
班级:2016211504
学号:2016212011 田宇
数据挖掘实验报告
实验一
一、 任务说明:
1. 熟悉 SPSS 软件和 EXCEL 软件的使用;
2. 基于你的理解,给出给定数据文件的描述报告;
3. 识别给定数据文件中的连续属性,并采用你认为合适的方法完成连续属性的
离散化。
二、 实验结果
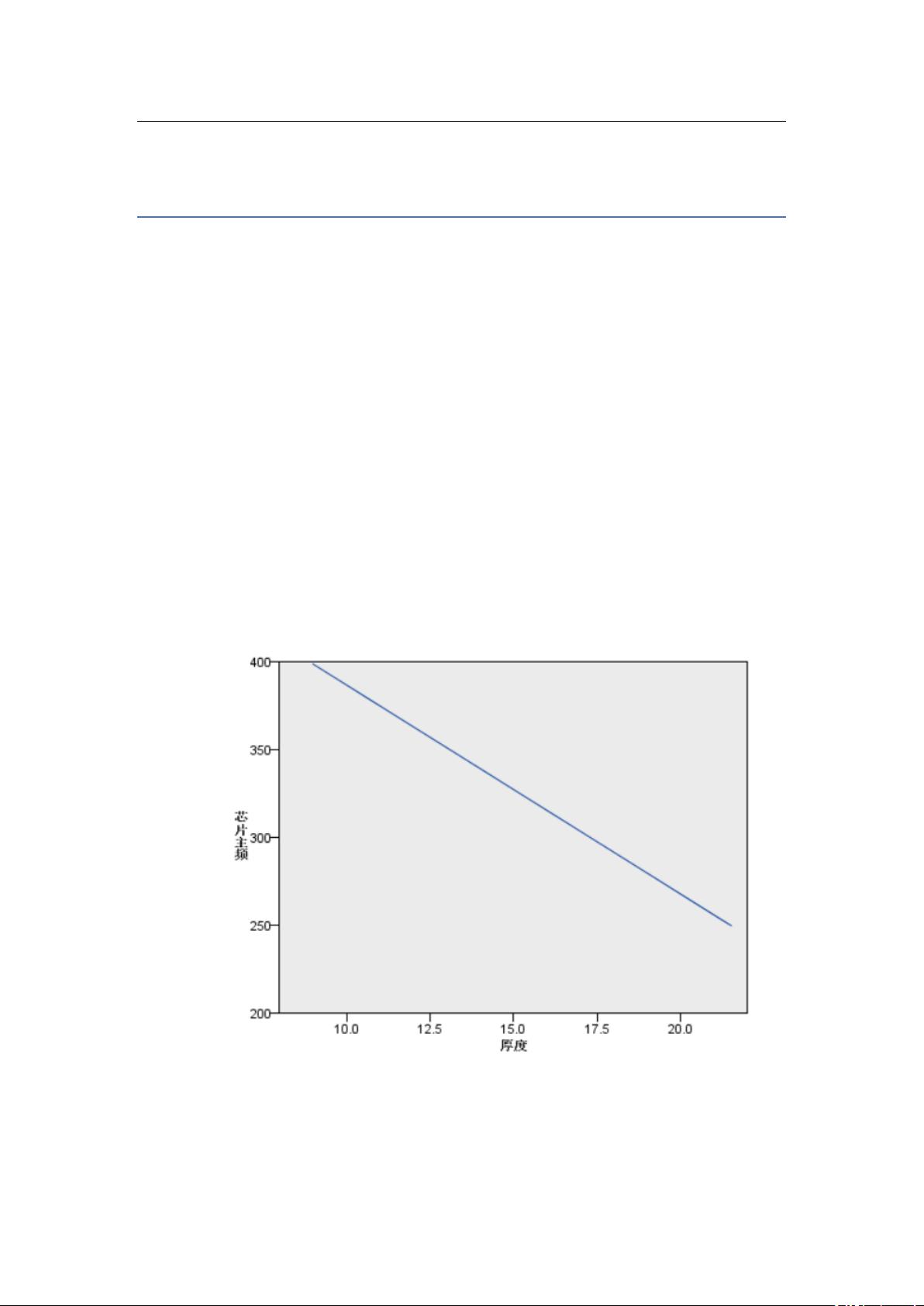
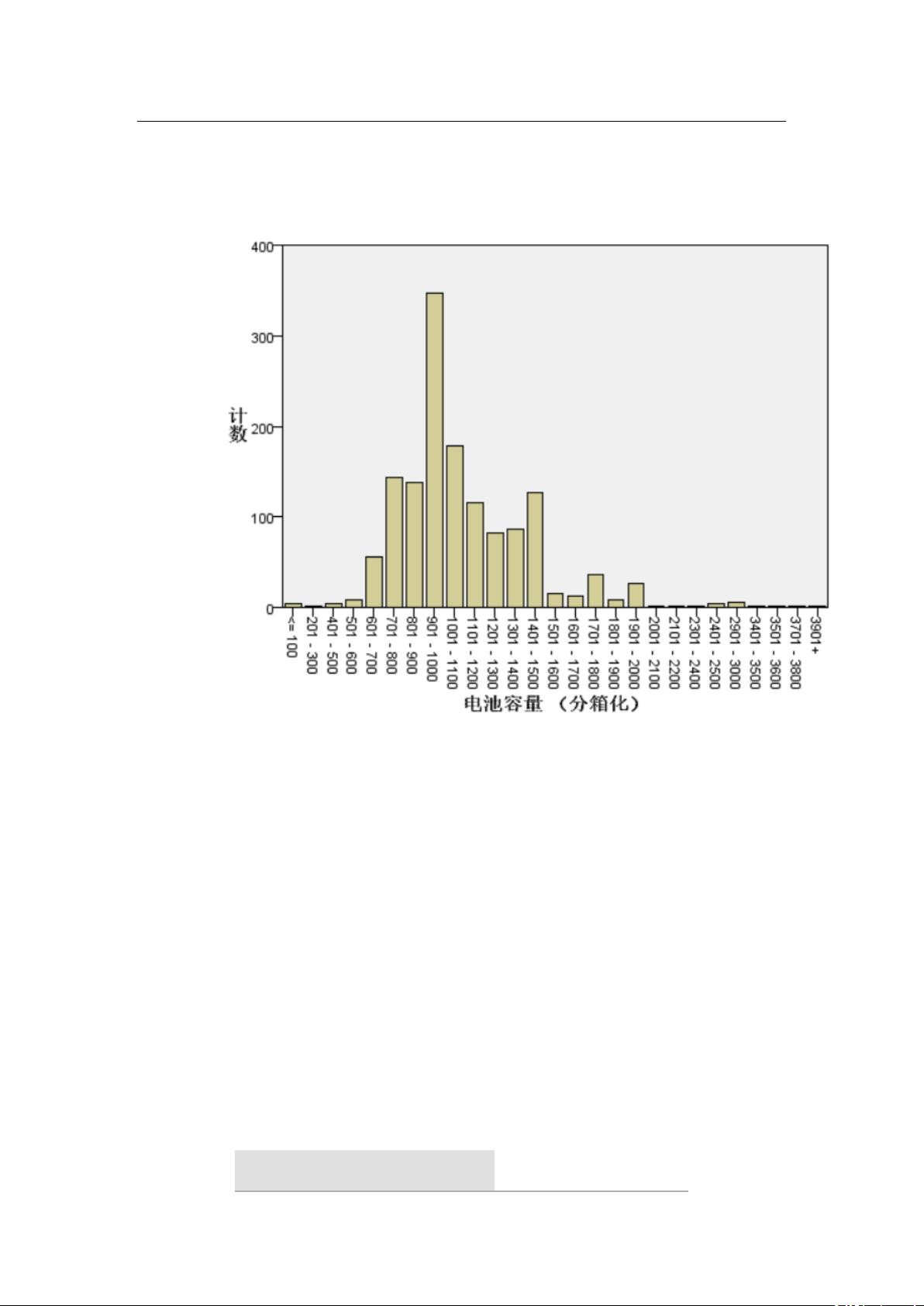
1. 此组数据展示的是 2018 年到 2012 年的各品牌手机上市情况,经过几个相关
属性的分析,这短时间之内低端机占大多数(以芯片的主频作为评估变
量),并且作为主频高的高端机来说,手机的厚度也是越薄的。
从某种意义上说,贵的手机越好看,手感越好。
2. 关于连续变量
所谓连续变量,就是取值可能为很多多情况并且还会连续,比如一个月之内的

剩余19页未读,继续阅读

战神哥
- 粉丝: 1009
- 资源: 325









最新资源
- 白色欧美风格的WebApp软件开发企业网站源码下载.zip
- 白色欧美风格的保险服务公司整站网站源码下载.zip
- 白色欧美风格的比特币金融交易整站网站源码下载.zip
- 鸿蒙开发 懒加载 基类 实现 可无缝继承 LazyForEach
- 橙色小巧实用的医院网站模板下载.zip
- 橙色响应式效果的回忆博客网站模板下载.zip
- 橙色斜纹背景的商业企业网站模板下载.zip
- 橙色斜纹的女性美容护肤企业网站模板下载.zip
- 橙色炫彩背景的产品展示企业官网模板下载.zip
- 橙色炫酷的精品米其林餐厅企业网站模板下载.zip
- 橙色优雅风格的企业网站模板下载.rar
- 橙色阴影边框的商务企业网站模板下载.zip
- 橙色炫酷的甜点蛋糕餐饮公司网站模板下载.zip
- 橙色圆角风格的节日网店模板下载.rar
- 橙色竹子背景复古的个人博客模板下载.zip
- 宠物交流图片分享黑色的网站模板html源码.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0