实验题目
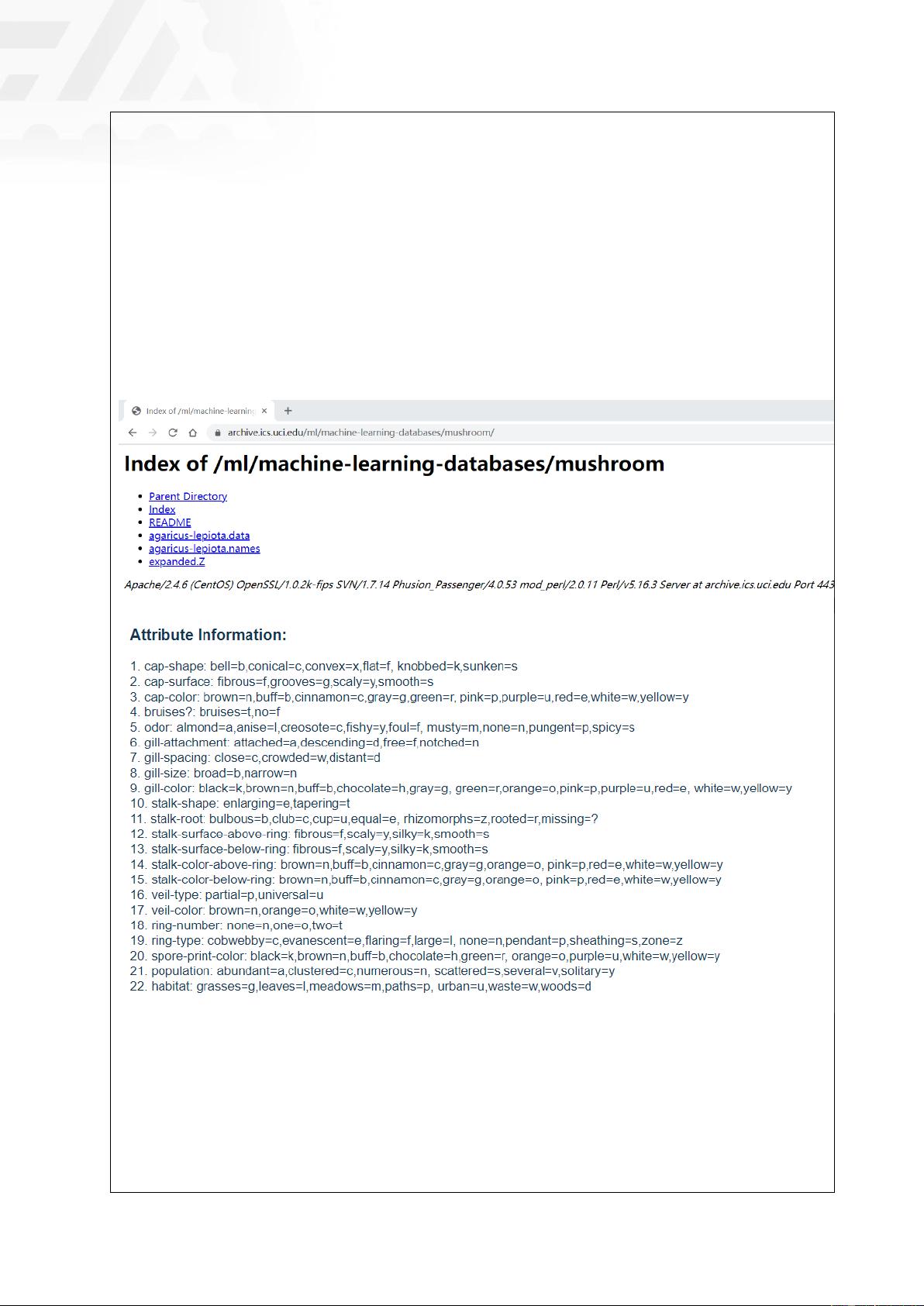
⚫ 本实验采用 UCI 中的 mushroom 数据集
⚫ 数据集链接:https://archive.ics.uci.edu/ml/datasets/Mushroom
需求分析
⚫ 本数据集摘自《奥杜邦学会野外指南》,需求是根据蘑菇的物理特性描述对蘑菇进行
分类:有毒或食用。每一种蘑菇都被确定为绝对可食用,绝对有毒,或未知的可食用
性,不推荐食用。后一类与有毒的一类结合在一起,故该问题为二分类问题。
任务总体设计
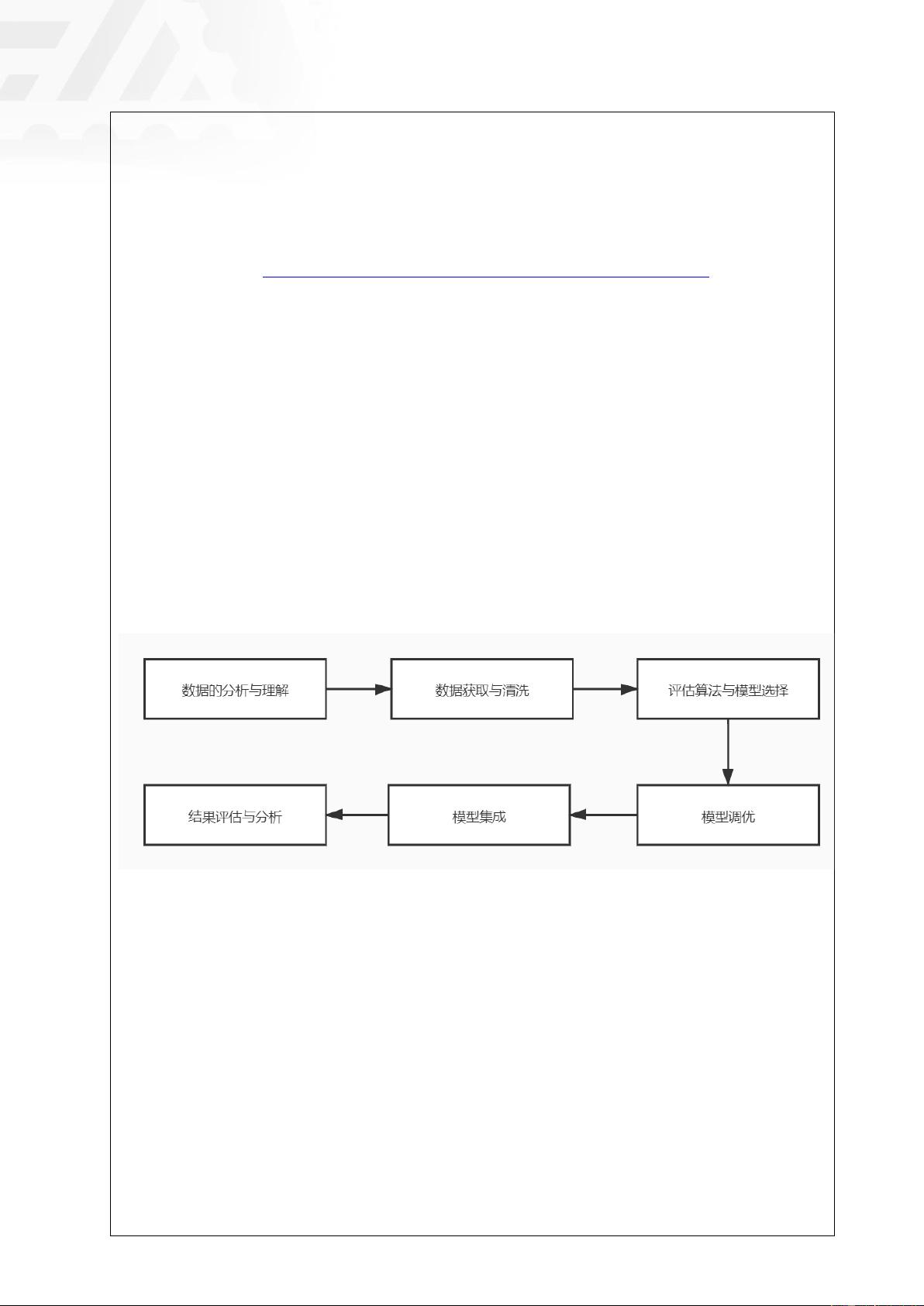
⚫ 整体流程图
⚫ 具体步骤
1. 数据分析与理解:通过直方图、相关性矩阵等可视化的方式发现数据的初步规律
2. 数据获取与清洗:通过 ASCII 编码将字符将数据集转换为数字的形式便于后续的模
型训练,并将通过第一步发现的无用数据以及缺失数据删除
3. 评估算法与模型选择:采取 10 折交叉验证对 KNN、决策树、朴素贝叶斯、SVM、LDA
算法进行评估,并通过箱线图进行结果的可视化展示
4. 模型调优:通过正态化等方法处理数据,有效地提高了 SVM 的分类能力
5. 模型集成:通过面向对象的思想将各个模型对外调用方法统一起来,选取 BP 全连接
神经网络、KNN、决策树进行模型的集成
6. 对集成算法的结果进行评估与思考

















评论0