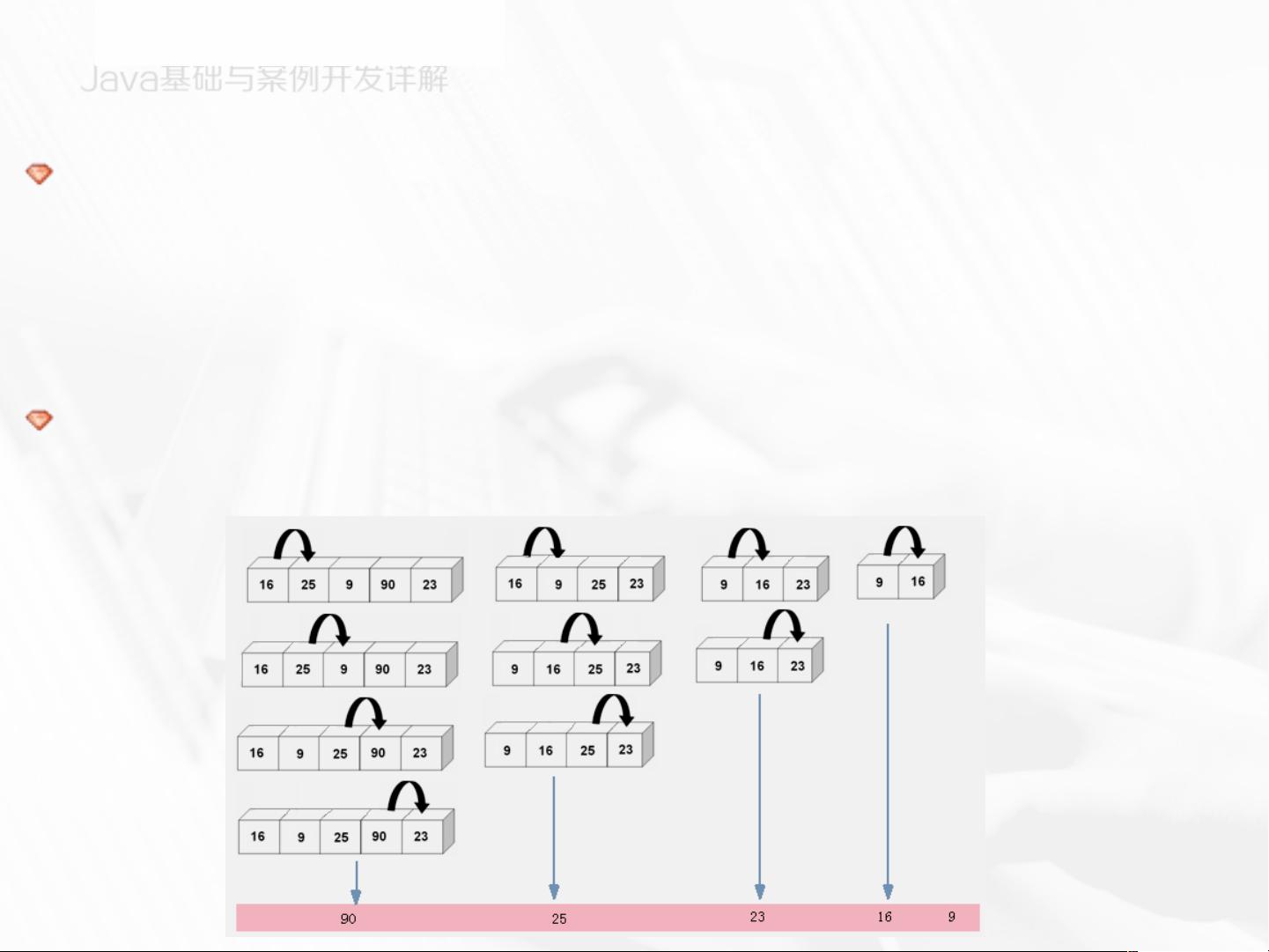
完整版:https://download.csdn.net/download/qq_27595745/89522468 【课程大纲】 1-1 什么是java 1-2 认识java语言 1-3 java平台的体系结构 1-4 java SE环境安装和配置 2-1 java程序简介 2-2 计算机中的程序 2-3 java程序 2-4 java类库组织结构和文档 2-5 java虚拟机简介 2-6 java的垃圾回收器 2-7 java上机练习 3-1 java语言基础入门 3-2 数据的分类 3-3 标识符、关键字和常量 3-4 运算符 3-5 表达式 3-6 顺序结构和选择结构 3-7 循环语句 3-8 跳转语句 3-9 MyEclipse工具介绍 3-10 java基础知识章节练习 4-1 一维数组 4-2 数组应用 4-3 多维数组 4-4 排序算法 4-5 增强for循环 4-6 数组和排序算法章节练习 5-0 抽象和封装 5-1 面向过程的设计思想 5-2 面向对象的设计思想 5-3 抽象 5-4 封装 5-5 属性 5-6 方法的定义 5-7 this关键字 5-8 javaBean 5-9 包 package 5-10 抽象和封装章节练习 6-0 继承和多态 6-1 继承 6-2 object类 6-3 多态 6-4 访问修饰符 6-5 static修饰符 6-6 final修饰符 6-7 abstract修饰符 6-8 接口 6-9 继承和多态 章节练习 7-1 面向对象的分析与设计简介 7-2 对象模型建立 7-3 类之间的关系 7-4 软件的可维护与复用设计原则 7-5 面向对象的设计与分析 章节练习 8-1 内部类与包装器 8-2 对象包装器 8-3 装箱和拆箱 8-4 练习题 9-1 常用类介绍 9-2 StringBuffer和String Builder类 9-3 Rintime类的使用 9-4 日期类简介 9-5 java程序国际化的实现 9-6 Random类和Math类 9-7 枚举 9-8 练习题 10-1 java异常处理 10-2 认识异常 10-3 使用try和catch捕获异常 10-4 使用throw和throws引发异常 10-5 finally关键字 10-6 getMessage和printStackTrace方法 10-7 异常分类 10-8 自定义异常类 10-9 练习题 11-1 Java集合框架和泛型机制 11-2 Collection接口 11-3 Set接口实现类 11-4 List接口实现类 11-5 Map接口 11-6 Collections类 11-7 泛型概述 11-8 练习题 12-1 多线程 12-2 线程的生命周期 12-3 线程的调度和优先级 12-4 线程的同步 12-5 集合类的同步问题 12-6 用Timer类调度任务 12-7 练习题 13-1 Java IO 13-2 Java IO原理 13-3 流类的结构 13-4 文件流 13-5 缓冲流 13-6 转换流 13-7 数据流 13-8 打印流 13-9 对象流 13-10 随机存取文件流 13-11 zip文件流 13-12 练习题 14-1 图形用户界面设计 14-2 事件处理机制 14-3 AWT常用组件 14-4 swing简介 14-5 可视化开发swing组件 14-6 声音的播放和处理 14-7 2D图形的绘制 14-8 练习题 15-1 反射 15-2 使用Java反射机制 15-3 反射与动态代理 15-4 练习题 16-1 Java标注 16-2 JDK内置的基本标注类型 16-3 自定义标注类型 16-4 对标注进行标注 16-5 利用反射获取标注信息 16-6 练习题 17-1 顶目实战1-单机版五子棋游戏 17-2 总体设计 17-3 代码实现 17-4 程序的运行与发布 17-5 手动生成可执行JAR文件 17-6 练习题 18-1 Java数据库编程 18-2 JDBC类和接口 18-3 JDBC操作SQL 18-4 JDBC基本示例 18-5 JDBC应用示例 18-6 练习题 19-1 。。。 ### Java排序算法详解 #### 4.4 排序算法 **排序算法**是指通过一定的规则重新排列一组数据,使其按照特定的顺序(通常是升序或降序)排列。它是计算机科学中最基本的操作之一,广泛应用于各种场景。本节重点介绍了几种经典的排序方法:冒泡排序、插入排序、快速排序和选择排序。 #### 4.4.1 冒泡排序 **冒泡排序**是一种简单直观的排序算法。其工作原理是通过重复地遍历待排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。遍历数列的工作是重复进行的,直到没有再需要交换,也就是说该数列已经排序完成。 **算法步骤**: 1. **初始化**:设定一个标记 `swapped`,用于记录本轮是否有交换发生。 2. **遍历**:从头到尾遍历整个数组。 3. **比较与交换**:对于每一对相邻元素,如果第一个比第二个大(对于升序排序),就交换它们。 4. **重复**:重复上述步骤,直到遍历结束且标记 `swapped` 保持为 `false`,表示无需再交换元素,排序完成。 **特点**: - 最好情况下的时间复杂度为 O(n),当输入数组已经是有序时。 - 最坏情况下和平均情况下时间复杂度为 O(n^2)。 - 空间复杂度为 O(1),是一种原地排序算法。 #### 4.4.2 插入排序 **插入排序**是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。 **算法步骤**: 1. **初始化**:假设数组的第一个元素是已排序的。 2. **插入**:从第二个元素开始,每个元素插入到已排序的部分中。 3. **比较与移动**:将当前元素与已排序部分的元素从后往前进行比较,找到合适的位置后将当前元素插入。 4. **重复**:重复上述步骤,直到所有元素被排序。 **特点**: - 最好情况下的时间复杂度为 O(n),当输入数组已经是有序时。 - 最坏情况下和平均情况下时间复杂度为 O(n^2)。 - 稳定排序,空间复杂度为 O(1)。 #### 4.4.3 快速排序 **快速排序**是一种高效的排序算法,采用分治策略来把一个序列分为较小和较大的两个子序列。 **算法步骤**: 1. **选择基准值**:从序列中挑出一个元素,称为“基准”。 2. **分区**:重新排序数组,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分割结束之后,该基准就处于数列的中间位置。 3. **递归排序**:递归地把小于基准值元素的子数组和大于基准值元素的子数组排序。 **特点**: - 平均情况下时间复杂度为 O(n log n)。 - 最坏情况下时间复杂度为 O(n^2),但可以通过随机化选择基准值来避免这种情况。 - 不稳定排序,空间复杂度为 O(log n)。 #### 4.4.4 选择排序 **选择排序**是一种简单直观的排序算法。它的工作原理是在未排序序列中找到最小(或最大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(或最大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。 **算法步骤**: 1. **初始化**:从数组的第一个元素开始,找到最小(或最大)的元素。 2. **交换**:将找到的最小(或最大)元素与数组的第一个元素交换位置。 3. **重复**:从剩下的未排序数组中继续这个过程,直到整个数组排序完成。 **特点**: - 时间复杂度始终为 O(n^2),无论是最好、最坏还是平均情况。 - 空间复杂度为 O(1),是一种原地排序算法。 - 不稳定排序。 ### 小结 以上四种排序算法都是学习和了解排序概念的基础。它们各有优缺点,在不同的应用场景下有着不同的表现。在实际开发过程中,根据具体需求选择合适的排序算法是非常重要的。例如,对于小规模数据集,插入排序可能更高效;而对于大规模数据集,快速排序则更为适用。
剩余12页未读,继续阅读
评论星级较低,若资源使用遇到问题可联系上传者,3个工作日内问题未解决可申请退款~