
利用利用TensorFlow训练简单的二分类神经网络模型的方法训练简单的二分类神经网络模型的方法
本篇文章主要介绍了利用TensorFlow训练简单的二分类神经网络模型的方法,小编觉得挺不错的,现在分享给
大家,也给大家做个参考。一起跟随小编过来看看吧
利用TensorFlow实现《神经网络与机器学习》一书中4.7模式分类练习
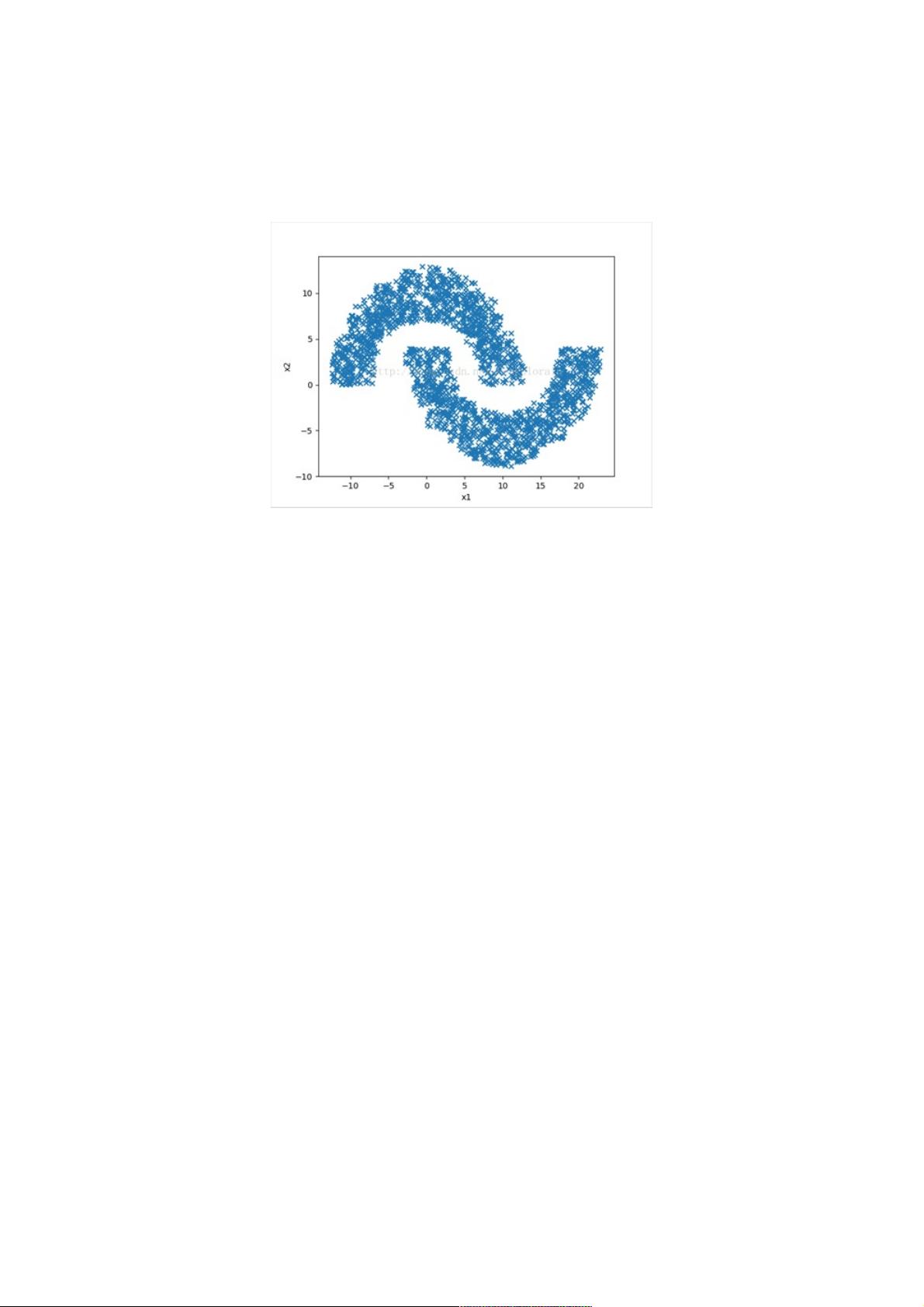
具体问题是将如下图所示双月牙数据集分类。
使用到的工具使用到的工具:
python3.5 tensorflow1.2.1 numpy matplotlib
1.产生双月环数据集产生双月环数据集
def produceData(r,w,d,num):
r1 = r-w/2
r2 = r+w/2
#上半圆
theta1 = np.random.uniform(0, np.pi ,num)
X_Col1 = np.random.uniform( r1*np.cos(theta1),r2*np.cos(theta1),num)[:, np.newaxis]
X_Row1 = np.random.uniform(r1*np.sin(theta1),r2*np.sin(theta1),num)[:, np.newaxis]
Y_label1 = np.ones(num) #类别标签为1
#下半圆
theta2 = np.random.uniform(-np.pi, 0 ,num)
X_Col2 = (np.random.uniform( r1*np.cos(theta2),r2*np.cos(theta2),num) + r)[:, np.newaxis]
X_Row2 = (np.random.uniform(r1 * np.sin(theta2), r2 * np.sin(theta2), num) -d)[:,np.newaxis]
Y_label2 = -np.ones(num) #类别标签为-1,注意:由于采取双曲正切函数作为激活函数,类别标签不能为0
#合并
X_Col = np.vstack((X_Col1, X_Col2))
X_Row = np.vstack((X_Row1, X_Row2))
X = np.hstack((X_Col, X_Row))
Y_label = np.hstack((Y_label1,Y_label2))
Y_label.shape = (num*2 , 1)
return X,Y_label
其中r为月环半径,w为月环宽度,d为上下月环距离(与书中一致)
2.利用利用TensorFlow搭建神经网络模型搭建神经网络模型
2.1 神经网络层添加
def add_layer(layername,inputs, in_size, out_size, activation_function=None):
# add one more layer and return the output of this layer
with tf.variable_scope(layername,reuse=None):
Weights = tf.get_variable("weights",shape=[in_size, out_size],
