

大数据课程之 Flink
第一章 概述
1.1 流处理技术的演变
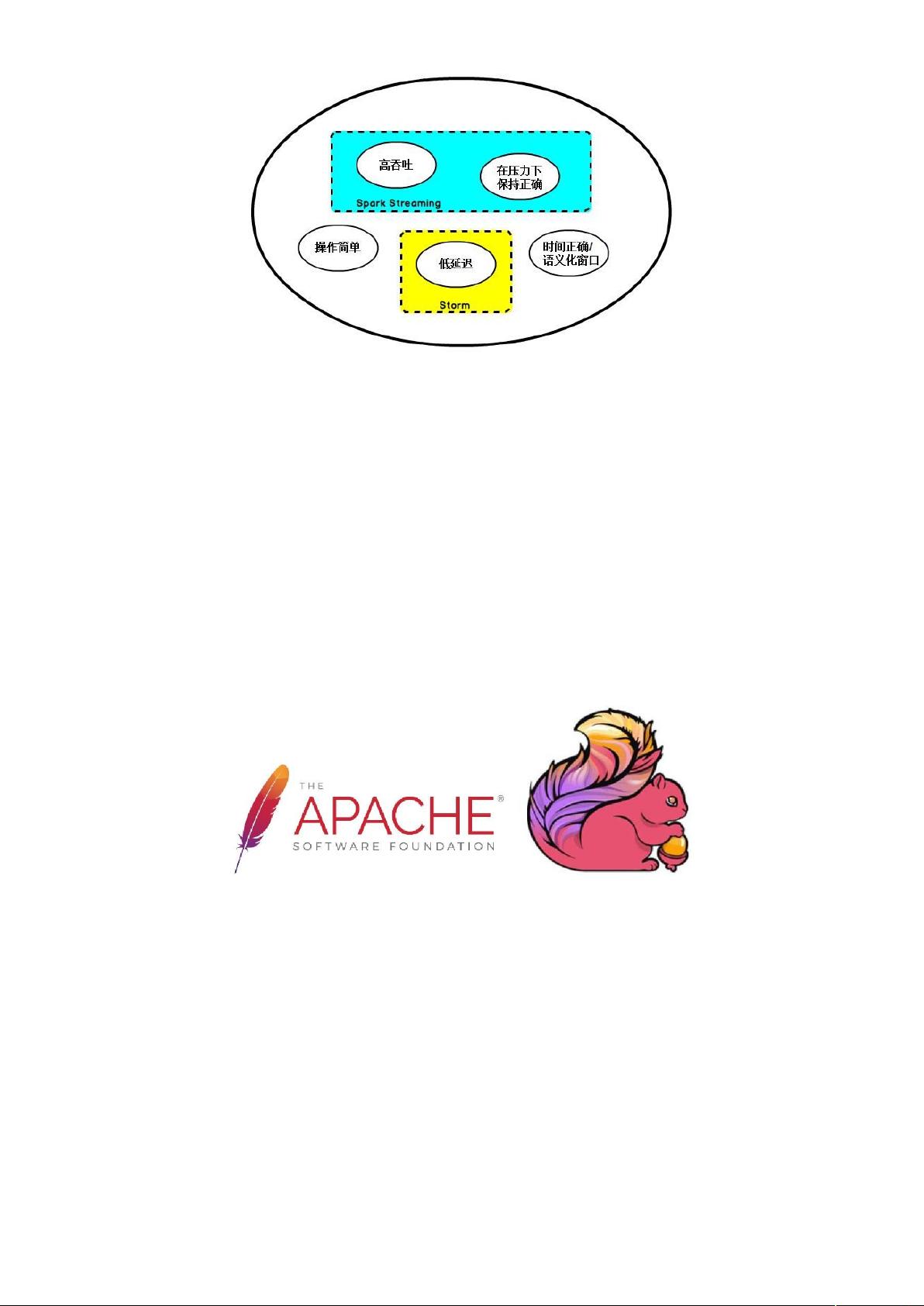
在开源世界里,Apache Storm 项目是流处理的先锋。Storm 最早由 Nathan Marz 和创
业公司 BackType 的一个团队开发,后来才被 Apache 基金会接纳。Storm 提供了低延迟的
流处理,但是它为实时性付出了一些代价:很难实现高吞吐 ,并且其正确性没能达到通常
所需的水平,换句话说,它并不能保证 exactly-once,即便是它能够保证的正确性级别,
其开销也相当大。
在低延迟和高吞吐的流处理系统中维持良好的容错性是非常困难的,但是为了得到有
保障的准确状态,人们想到了一种替代方法:将连续时间中的流数据分割成一系列微小的
批量作业。如果分割得足够小(即所谓的微批处理作业),计算就几乎可以实现真正的流
处理。因为存在延迟,所以不可能做到完全实时,但是每个简单的应用程序都可以实现仅
有几秒甚至几亚秒的延迟。这就是在 Spark 批处理引擎上运行的 Spark Streaming 所使用的
方法。
更重要的是,使用微批处理方法,可以实现 exactly-once 语义,从而保障状态的一致
性。如果一个微批处理失败了,它可以重新运行,这比连续的流处理方法更容易。Storm
Trident 是对 Storm 的延伸,它的底层流处理引擎就是基于微批处理方法来进行计算的,
从而实现了 exactly-once 语义,但是在延迟性方面付出了很大的代价。
对于 Storm Trident 以及 Spark Streaming 等微批处理策略,只能根据批量作业时间的
倍数进行分割,无法根据实际情况分割事件数据,并且,对于一些对延迟比较敏感的作业,
往往需要开发者在写业务代码时花费大量精力来提升性能。这些灵活性和表现力方面的缺
陷,使得这些微批处理策略开发速度变慢,运维成本变高。
于是,Flink 出现了,这一技术框架可以避免上述弊端,并且拥有所需的诸多功能,
还能按照连续事件高效地处理数据,Flink 的部分特性如下图所示:

剩余35页未读,继续阅读
资源评论


aixuedeyuoO
- 粉丝: 2
- 资源: 1









最新资源
- 基于plc的污水处理,组态王动画仿真,带PLC源代码,组态王源代码,图纸,IO地址分配
- MATLAB代码:考虑P2G和碳捕集设备的热电联供综合能源系统优化调度模型 关键词:碳捕集 综合能源系统 电转气P2G 热电联产 低碳调度 参考文档:Modeling and Optimiza
- 永磁同步直线电机仿真实例,仿真教学 maxwell16.0版本 12槽11极 包括图中模型以及一个仿真设置要点word文档教程
- 基于mpx+vue+node.js的双端网盘系统的设计与实现源代码全套技术资料.zip
- welearn刷时长版本v3.0.bat
- 前端分析-2023071100789-y5
- 前端分析-2023071100789
- 调查问卷系统源代码全套技术资料.zip
- C#实用教程郑阿奇梁敬东程序源代码及电子课件
- 环境监测系统源代码全套技术资料.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


