

Created by: Jim Liang
:: Linear Regression
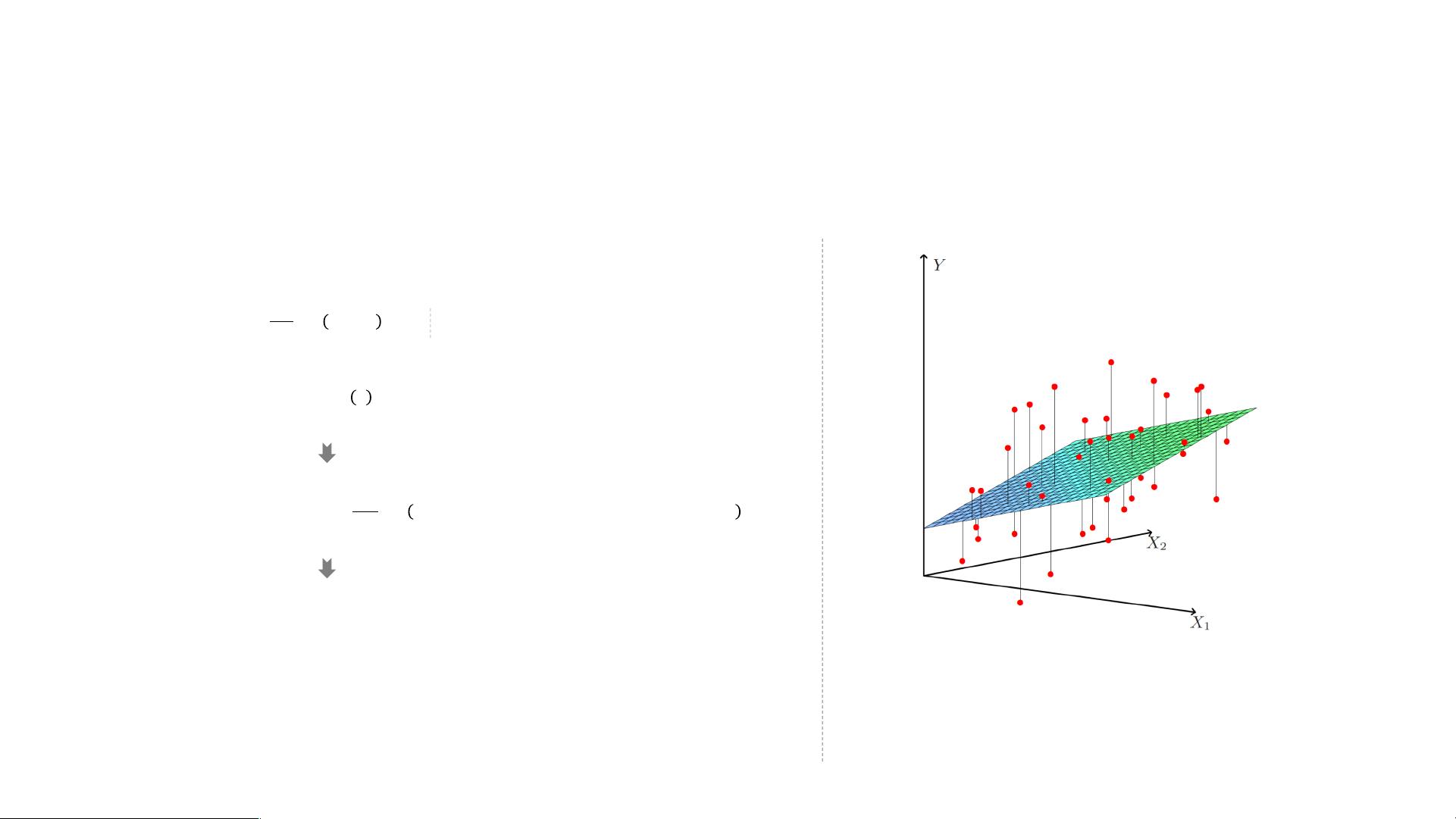
Multiple Linear Regression
For convenience of notation, we can define !
"
=1. Thus, we simplify the equation of multiple linear regression as follow.
Equation :
In the multiple regression setting, because of the potentially large number of predictors,
it is more efficient to use matrices to define the regression model and the subsequent
analyses
1
1 Source: https://onlinecourses.science.psu.edu/stat501/node/382
