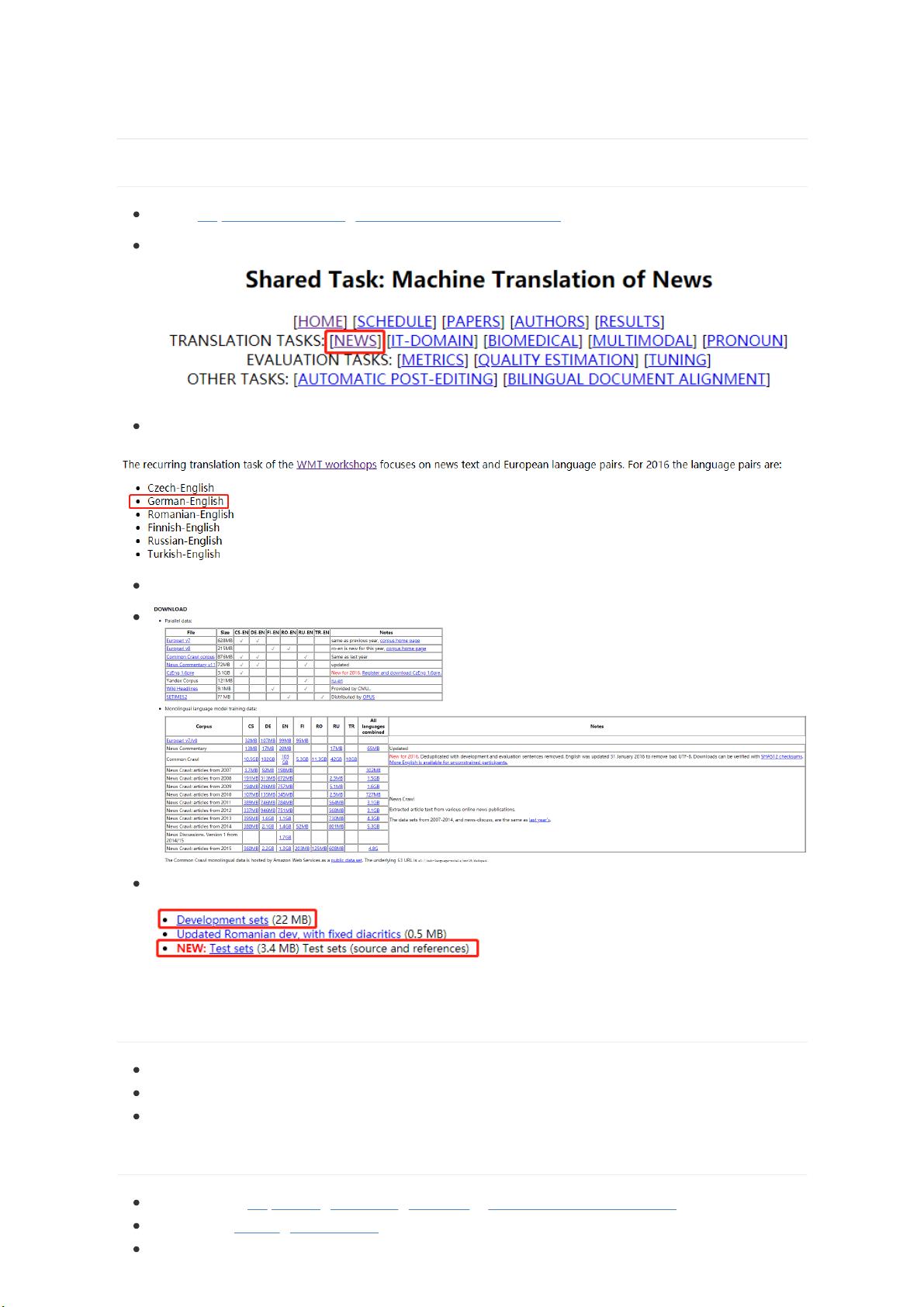
地址:http://www.statmt.org/wmt16/translation-task.html (WMT16)
选择新闻领域数据集:
选择英语->德语的翻译任务:
训练数据不受限制,自取:
验证集和测试集必须用下列给定数据集:
二、方法(Seq2Seq)
Word2vec、Glove、FastText、BERT、RoBERTa、XLNet
GRU、LSTM、BiLSTM
Transformer
三、评价指标
BLEU Score:https://blog.csdn.net/guolindonggld/article/details/56966200
NLTK模块:nltk.align.bleu_score
BLEU值不得低于0.25

FloritaScarlett
- 粉丝: 28
- 资源: 308









最新资源
- springboot189基于SpringBoot电商平台的设计与实现.zip
- springboot190基于springboot框架的工作流程管理系统的设计与实现.zip
- 779【毕设课设】基于单片机小功率数控直流稳压电源仿真设计.zip
- 社区智慧养老监护管理平台设计与实现(代码+数据库+LW)
- 汽车七自由度,平顺性分析模型 优势在于,做到极简的同时 又将门槛降的很低, 很容易看懂的simulink模型 非常适合学习使用
- 行业锦标赛测算数据集.xlsx
- 基于模型预测控制的能量管理控制策略 1.在模型预测控制框架下构建能量管理问题,利用极小值原理pmp进行求解 2.根据期望soc和实际soc之间的差值,对于协态因子进行自适应调整
- Java毕设项目:基于spring+mybatis+maven+mysql实现的医用物理学实验考核系统【含源码+数据库+毕业论文】
- HTML5实现的微信大转盘抽奖特效源码.zip
- 无刷直流电机双闭环控制,基于hall的BLDCM双闭环控制
- Java毕设项目:基于spring+mybatis+maven+mysql实现的在线作业管理系统分前后台【含源码+数据库+毕业论文】
- 碱性水电解槽乳突主极板三维模型创建和流体动力学仿真教程 软件采用fluent,包括凹面和凸面的深度和间距对流场的影响,后处理压力分布,温度分布,流线轨迹,涡分布等 满足基本的学习和研究需求
- Ubuntu+cuda+cmake+demo
- DSP28335在线升级 利用bootloader来实现对dsp28335芯片的固件进行升级,可应用在各个场合,应用领域十分宽泛 只要是dsp28335芯片都可以实现,理论上也可实现dsp其他芯片的
- PLC流水灯控制系统系统设计与仿真 《可编程控制器原理与应用》综合设计性实验 完成基于S7-1200的流水灯控制系统设计与仿真,包括PLC选型、电气原理图绘制,基于博途平台的硬件组态、变量定义、PL
- Java毕设项目:基于spring+mybatis+maven+mysql实现的影视会员管理系统分前后台【含源码+数据库+毕业论文】
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0