
概念和架构
描述⼀下kafka 的架构
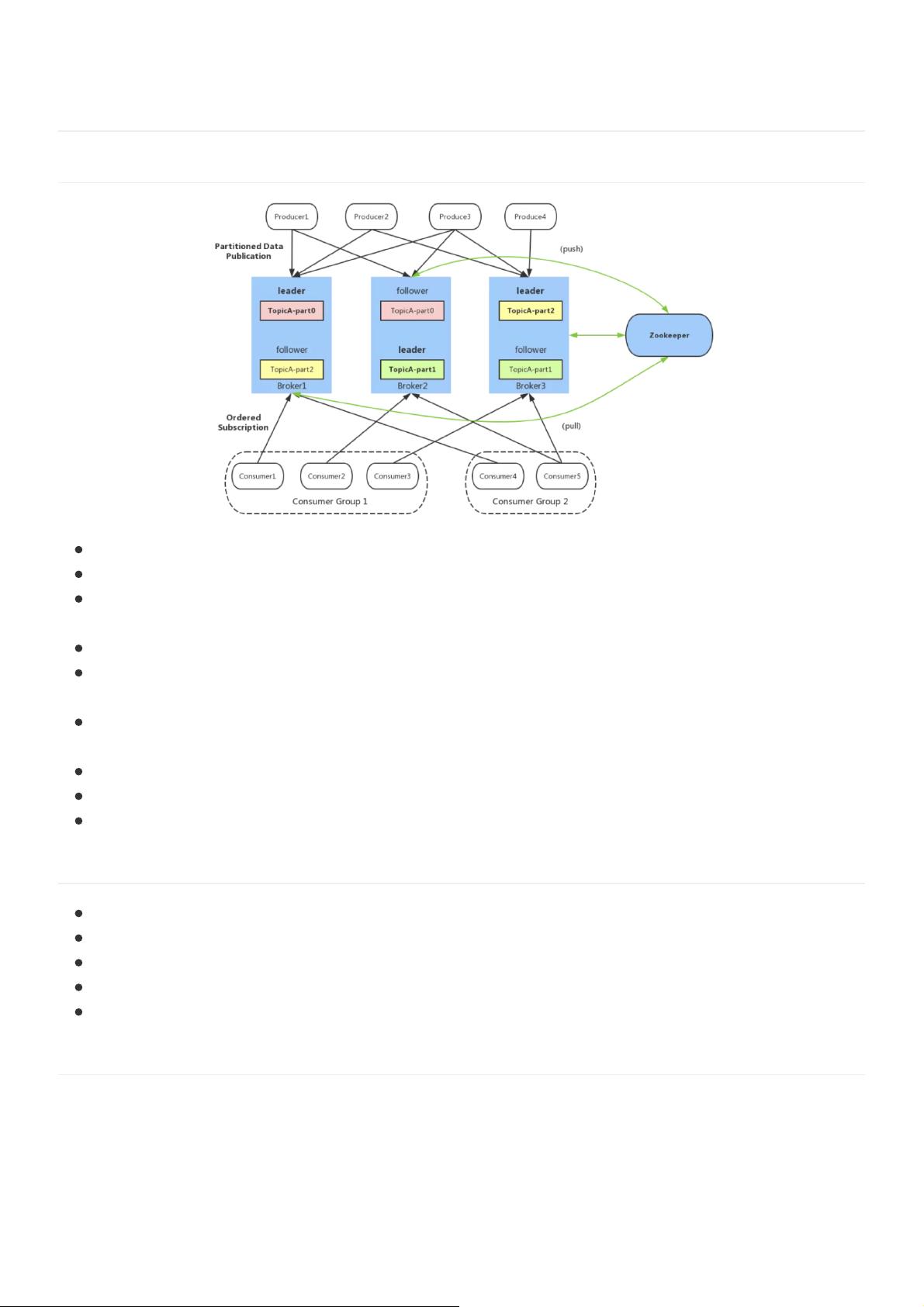
Producer:消息⽣产者,负责创建消息,然后将其发送到 Kafka
Consumer:消费者,连接到 Kafka上并接收消息,进⽽进⾏相应的业务逻辑处理
Consumer Group:每个Consumer都属于⼀个Consumer Group,每条消息只能被Consumer Group中的
⼀个Consumer消费,但可以被多个Consumer Group消费。
Broker:⼀个 Kafka 节点就是⼀个Broker,多个Broker可以组成⼀个Kafka 集群。
Topic:Kafka 中的消息以Topic为单位进⾏划分,⽣产者将消息发送到特定的 Topic,⽽消费者负责订阅
Topic 的消息并进⾏消费。
Partition:Partition 是Topic在物理上的分区,⼀个Topic可以分为多个Partition,每个Partition是⼀个有序
的不可变的记录序列。单⼀主题中的分区有序,但⽆法保证主题中所有分区的消息有序。
Replica:Partition 的副本,⽤来保障Partition的⾼可⽤性。
Controller: Kafka 集群中的其中⼀个服务器,⽤来进⾏Leader election以及各种 Failover 操作。
Zookeeper:Kafka 通过Zookeeper来存储集群中的 meta 消息
说⼀下kafka的使⽤场景
系统解耦:在重要操作完成后,发送消息,由别的服务系统来完成其他操作
流量削峰:⼀般⽤于秒杀或抢购活动中,来缓冲⽹站短时间内⾼流量带来的压⼒
异步处理:通过异步处理机制,可以把⼀个消息放⼊队列中,但不⽴即处理它,在需要的时候再进⾏处理
⽇志聚合:可收集各种服务的⽇志写⼊kafka的消息队列进⾏存储
⼤数据实时计算:Kafka 提供了⼀套完整的流式处理框架,被⼴泛应⽤到⼤数据处理中
和其他消息队列相⽐,Kafka的优势在哪⾥?
1. 极致的性能 :基于Pull的模式来处理消息消费,追求⾼吞吐量,设计中⼤量使⽤了批量处理和异步的思想,最
⾼可以每秒处理千万级别的消息。
2. ⽣态系统兼容性⽆可匹敌 :Kafka 与周边⽣态系统的兼容性是最好的没有之⼀,尤其在⼤数据和流计算领
域。
Kafka 与 RocketMQ在选型时如何考虑
资源评论


编程芝士
- 粉丝: 2w+
- 资源: 15









最新资源
- 3dmmods_倾城系列月白_by_白嫖萌新.zip
- springboot-教务管理系统(编号:62528147).zip
- Linux下的cursor安装包
- 五相电机双闭环矢量控制模型-采用邻近四矢量SVPWM-MATLAB-Simulink仿真模型包括: (1)原理说明文档(重要):包括扇区判断、矢量作用时间计算、矢量作用顺序及切时间计算、PWM波的生成
- 基于JavaScript的在线考试系统(编号:65965158)(1).zip
- 指针扫描和内存遍历二合一工具
- 青龙燕铁衣-数据集.zip
- 组播报文转发原理的及图解实例
- Java答题期末考试必须考
- 量化交易-RSI策略(vectorbt实现)
- install_dmt.apk
- 1_烽火HG680-KA-mv310(四川湖北湖南新疆河北山东甘肃等)免拆固件.zip
- typora免费正版安装包
- GZ036 区块链技术应用赛项赛题第1套附件.zip
- 用Excel表体验梯度下降法
- 用Excel表体验梯度下降法,附带标识版本
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


