斯坦福机器学习讲义
需积分: 10 197 浏览量
2017-12-20
15:28:46
上传
评论
收藏 4.77MB PDF 举报


CS229 Lecture notes
Andrew Ng
Supervised learning
Lets start by talking about a few examples of supervised learning problems.
Suppose we have a dataset giving the living areas and prices of 47 houses
from Portland, Oregon:
Living area (feet
2
) Price (1000$s)
2104 400
1600
330
2400
369
1416
232
3000
540
.
.
.
.
.
.
We can plot this data:
500 1000 1500 2000 2500 3000 3500 4000 4500 5000
0
100
200
300
400
500
600
700
800
900
1000
housing prices
square feet
price (in $1000)
Given data like this, how can we learn to predict the prices of other houses
in Portland, as a function of the size of their living areas?
1



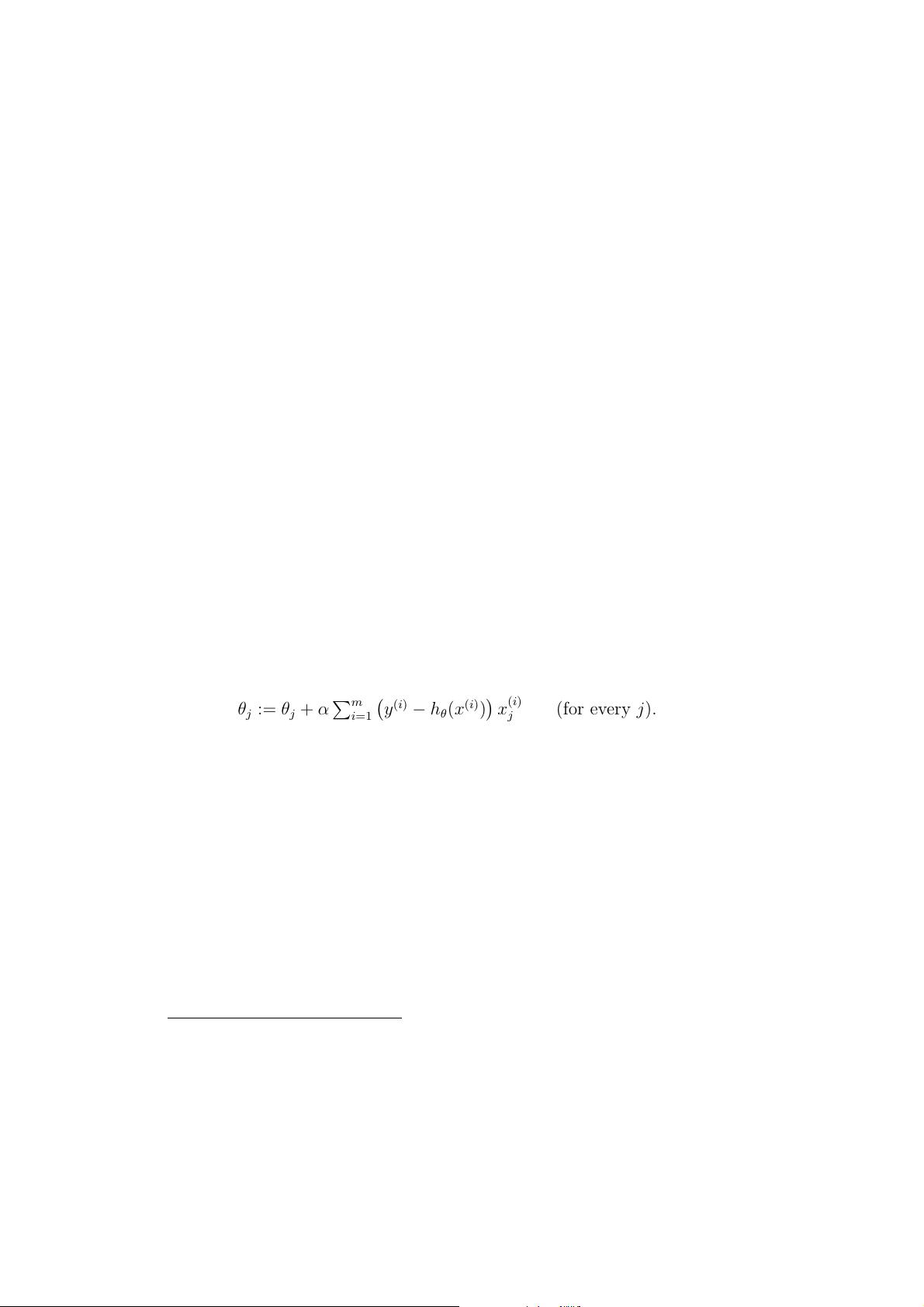
剩余133页未读,继续阅读
资源评论


qiuqiu374
- 粉丝: 1
- 资源: 1









最新资源
- 通道处理过程的模拟通常涉及对通道处理机制的理解与实现.txt
- Flume进阶-自定义拦截器jar包
- Dubins曲线算法讲解和在运动规划中的使用.pdf
- 上市公司-股票性质数据-工具变量(民企、国企、央企)2003-2022年.dta
- 上市公司-股票性质数据-工具变量(民企、国企、央企)2003-2022年.xlsx
- Reeds+Shepp曲线算法讲解和实现.pdf
- 毕业设计基于SpringBoot+MyBatisPlus+MySQL+Vue的外卖配送信息系统源代码+数据库
- 词向量(Word Embeddings)是自然语言处理(NLP)领域的一种重要技术.txt
- Surfer,线性函数
- MyBatis 的动态 SQL 是其核心特性之一.txt
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