#$ % &
'
( &
)
*
)
( &
+
*
+
( &
,
*
,
( - (&
.
*
/
#$ % &
'
*
'
( &
)
*
)
( &
+
*
+
( &
,
*
,
( - (&
.
*
/
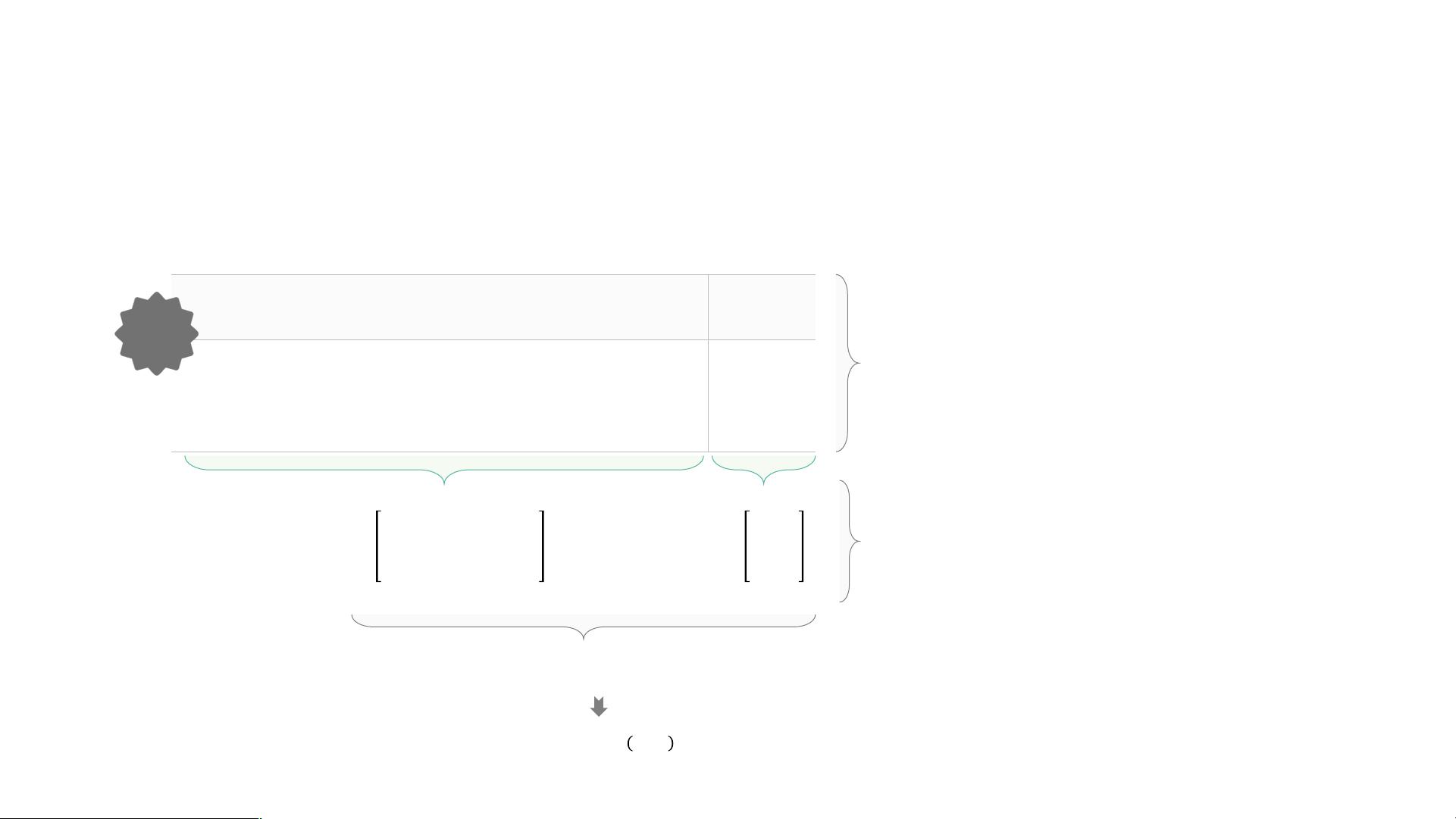
For convenience of notation, define *
'
=1, then
0 =
*
'
*
)
*
+
1
*
/
& =
&
'
&
)
&
+
1
&
/
#$ % &
'
*
'
( &
)
*
)
( &
+
*
+
( &
,
*
,
( - (&
.
*
/
#$ % &
2
0
&
'
&
)
&
+
3 &
/
*
'
*
)
*
+
1
*
/
&
2
0
Linear Regression With Multiple Variables (8mins)
https://youtu.be/Q4GNLhRtZNc (by Andrew Ng)

剩余294页未读,继续阅读






评论0
最新资源