尚硅谷大数据之flink教程1
需积分: 0 125 浏览量
2022-08-08
21:35:56
上传
评论 1
收藏 2.78MB DOCX 举报


尚硅谷大数据技术之 Flink
—————————————————————————————
更多 Java –大数据 –前端 –python 人工智能资料下载,可百度访问:尚硅谷官网
尚硅谷大数据技术之 Flink
第一章 Flink 简介
1.1 初识 Flink
Flink 起源于 Stratosphere 项目,Stratosphere 是在 2010~2014 年由 3 所地处柏林的大
学和欧洲的一些其他的大学共同进行的研究项目, 2014 年 4 月 Stratosphere 的代码被复
制并捐赠给了 Apache 软件基金会, 参加这个孵化项目的初始成员是Stratosphere 系统的核
心开发人员, 2014 年 12 月, Flink 一跃成为 Apache 软件基金会的顶级项目。
在德语中,Flink 一词表示快速和灵巧,项目采用一只松鼠的彩色图案作为 logo,这
不仅是因为松鼠具有快速和灵巧的特点,还因为柏林的松鼠有一种迷人的红棕色, 而
Flink 的松鼠 logo 拥有可爱的尾巴,尾巴的颜色与 Apache 软件基金会的 logo 颜色相
呼应,也就是说,这是一只 Apache 风格的松鼠。
Flink Logo
Flink 项目的理念是:“Apache Flink 是为分布式、高性能、随时可用以及准确
的流处理应用程序打造的开源流处理框架”。
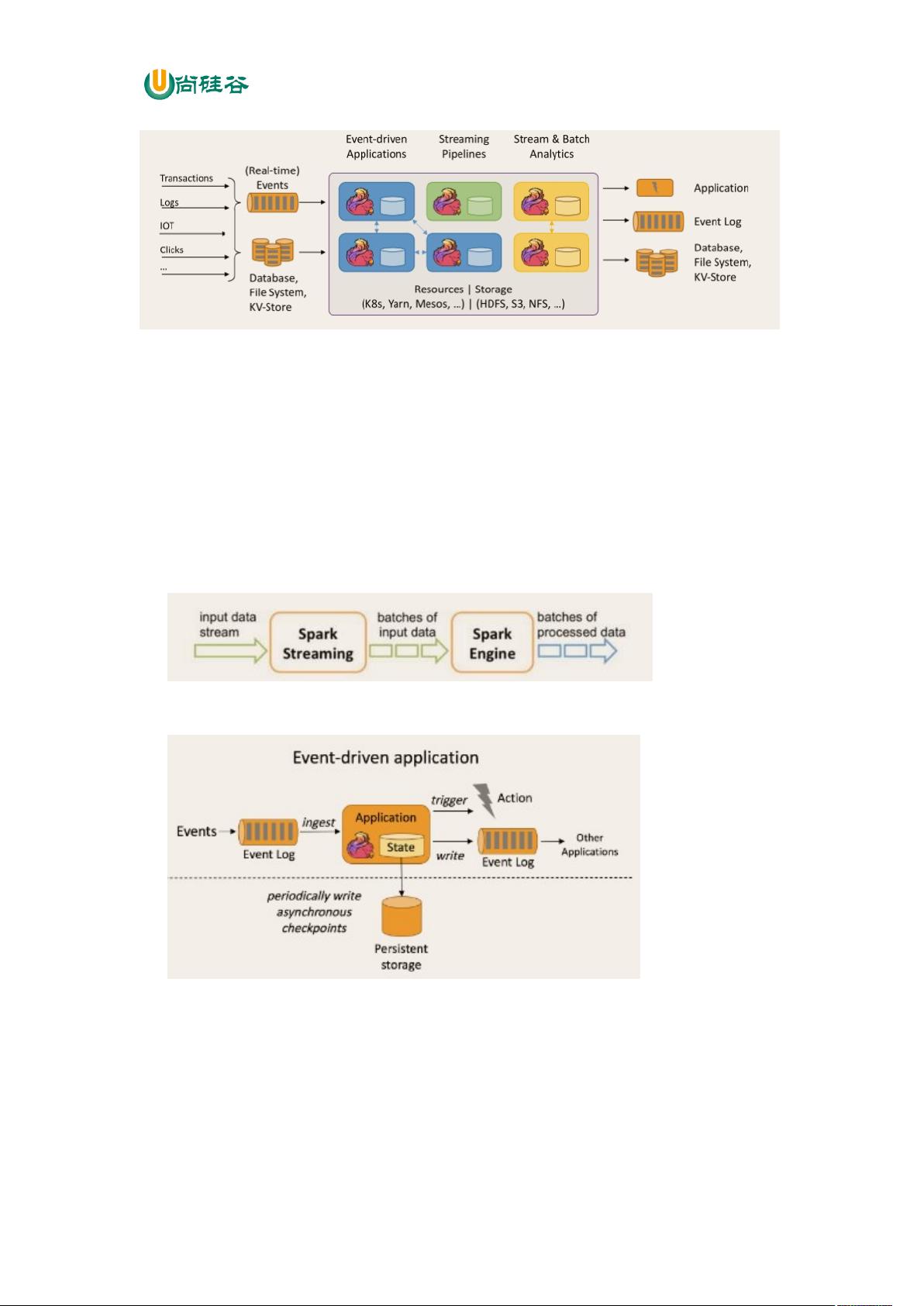
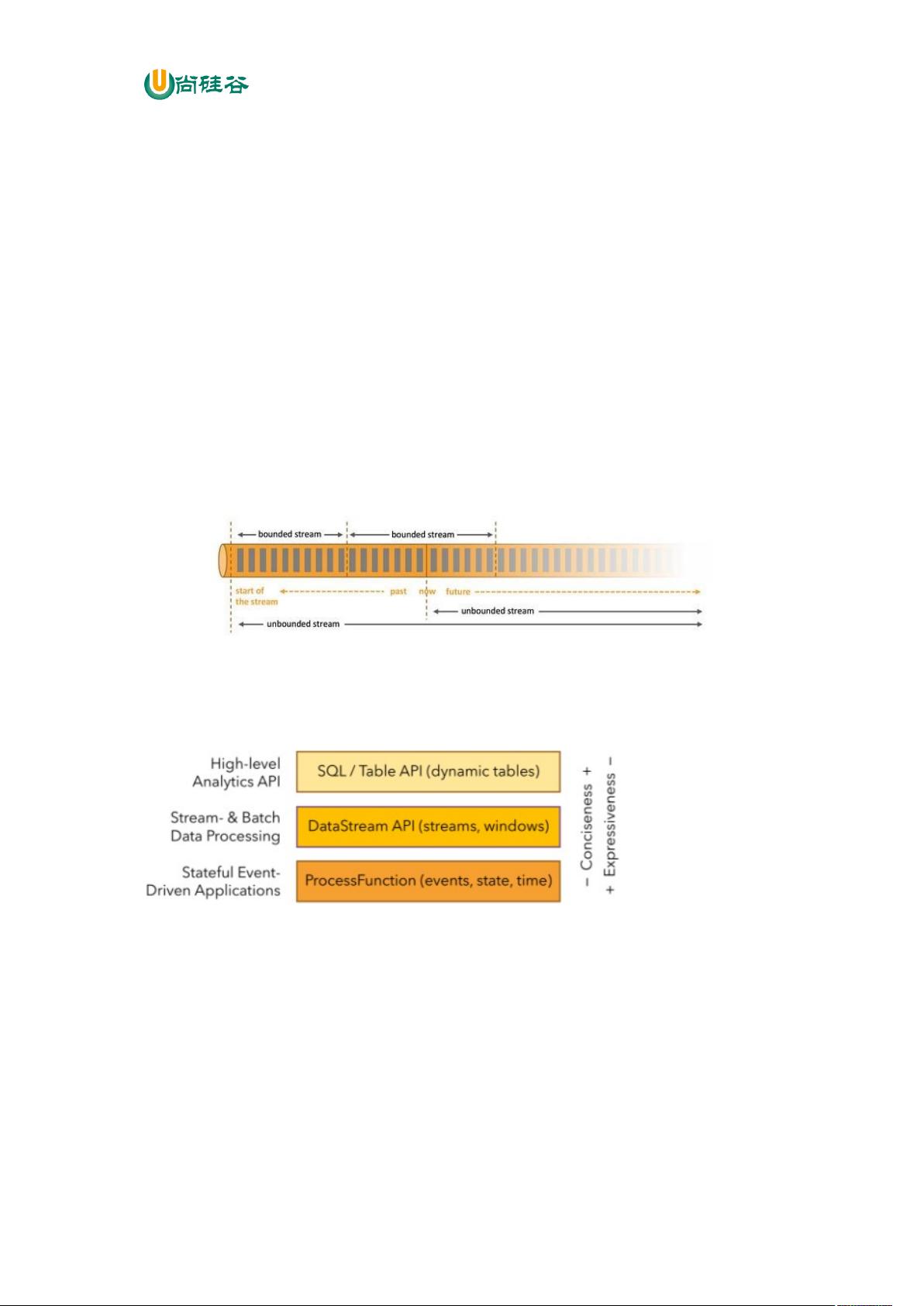
Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计
算。Flink 被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。


剩余99页未读,继续阅读













评论0