模式识别期末试题
版权申诉


第 1 页 共 26 页
模式识别期末试题
一、 填空与选择填空(本题答案写在此试卷上,30 分)
1、模式识别系统的基本构成单元包括: 模式采集 、 特征提取与选择
和 模式分类 。
2、统计模式识别中描述模式的方法一般使用 特真矢量 ;句法模式识别中模式描述方法一般有 串 、
树 、 网 。
3、聚类分析算法属于 (1) ;判别域代数界面方程法属于 (3) 。
(1)无监督分类 (2)有监督分类 (3)统计模式识别方法(4)句法模式识别方法
4、若描述模式的特征量为 0-1 二值特征量,则一般采用 (4) 进行相似性度量。
(1)距离测度 (2)模糊测度 (3)相似测度 (4)匹配测度
5、 下列函数可以作为聚类分析中的准则函数的有 (1)(3)(4) 。
(1) (2) (3)
(4)
6、Fisher 线性判别函数的求解过程是将 N 维特征矢量投影在 (2) 中进行 。
(1)二维空间 (2)一维空间 (3)N-1 维空间
7、下列判别域界面方程法中只适用于线性可分情况的算法有 (1) ;线性可分、不可分都适用的有
(3) 。
(1)感知器算法 (2)H-K 算法 (3)积累位势函数法
8、下列四元组中满足文法定义的有 (1)(2)(4) 。
(1)({
A
,
B
}, {0, 1}, {
A
�01,
A
� 0
A
1 ,
A
� 1
A
0 ,
B
�
BA
,
B
� 0},
A
)
(2)({
A
}, {0, 1}, {
A
�0,
A
� 0
A
},
A
)
(3)({
S
}, {
a
,
b
}, {
S
� 00
S
,
S
� 11
S
,
S
� 00,
S
� 11},
S
)
(4)({
A
}, {0, 1}, {
A
�01,
A
� 0
A
1,
A
� 1
A
0},
A
)
9、影响层次聚类算法结果的主要因素有( 计算模式距离的测度、(聚类准则、类间距离门限、预定的
类别数目))。
10、欧式距离具有( 1、2 );马式距离具有( 1、2、3、4 )。
(1)平移不变性(2)旋转不变性(3)尺度缩放不变性(4)不受量纲影响的特性
11、线性判别函数的正负和数值大小的几何意义是(正(负)表示样本点位于判别界面法向量指向的
正(负)半空间中;绝对值正比于样本点到判别界面的距离。)。
12、感知器算法 1 。
(1)只适用于线性可分的情况;(2)线性可分、不可分都适用。

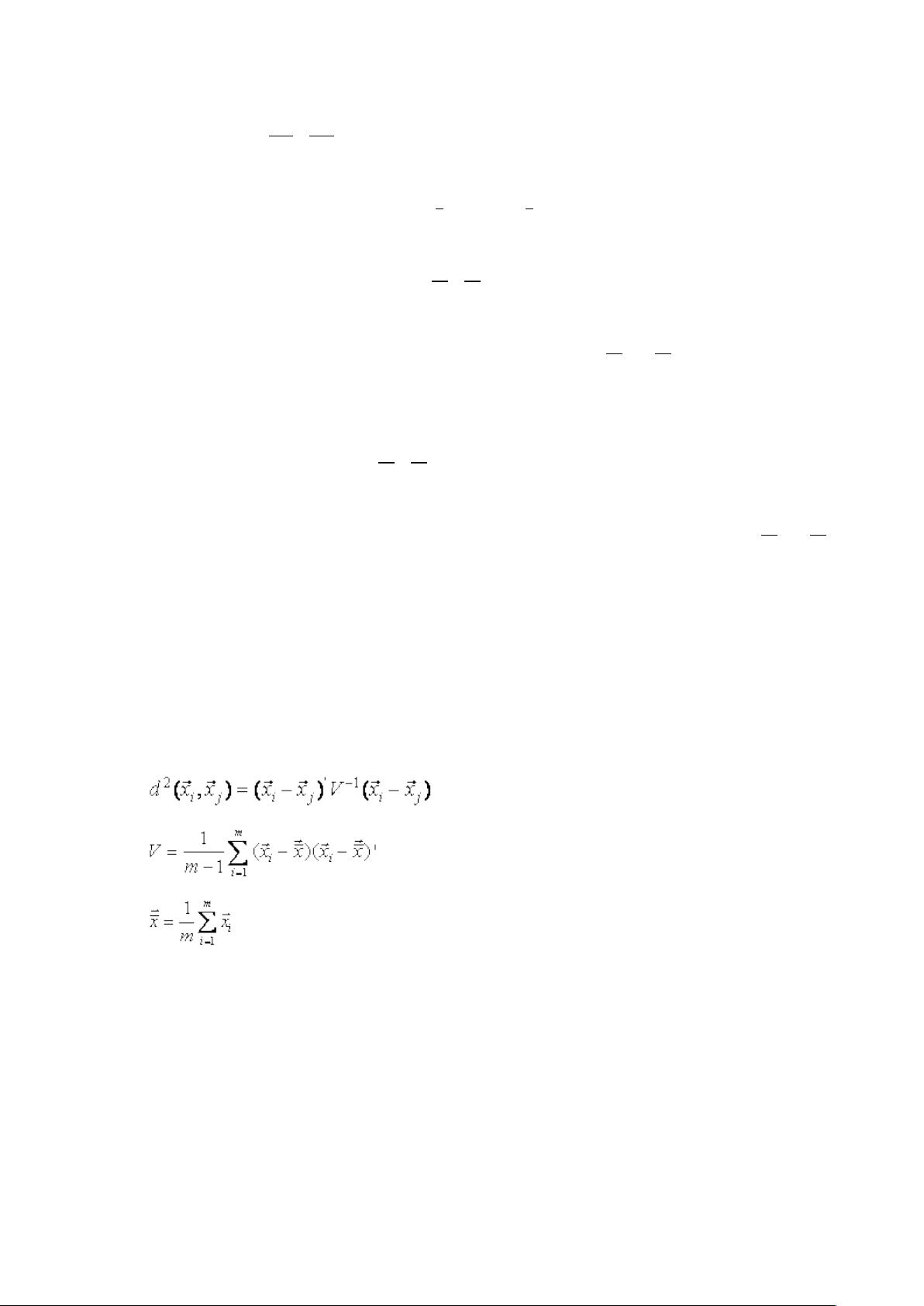


剩余25页未读,继续阅读






评论1
最新资源