

《大数据处理技术》实验报告
学号
姓名
班级
日期
实验名称: 实验 4 MapReduce 编程实践
实验目的:
1.通过实验掌握基本的 MapReduce 编程方法;
2.掌握用 MapReduce 解决一些常见的数据处理问题,包括数据去重、数据排序和数据挖掘
等。
实验内容与完成情况:
实验内容和要求:
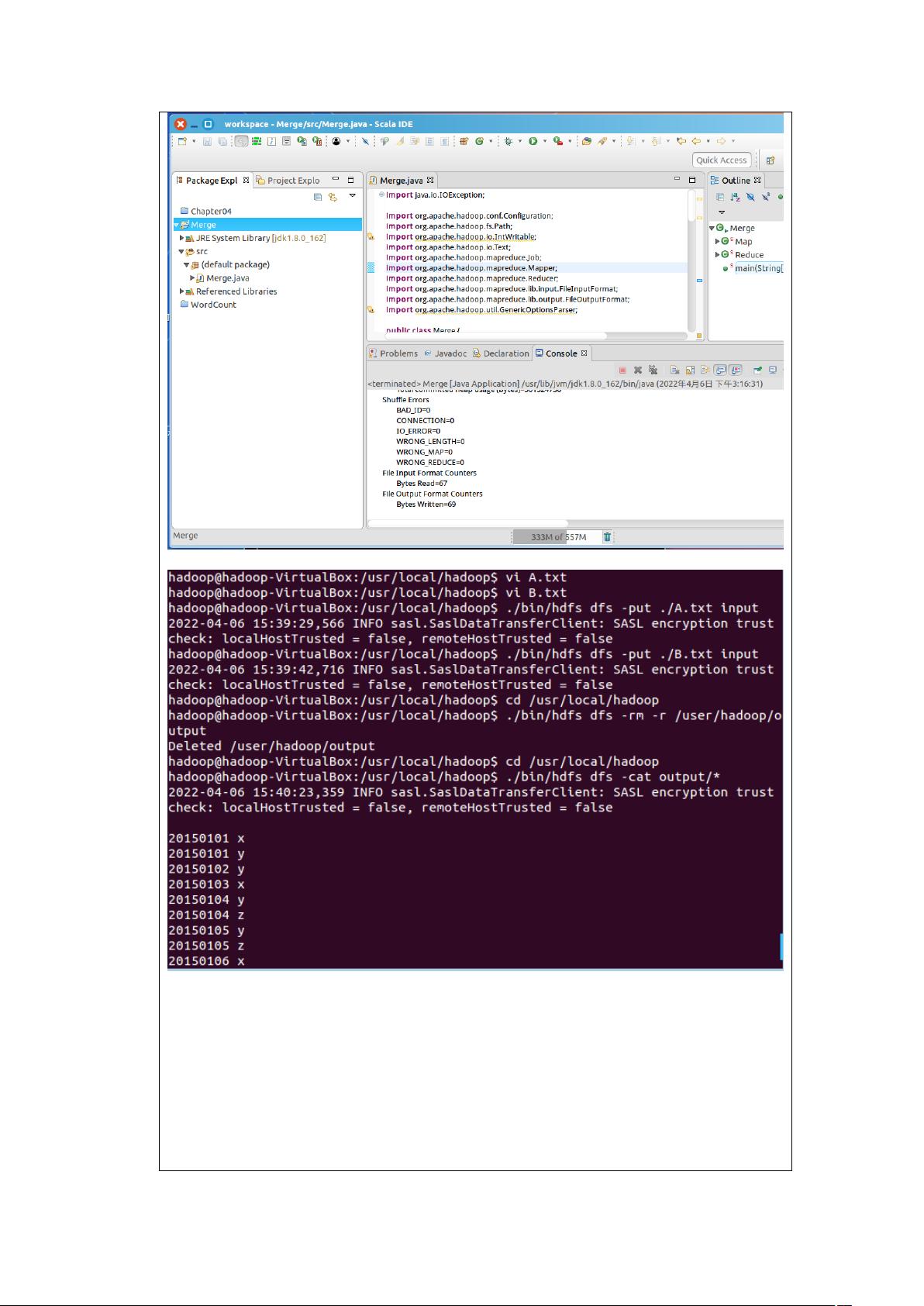
(1)编程实现文件合并和去重操作
对于两个输入文件,即文件 A 和文件 B,请编写 MapReduce 程序,对两个文件进行合并,
并剔除其中重复的内容,得到一个新的输出文件 C。下面是输入文件和输出文件的一个样
例供参考。
输入文件 A 的样例如下:
20150101 x
20150102 y
20150103 x
20150104 y
20150105 z
20150106 x
输入文件 B 的样例如下:
20150101 y
20150102 y
20150103 x
20150104 z
20150105 y
根据输入文件 A 和 B 合并得到的输出文件 C 的样例如下:
20150101 x
20150101 y
20150102 y
20150103 x
20150104 y
20150104 z
20150105 y
20150105 z
20150106 x
剩余7页未读,继续阅读
资源评论













