
.
1 / 3
《统计分析与 SPSS 的应用(第五版)》(薛薇)
课后练习答案
第 2 章 SPSS 数据文件的建立和管理
1、SPSS 中有哪两种基本的数据组织形式?各自的特点和应用场合是什么?
SPSS 中两个基本的数据组织方式:原始数据的组织方式和计数数据的组织方式。
原始数据的组织方式:待分析的数据是一些原始的调查问卷数据,或是一些基本的
统计指标。
计数数据的组织方式:所采集的数据不是原始的调查问卷数据,而是经过分组汇总
后的数据。
2、什么是 SPSS 的个案?什么 SPSS 的变量?
个案:在原始数据的组织方式中,数据编辑器窗口中的一行称为一个个案或观测。
变量:数据编辑器窗口中的一列。
3、在定义 SPSS 数据结构时,默认的变量名和变量类型是什么?如果希望增强 SPSS 统计分
析结果的易读性,还需要对数据结构的哪些方面进行必要说明?
默认的变量名:VAR------;默认的变量类型:数值型。
变量名标签和变量值标签可增强统计分析结果的可读性。
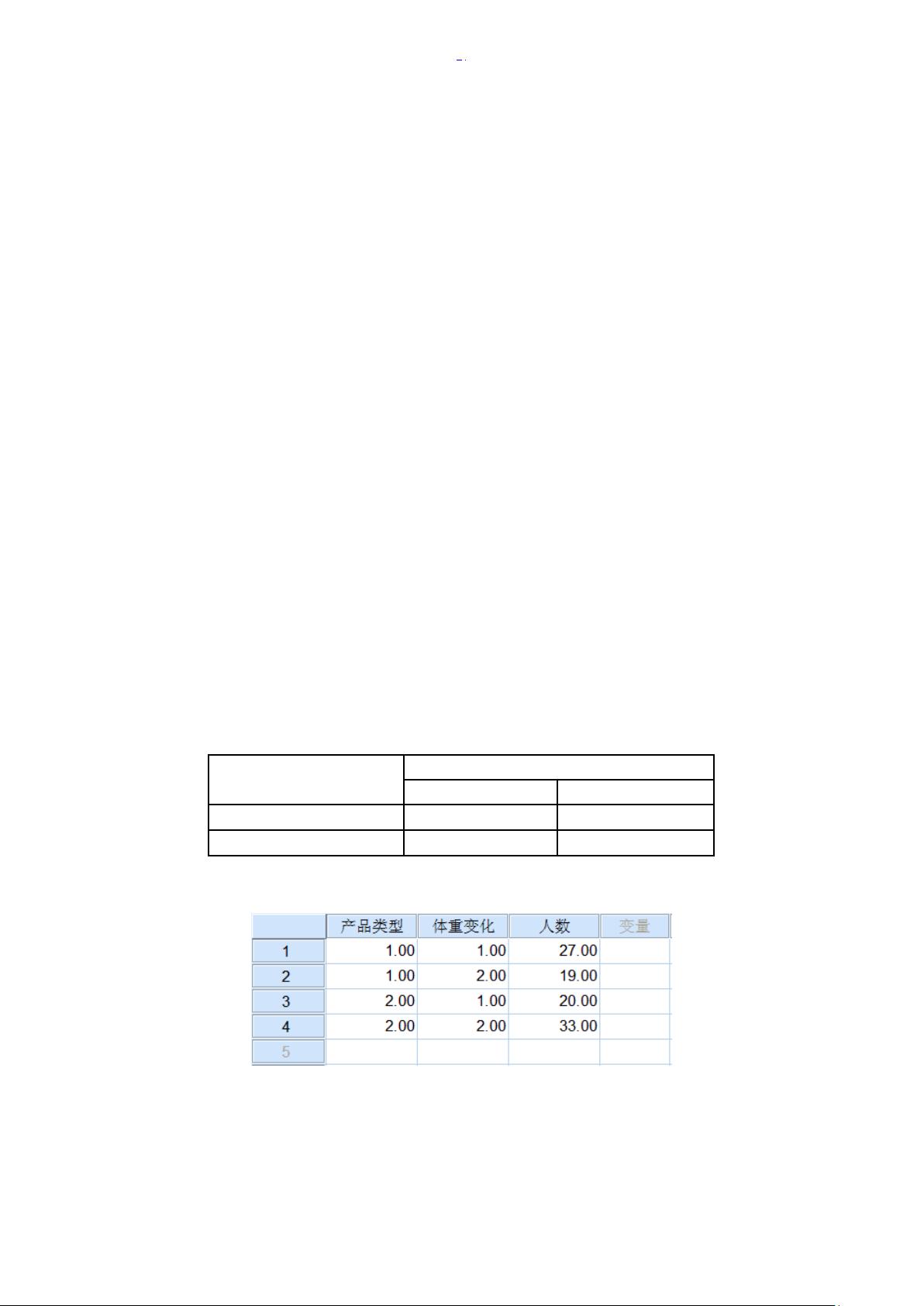
4、收集到以下关于两种减肥产品试用情况的调查数据,请问在 SPSS 中应如何组织该份资
料?
体重变化情况
产品类型
明显减轻
无明显变化
第一种产品
27
19
第二种产品
20
33
问:在 SPSS 中应如何组织该数据?
数据文件如图所示:
5、什么是 SPSS 的用户缺失值?为什么要对用户缺失值进行定义?如何在 SPSS 中指定用户
缺失值?
缺失值分为用户缺失值(User Missing Value)和系统缺失值(System Missing
Value)。用户缺失值指在问卷调查中,将无回答的一些数据以及明显失真的数据当作缺失值
资源评论


huayuya123
- 粉丝: 26
- 资源: 31万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