initializer=tf.truncated_normal_initializer(stddev=0.1))
biases = tf.get_variable("biases", shape=[1, out_size],
initializer=tf.truncated_normal_initializer(stddev=0.1))
Wx_plus_b = tf.matmul(inputs, Weights) + biases
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
return outputs
资源评论


weixin_38685831
- 粉丝: 8
- 资源: 874









最新资源
- 【TCN回归预测】TCN时间卷积神经网络数据回归预测(多输入单输出)【含Matlab源码 2317期】.zip
- 【电力负荷预测】EEMD+IWOA+LSSVM电力负荷预测【含Matlab源码 1810期】.zip
- c语言入门,简要的写明c语言的入门
- 永磁同步直线电机PMLSM矢量控制滑模控制SVPWM仿真模型的研究 外环控制器:PI与滑膜控制策略的效果分析与三相电流波形优化,永磁同步直线电机PMLSM矢量控制滑模控制SVPWM仿真模型的研究 外环
- 2025易支付新版PHP网站源码.zip
- Magic Formula与Dugoff模型MF模型对比实验的Matlab建模与程序代码,含纯纵滑、纯侧偏及复合工况Simulink仿真,Magic Formula与Dugoff模型对比实验的Matl
- 这个是有关于ppocr4的使用推理模型
- comsol技术引领的双目标函数流热优化与液冷板结构设计的融合探讨,关注最小化平均温度与最小流体功率耗散的无量纲化案例及参考文献分享交流 ,双目标函数流热优化在液冷板结构设计中的应用-最小化平均温度
- 基于`typecho开发的导航源码-BeaconNav 导航主题
- 基于NSDBO算法的MATLAB多目标优化程序包-集成多种测试函数与评价指标的工程应用案例研究,NSDBO算法的Matlab实现:多目标测试函数与评价指标的全面研究及工程应用案例,非支配排序多目标蜣
- 房地产营改增税负率测算表
- 永磁同步直线电机PMLSM矢量控制滑模控制SVPWM仿真模型研究:外环控制器性能分析与三相电流波形优化(附参考文献),永磁同步直线电机PMLSM矢量控制滑模控制SVPWM仿真模型研究-外环控制器性能
- 电气安全知识问答-11003559.pdf
- sql语言的入门教程 欢迎下载
- 基于ECMS和EEMS控制策略的燃料电池能量管理仿真模型研究:多电动飞机应急电源系统分析,基于ECMS和EEMS策略的燃料电池能量管理系统的仿真与效果对比,基于ECMS控制策略的燃料电池能量管理 仿真
- 利用新算法PD近场动力学技术模拟三维复杂裂纹扩展过程:深入探索与精准预测,利用新算法PD模拟三维复杂裂纹扩展:近场动力学的创新应用与实践,用新算法pd 近场动力学模拟三维复杂裂纹扩展 ,核心关键词:新
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


