清华&南开最新「视觉注意力机制Attention」综述论文
需积分: 39 38 浏览量
2021-11-22
06:14:36
上传
评论 4
收藏 5.26MB PDF 举报


JOURNAL OF L
A
T
E
X CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 1
Attention Mechanisms in Computer Vision:
A Survey
Meng-Hao Guo, Tian-Xing Xu, Jiang-Jiang Liu, Zheng-Ning Liu, Peng-Tao Jiang, Tai-Jiang Mu, Song-Hai
Zhang, Ralph R. Martin, Ming-Ming Cheng, Senior Member, IEEE, Shi-Min Hu, Senior Member, IEEE,
Abstract—Humans can naturally and effectively find salient regions in complex scenes. Motivated by this observation, attention
mechanisms were introduced into computer vision with the aim of imitating this aspect of the human visual system. Such an attention
mechanism can be regarded as a dynamic weight adjustment process based on features of the input image. Attention mechanisms have
achieved great success in many visual tasks, including image classification, object detection, semantic segmentation, video
understanding, image generation, 3D vision, multi-modal tasks and self-supervised learning. In this survey, we provide a comprehensive
review of various attention mechanisms in computer vision and categorize them according to approach, such as channel attention, spatial
attention, temporal attention and branch attention; a related repository https://github.com/MenghaoGuo/Awesome-Vision-Attentions is
dedicated to collecting related work. We also suggest future directions for attention mechanism research.
Index Terms—Attention, Transformer, Survey, Computer Vision, Deep Learning, Salience.
F
1 INTRODUCTION
M
ETHODS for diverting attention to the most impor-
tant regions of an image and disregarding irrelevant
parts are called attention mechanisms; the human visual
system uses one [1], [2], [3], [4] to assist in analyzing and
understanding complex scenes efficiently and effectively.
