Kafka详解及常见面试问题解析(值得珍藏)
需积分: 5 79 浏览量
2024-01-17
00:06:24
上传
评论
收藏 2.2MB PDF 举报


1. 定义
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。它是一种高吞吐量的分布式
发布订阅消息系统,可以处理消费者在网站中的所有动作流数据。这种动作(网页浏览,搜索和其他用户的
行动)是在现代网络上的许多社会功能的一个关键因素。这些数据通常是由于吞吐量的要求而通过处理日志
和日志聚合来解决。对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个
可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过
集群来提供实时的消息。
1.1 消息队列
Kafka 本质上是一个 MQ(Message Queue),使用消息队列的好处?
1.解耦:允许我们独立的扩展或修改队列两边的处理过程。
2.可恢复性:即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
3.缓冲:有助于解决生产消息和消费消息的处理速度不一致的情况。
4.灵活性&峰值处理能力:不会因为突发的超负荷的请求而完全崩溃,消息队列能够使关键组件顶住突发的
访问压力。
5.异步通信:消息队列允许用户把消息放入队列但不立即处理它。
1.2 发布/订阅模式
一对多,生产者将消息发布到 topic 中,有多个消费者订阅该主题,发布到 topic 的消息会被所有订阅者消
费,被消费的数据不会立即从 topic 清除。
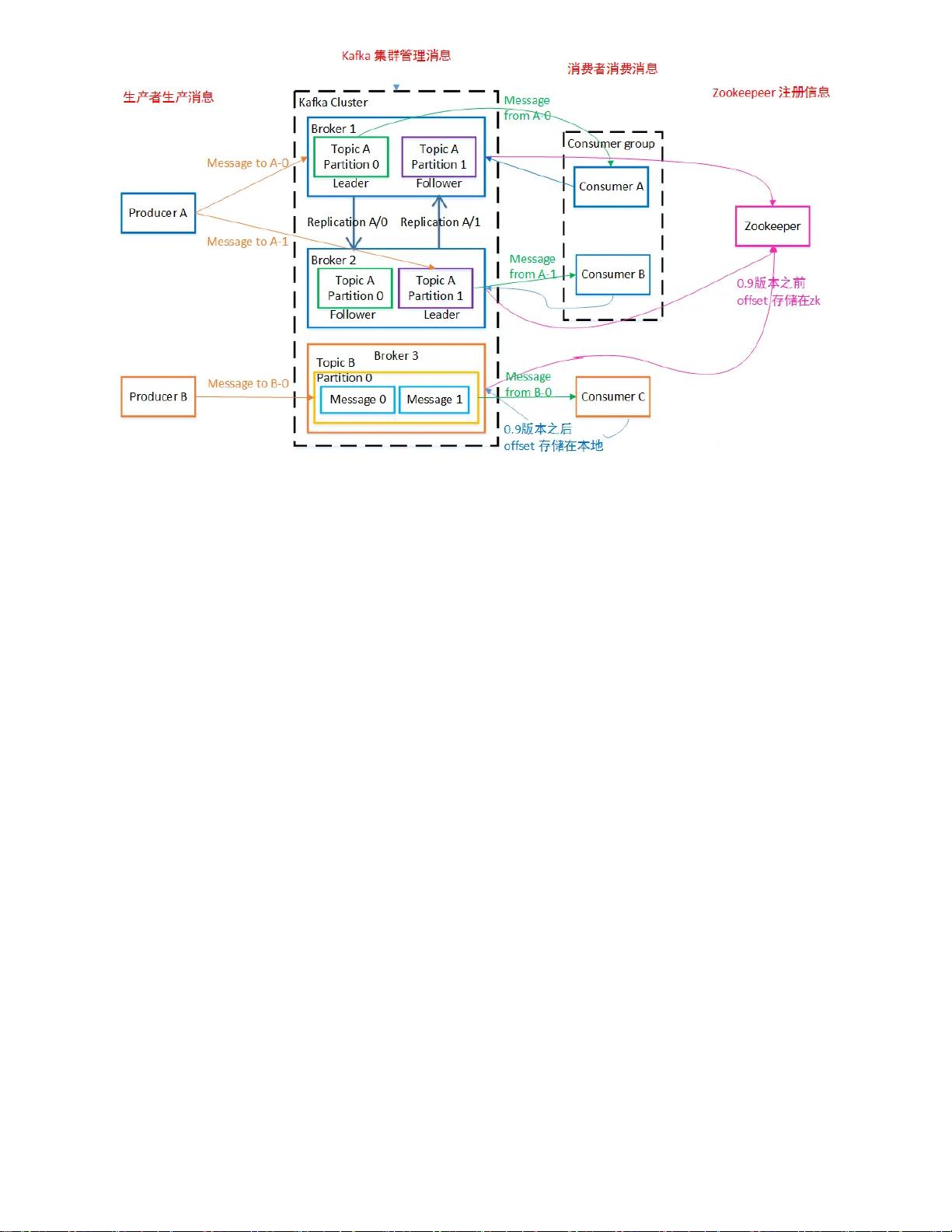
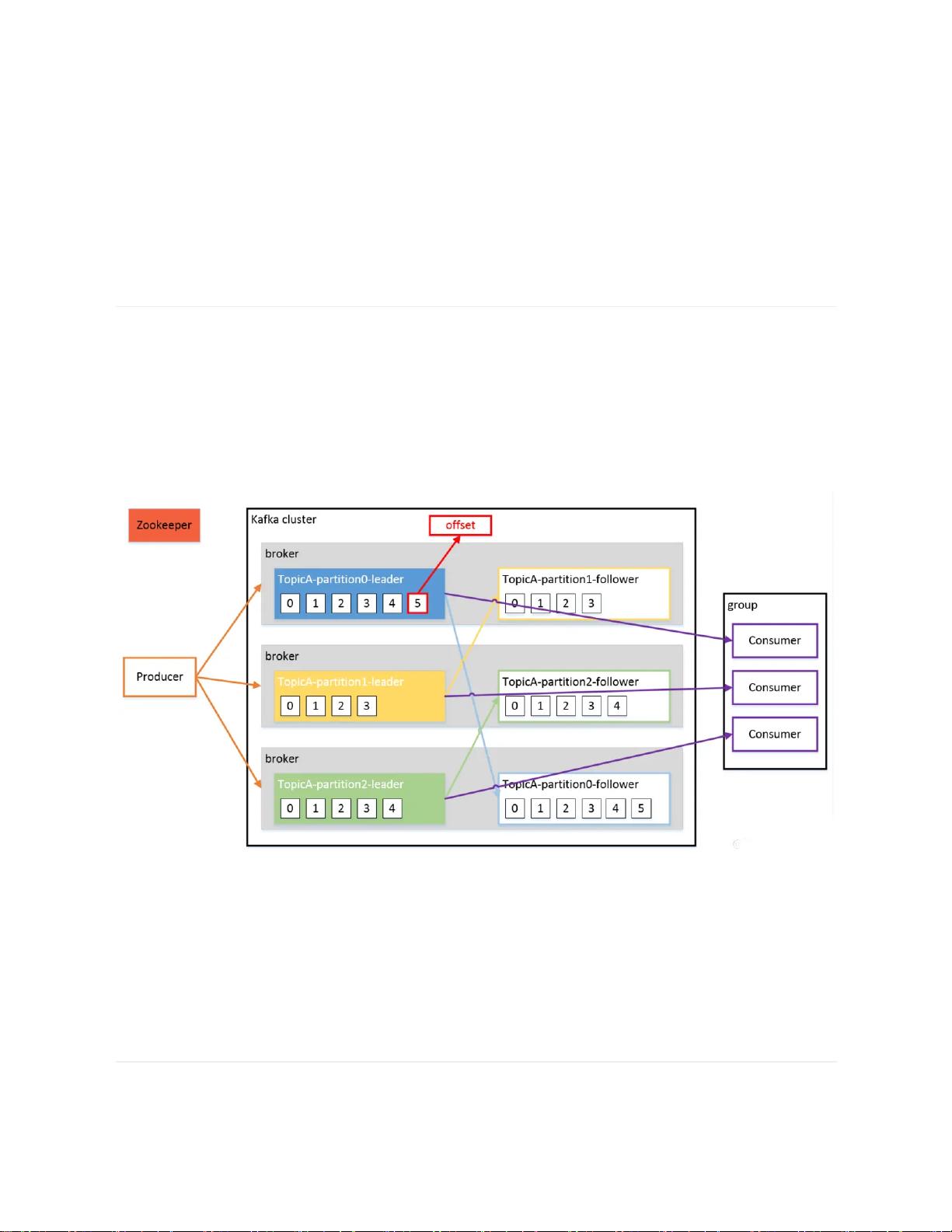
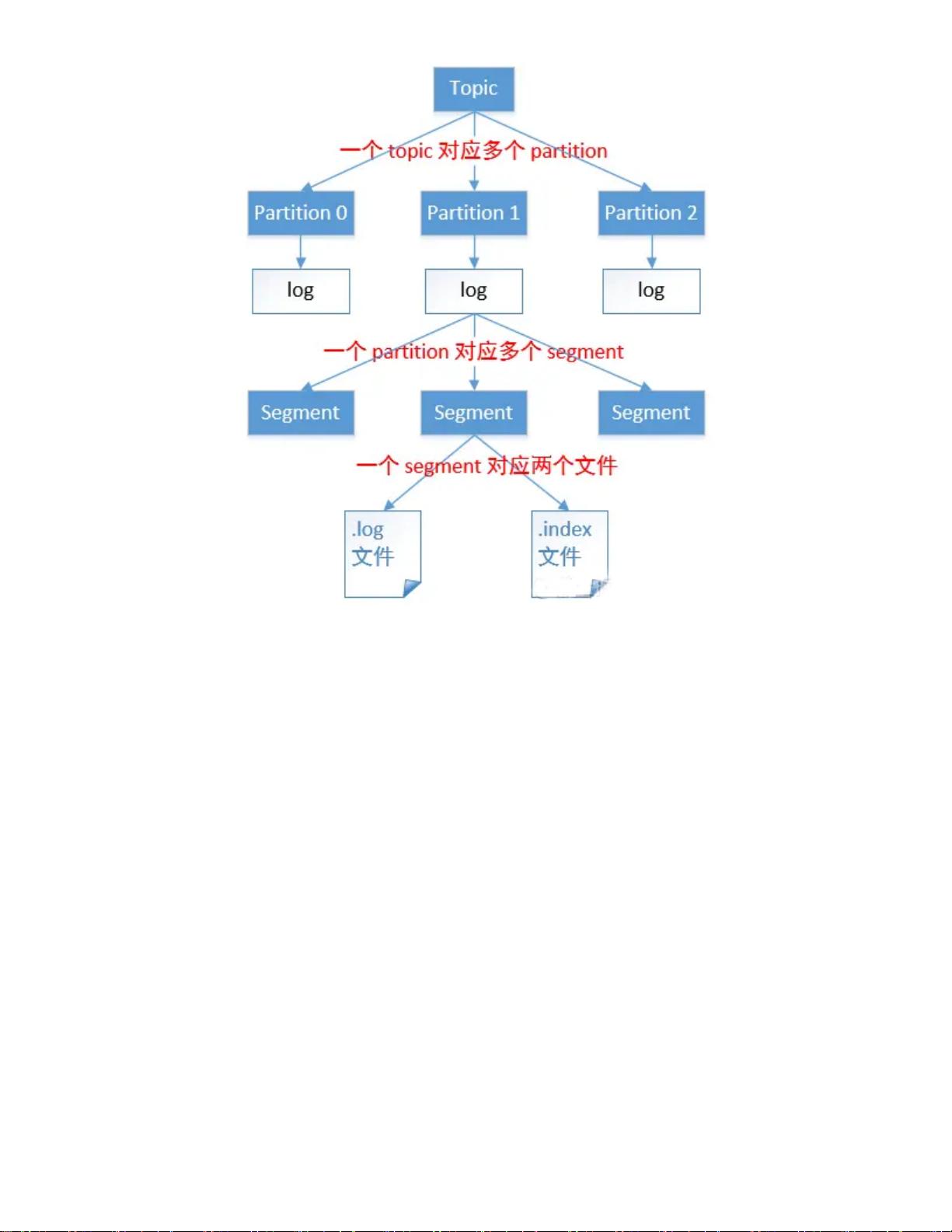
2. 架构
剩余17页未读,继续阅读
资源评论













