Transformer原理到实践详解
-Transformer:⼀种完全基于Attention机制来加速深度学习训练过程的算法模型;
Transformer最⼤的优势在于其在并⾏化处理上做出的贡献。
Transformer在Goole的⼀篇论⽂Attention is All You Need被提出,为了⽅便实现调⽤Transformer Google还开源了⼀个第三⽅库,
基于TensorFlow的Tensor2Tensor,⼀个NLP的社区研究者贡献了⼀个Torch版本的⽀持:guide annotating the paper with PyTorch
implementation。
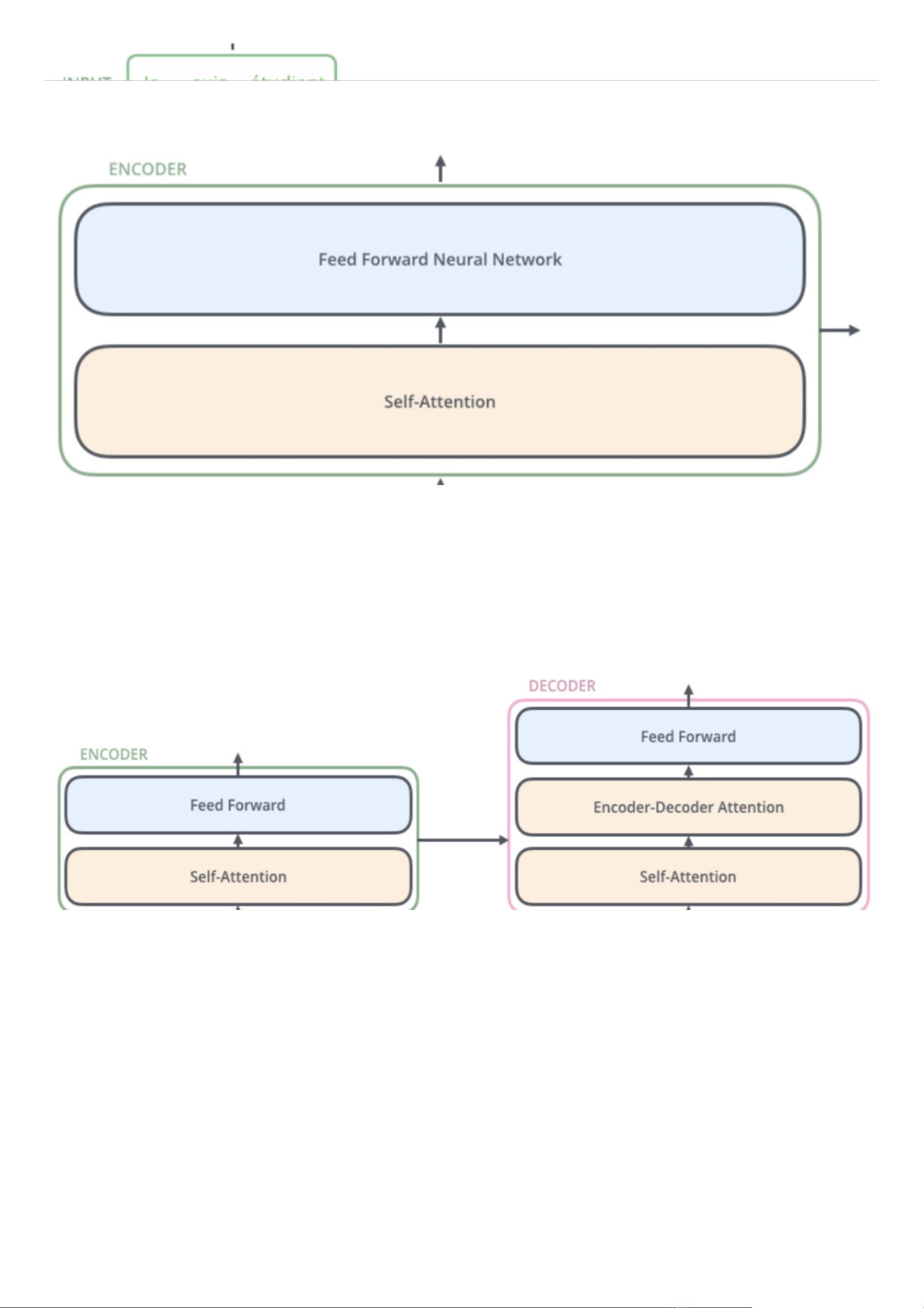
⽹络结构
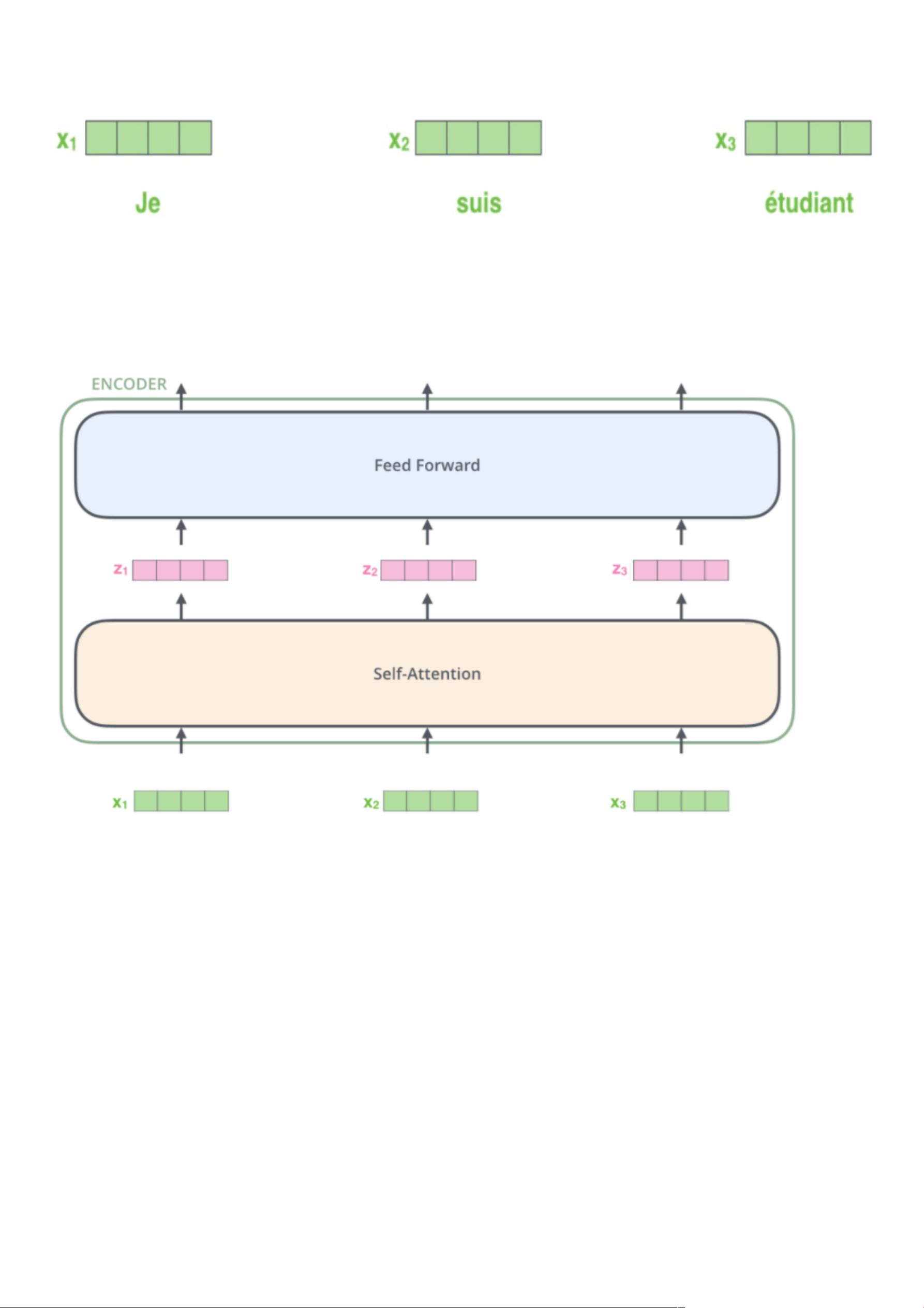
transformer由2个部分组成,⼀个Encoders和⼀个Decoders。
(如下实例,机器翻译:输⼊⼀种语⾔,经transformer之后输出其英⽂表⽰)
每个Encoders中分别由6个Encoder组成,⽽每个Decoders中同样也是由6个Decoder组成。