Tensorflow卷积神经网络详解
需积分: 5 76 浏览量
2023-05-08
11:17:36
上传
评论 1
收藏 1.55MB DOCX 举报


卷积神经网络
传统神经网络的一个局限是它对于图像平移变换--即一个猫在右上角的图
片与猫在中心的图片是不同对待的。卷积神经网络 Convolutional neural
networks (CNNs)用于处理这种问题 。
因为 CNN 可以处理图像的平移,它被认为很有用,而且 CNN 架构被
认为是目标识别/检测最选进的技术。
这一章我们学习如下知识:
•
CNN 的工作细节
•
CNN 如何改时传统神经网络的缺点
•
卷积和池化对于图像平移的影响
•
如何用 python 实现 CNN
要理解为什么需要CNN,我们从一个例子开始。假如我们要分类一张图像里
是否有垂直的线 (可能是告诉我们是否有 1 存在)。 为了简单起见,我们假定图
像是 5 × 5 像素大小的。垂直的线(数字 1)可以用一些方法表示 :
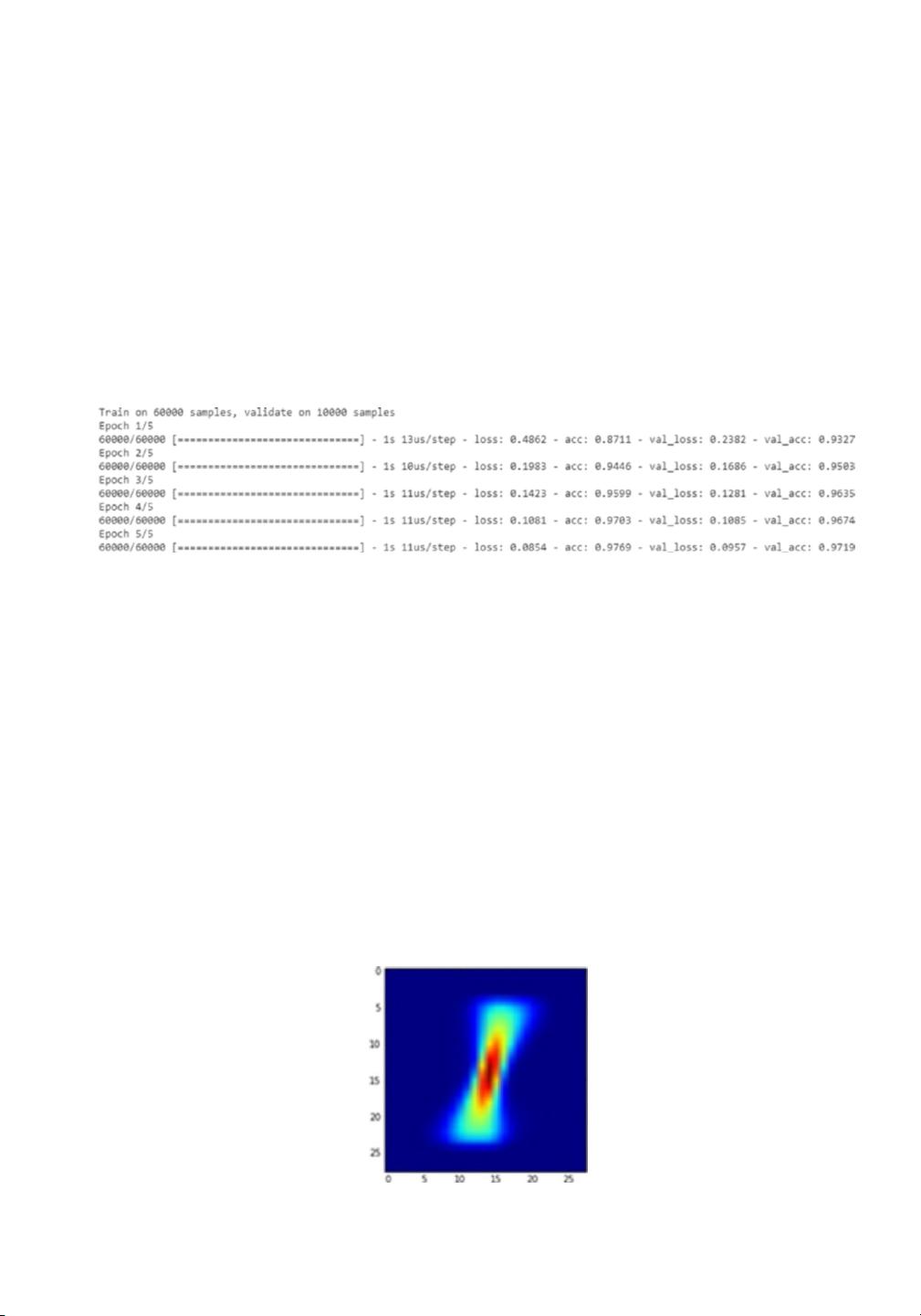
我们也可以检查 MNIST 数据集里数字 1 的不同表示方法。一张数字 1 的图片见
图 9-1。



剩余30页未读,继续阅读
资源评论













