.+/01))))2342536173577345476))8))19:))86573
44373723776;<')=.#&>#?&.%#% !"#$ %!&#' ())!))
*+,))"-)).+/01))))2342536173577345476))8))
19:))8657344373723776;<')=.#&>#?&.%#%
这种以流为世界观的架构,获得的最大好处就是具有极低的延迟。
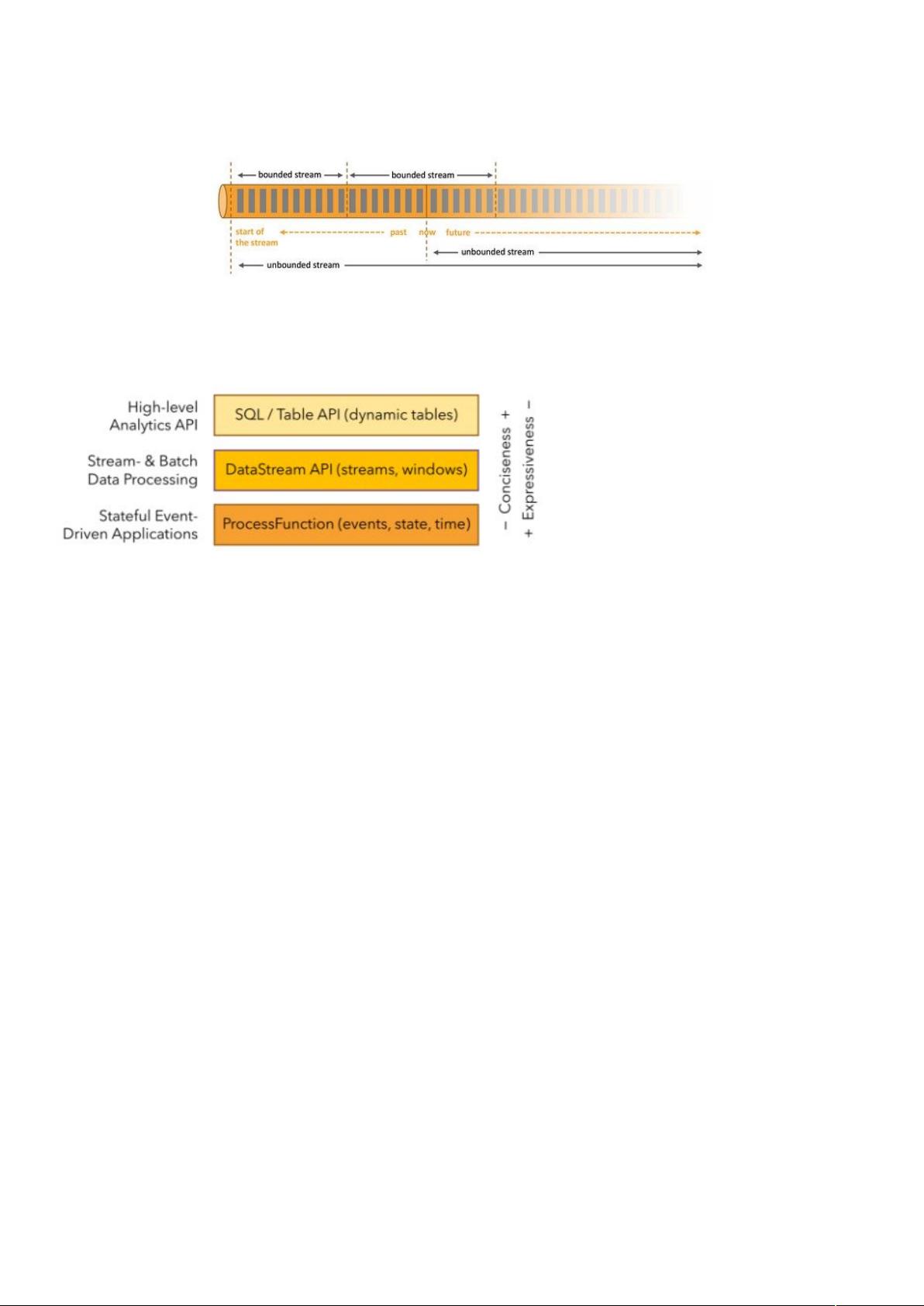
分层
最底层级的抽象仅仅提供了有状态流,它将通过过程函数($-)被嵌入到 "$
中。底层过程函数($-)与"$相集成,使其可以对某些特定的操作进行底层的
抽象,它允许用户可以自由地处理来自一个或多个数据流的事件,并使用一致的容错的状态。除此之外,用
户可以注册事件时间并处理时间回调,从而使程序可以处理复杂的计算。
实 际 上 ,大 多 数 应 用 并 不 需 要 上 述 的 底 层 抽 象 , 而 是 针对 核 心 $ ( $ ) 进 行 编 程 , 比 如
"$(有界或无界流数据)以及 "$(有界数据集)。这些 $ 为数据处理提供了通用的
构建模块,比如由用户定义的多种形式的转换( ),连接(<),聚合(),
窗口操作(010)等等。"$为有界数据集提供了额外的支持,例如循环与迭代。这些 $ 处理
的数据类型以类()的形式由各自的编程语言所表示。
%5$ 是以表为中心的声明式编程,其中表可能会动态变化(在表达流数据时)。 %5$ 遵循
(扩展的)关系模型:表有二维数据结构()(类似于关系数据库中的表),同时 $ 提供可比较的
操作,例如 、<、<、-35+、 等。%5$ 程序声明式地定义了什么逻辑操作应
该执行,而不是准确地确定这些操作代码的看上去如何。
尽管 %5$ 可以通过多种类型的用户自定义函数(!")进行扩展,其仍不如核心 $ 更具表达能
力,但是使用起来却更加简洁(代码量更少)。此外, %5$ 程序在执行之前,会经过内置优化器进行优
化。
你可以在表与"@"之间无缝切换,以允许程序将%5$与"以及"
混合使用。
提供的最高层级的抽象是 A。它在语法与表达能力上与%5$类似,但是是以 A 查询表
达式的形式表现程序。A 抽象与 %5$ 交互密切,A 查询可以直接在 %5$ 定义的表上执行。
目前 作为批处理还不是主流,不如 成熟,所以 " 使用的并不是很多。%5$
和 A 也并不完善,大多都由各大厂商自己定制。所以我们主要学习 "$ 的使用。实际上
作为最接近 >"0 模型的实现,是流批统一的观点,所以基本上使用 " 就可以了。
几大模块

















评论0