3、ClickHouse表引擎-MergeTree引擎
需积分: 0 179 浏览量
2023-05-29
10:17:29
上传
评论
收藏 838KB PDF 举报


ClickHouse系列文章
1、ClickHouse介绍
2、clickhouse安装与简单验证(centos)
3、ClickHouse表引擎-MergeTree引擎
4、clickhouse的Log系列表引擎、外部集成表引擎和其他特殊的表引擎介绍及使用
5、ClickHouse查看数据库容量、表的指标、表分区、数据大小等
@TOC
本文主要介绍MergeTree引擎的几种情况,每种都有具体的使用示例。
本文使用前提参考该系列文章中的部署与验证。
本文主要分为二部分,即ClickHouse的表引擎介绍和MergeTree引擎几种引擎介绍。
Clickhouse是一个高性能且开源的数据库管理系统,主要用于在线分析处理(OLAP)业务。它采用列式存
储结构,可使用SQL语句实时生成数据分析报告,另外它还支持索引,分布式查询以及近似计算等特
性,凭借其优异的表现,ClickHouse在各大互联网公司均有广泛地应用。
官网:https://clickhouse.com/
中文官网:https://clickhouse.com/docs/zh
一、ClickHouse的表引擎介绍
ClickHouse的表引擎是ClickHouse服务的核心,主要提供的功能如下:
数据的存储方式和位置
支持哪些查询操作以及如何支持
数据的并发访问
数据索引的使用
是否可以支持多线程请求
是否可以支持数据复制
ClickHouse包含以下几种常用的引擎类型:
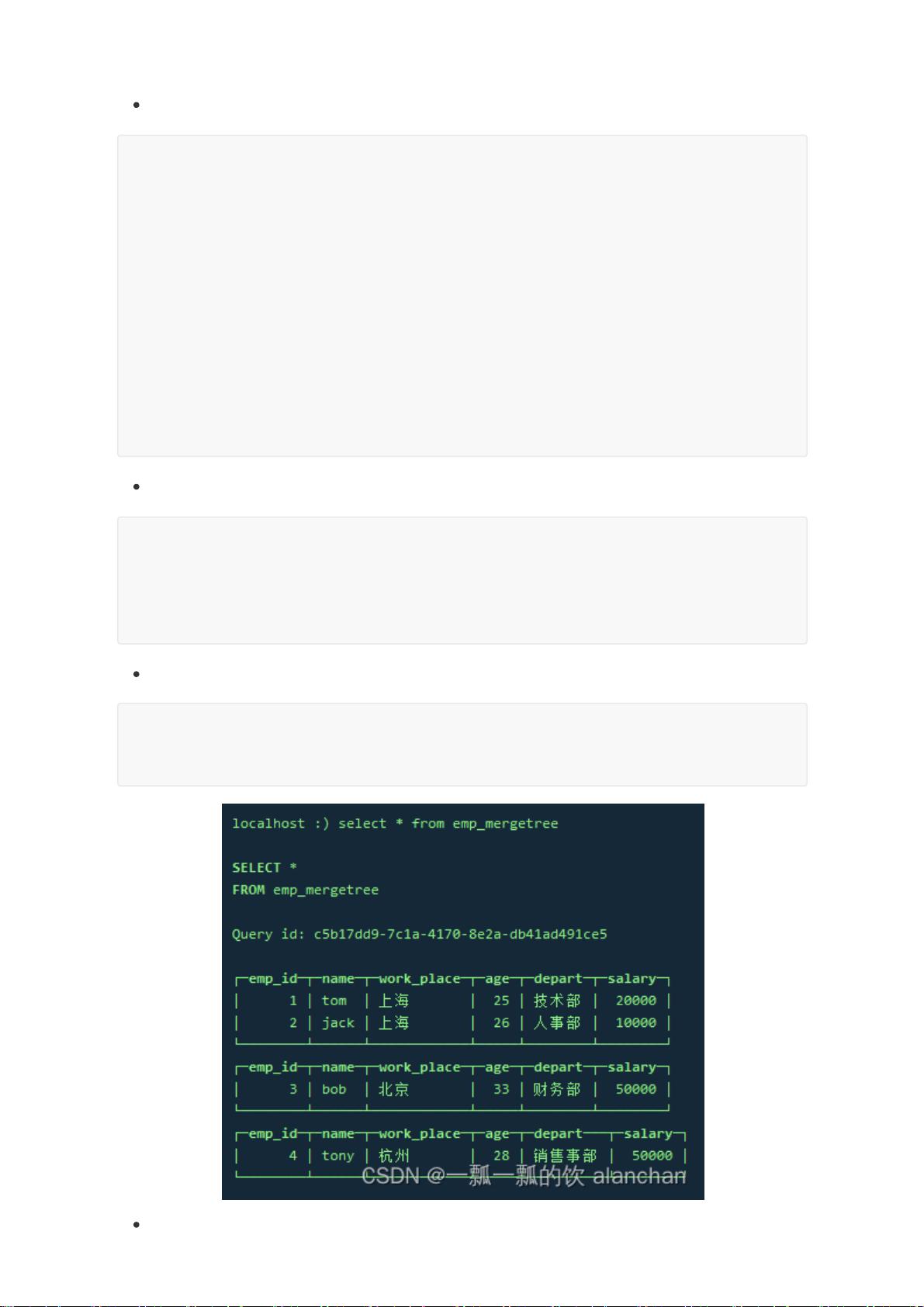
1. MergeTree引擎
该系列引擎是执行高负载任务的最通用和最强大的表引擎,它们的特点是可以快速插入数据以及进行后
续的数据处理。该系列引擎还同时支持数据复制(使用Replicated的引擎版本),分区(partition)以及一
些其它引擎不支持的额外功能。
2. Log引擎
该系列引擎是具有最小功能的轻量级引擎。当你需要快速写入许多小表(最多约有100万行)并在后续
任务中整体读取它们时使用该系列引擎是最有效的。
3. 集成引擎
该系列引擎是与其它数据存储以及处理系统集成的引擎,如Kafka,MySQL以及HDFS等,使用该系列引
擎可以直接与其它系统进行交互,但也会有一定的限制。
4. 特殊引擎
剩余18页未读,继续阅读
资源评论













