

循环神经网络
尽管 CNNs 能很好的分类图像,其中平移和旋转能关注到,但是它们不能识别时
间模式。根本上,我们可以认为 CNNs 只能认别静态模式。Recurrent neural networks
(RNNs) 是设计来解决认别时间模式的。
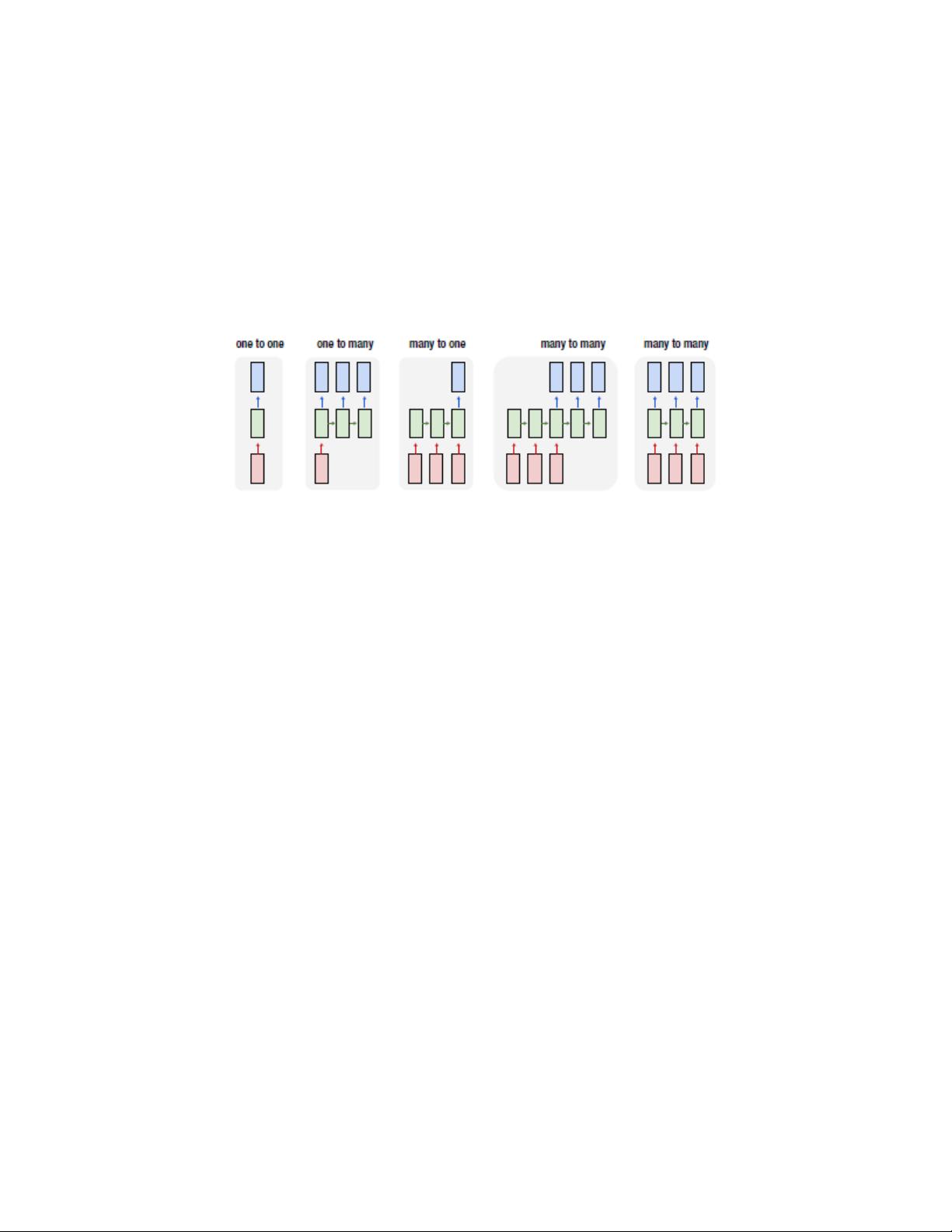
RNNs 与 CNNs 很不同,特别是用来处理序列数据。典型的例子是句子里的词。
你知道句子里的词有很大的不同。例如,“the man ate the
rabbit”与“the rabbit ate the man,”词的顺序不同意思不同,你可以用 RNNs 来
预测句子的下一个词。 例如, “Paris is the capital of ——” 很容易用“
France,”填充,这意味着上一个词可以包含下一个词的信息,这个信息是 RNNs 用
来预测的。名称 recurrent 来自网络是如何工作的:它们对顺列的每一个元素进行
操作,累加前一项的信息。概括一下:
• RNNs 使用顺列数据并使用序列中各项顺序所编码的信息。
• RNNs 对序列中的所有项进行一些操作并记住前一项来预测下一项。
在更好的理解 RNNs 如何工作之前,我们考虑它们使用的一些重要的情形。
•产生文本:给定一系列的词,预测词的概率。你可以用 RNNs 莎士比亚的文本,
如 A. Karpathy 在他的博客所示,见 https://goo.gl/FodLp5。
•翻译:给出一种语言的一系列词,你可以得到不同的语言。
• 语音识别:给出一系列的音频信号,你可以预测词中的字母。
• 产生图像标签:使用 CNNs, RNNs 可以用来产生图像标签。见 A. Karpathy 关
于 “Deep Visual-Semantic Alignments for Generating Image Descriptions,”
的论文,见 https://goo.gl/8Ja3n2。注意,这是很深的论文,需要大量的数学背
景。
• 聊天机器人:以一系列的词作为输入, RNNs 试图回答输入。
如你想像的,要实现上面这些,你要复杂的架构,这不是简单的几句话可以描
述的,且你需要深入的理解 RNNs 是如何工作的。这不是本章和本书的范围。
这一章,我们学习:
• RNN 工作细节



剩余36页未读,继续阅读
资源评论


lishaoan77
- 粉丝: 160
- 资源: 28









最新资源
- 数据分析-19-Thera Bank信贷业务数据(包含数据代码)
- halcon视觉检测之毛刺检测案例
- 数据挖掘-10-酒店预订需求(包含数据和代码)
- gaussian-splatting项目百度网盘资料
- Linxu 5.4版本内核 移植适配正点原子IMX6ULL(2.4版本)开发板
- 数据挖掘-11-利用python进行信用卡欺诈检测(包含数据代码)
- 数据分析-20-宠物小精灵数据挖掘(包含数据代码)
- 巴特沃兹滤波判定正逆转摩擦力矩产品
- 数据分析-21-黑色星期五消费者用户画像(包含数据代码)
- 基于51单片机光控人体感应灯论文
- 该VI为电动助力转向系统,在测试助力状态下输入输出曲线时,曲线的对称度算法
- 【完结21章附电子书】2024全新GO工程师面试总攻略,助力快速斩获offer
- 基于QT/C++开发的WEB框架
- 桥梁地震易损性分析中的Python随机森林算法应用-含代码及使用解释
- 修改Hosts文件,解决IP与电脑名称绑定,或屏蔽某些网站访问
- 数据分析-22-双12活动前后(包含数据代码)
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