This in turn has inspired researchers to introduce attention
mechanisms into computer vision systems to improve their
performance. In a vision system, an attention mechanism can
be treated as a dynamic selection process that is realized by
adaptively weighting features according to the importance
of the input. Attention mechanisms have provided benefits
in very many visual tasks, e.g. image classification [5], [6],
object detection [7], [8], semantic segmentation [9], [10], face
recognition [11], [12], person re-identification [13], [14], action
recognition [15], [16], few-show learning [17], [18], medical
image processing [19], [20], image generation [21], [22], pose
estimation [23], super resolution [24], [25], 3D vision [26],
[27], and multi-modal task [28], [29].
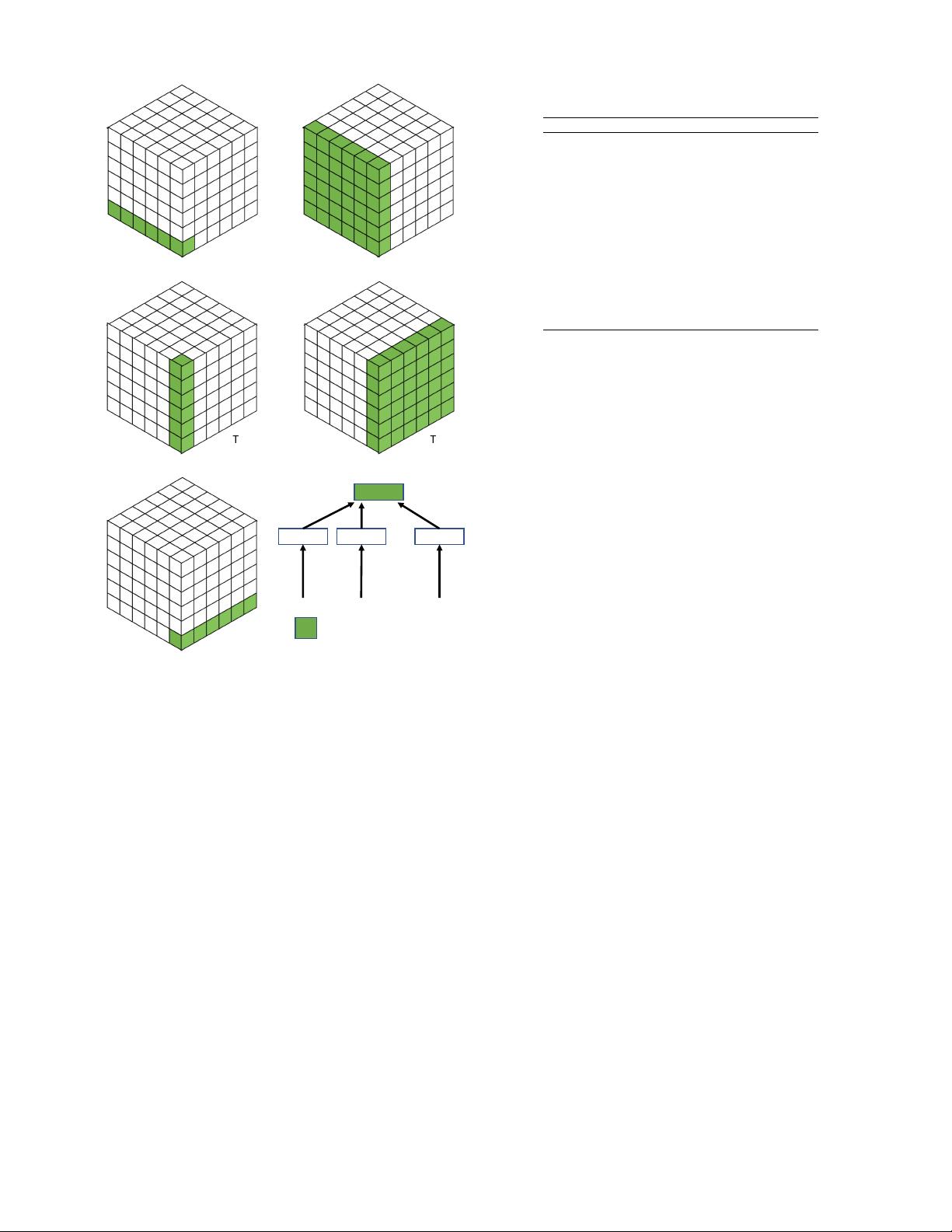
In the past decade, the attention mechanism has played
an increasingly important role in computer vision; Fig. 3,
briefly summarizes the history of attention-based models
in computer vision in the deep learning era. Progress can
be coarsely divided into four phases. The first phase begins
from RAM [31], pioneering work that combined deep neural
networks with attention mechanisms. It recurrently predicts
the important region and updates the whole network in an
end-to-end manner through a policy gradient. Later, various
works [21], [35] adopted a similar strategy for attention in
•
M.H.Guo, T.X.Xu, Z.N.Liu, T.J.Mu, S.H.Zhang and S.M.Hu are with
the BNRist, Department of Computer Science and Technology, Tsinghua
University, Beijing 100084, China.
•
J.J.Liu, P.T.Jiang and M.M.Cheng are with TKLNDST, College of Computer
Science, Nankai University, Tianjin 300350, China.
•
R.R.Martin was with the School of Computer Science and Informatics,
Cardiff University, UK.
• S.M.Hu is the corresponding author.
E-mail: shimin@tsinghua.edu.cn.
Channel Attention
e.g.,SENet
What to attend
Spatial Attention
e.g.,Self-attention
Where to attend
Channel & Spatial
Attention
e.g.,CBAM
Temporal Attention
e.g., GLTR
When to attend
∅
Spatial&Temporal
Attention
e.g., STA-LSTM
∅
Branch Attention
e.g., SKNet
Which to attend
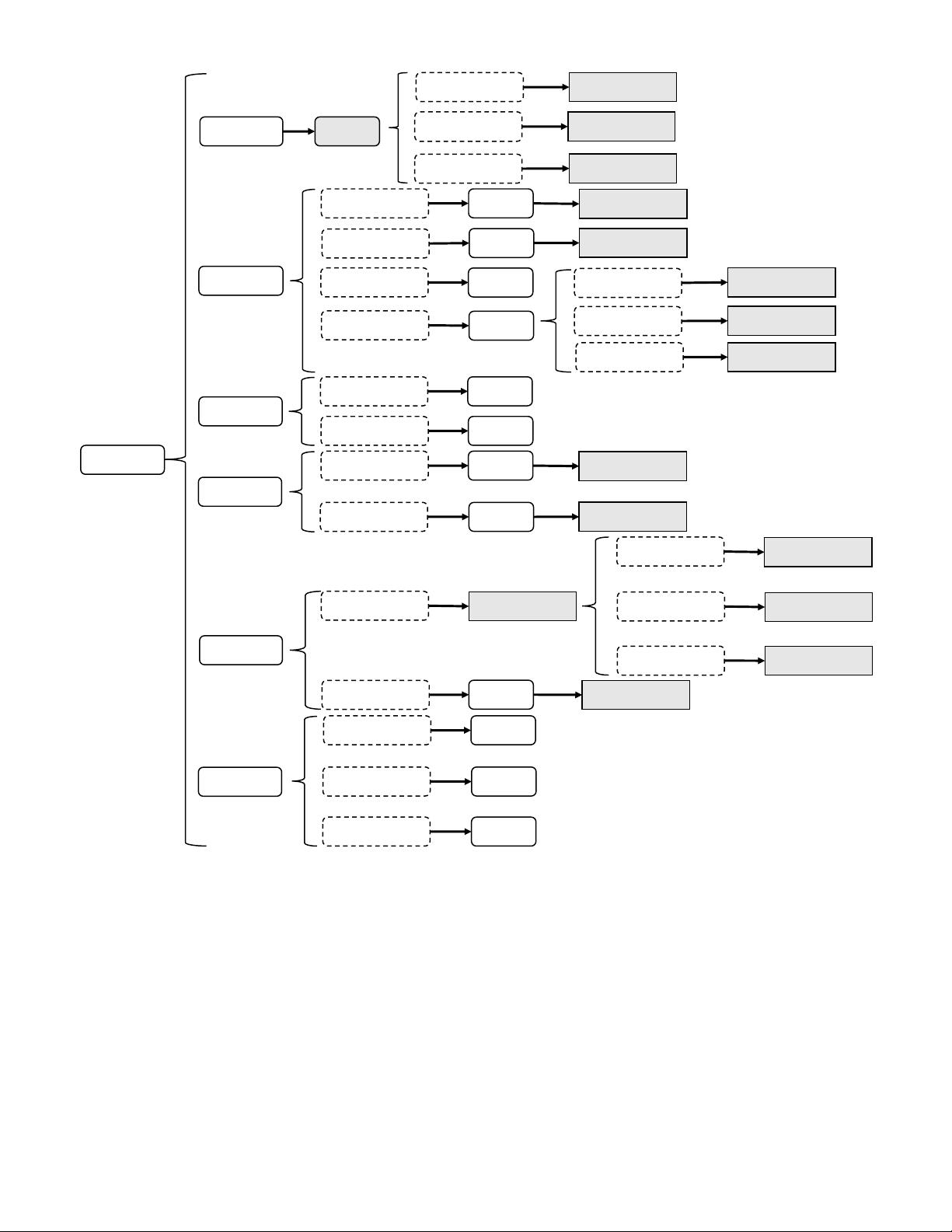
Fig. 1. Attention mechanisms can be categorised according to data
domain. These include four fundamental categories of channel attention,
spatial attention, temporal attention and branch attention, and two hybrid
categories, combining channel & spatial attention and spatial & temporal
attention. ∅ means such combinations do not (yet) exist.
vision. In this phase, recurrent neural networks(RNNs) were
necessary tools for an attention mechanism. At the start of
the second phase, Jaderberg et al. [32] proposed the STN
which introduces a sub-network to predict an affine trans-
formation used to to select important regions in the input.
Explicitly predicting discriminatory input features is the
major characteristic of the second phase; DCNs [7], [36] are
representative works. The third phase began with SENet [5]
arXiv:2111.07624v1 [cs.CV] 15 Nov 2021


剩余26页未读,继续阅读






评论0
最新资源