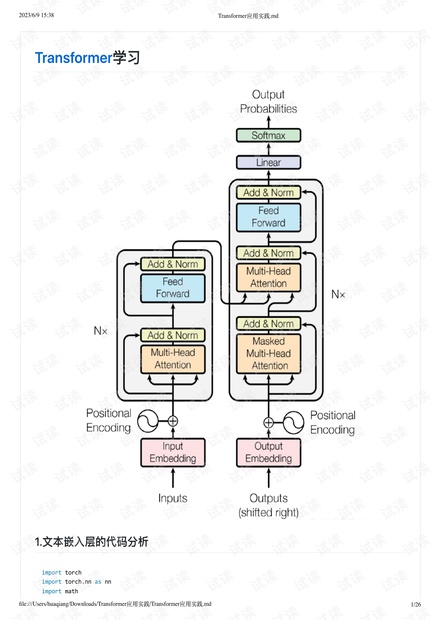
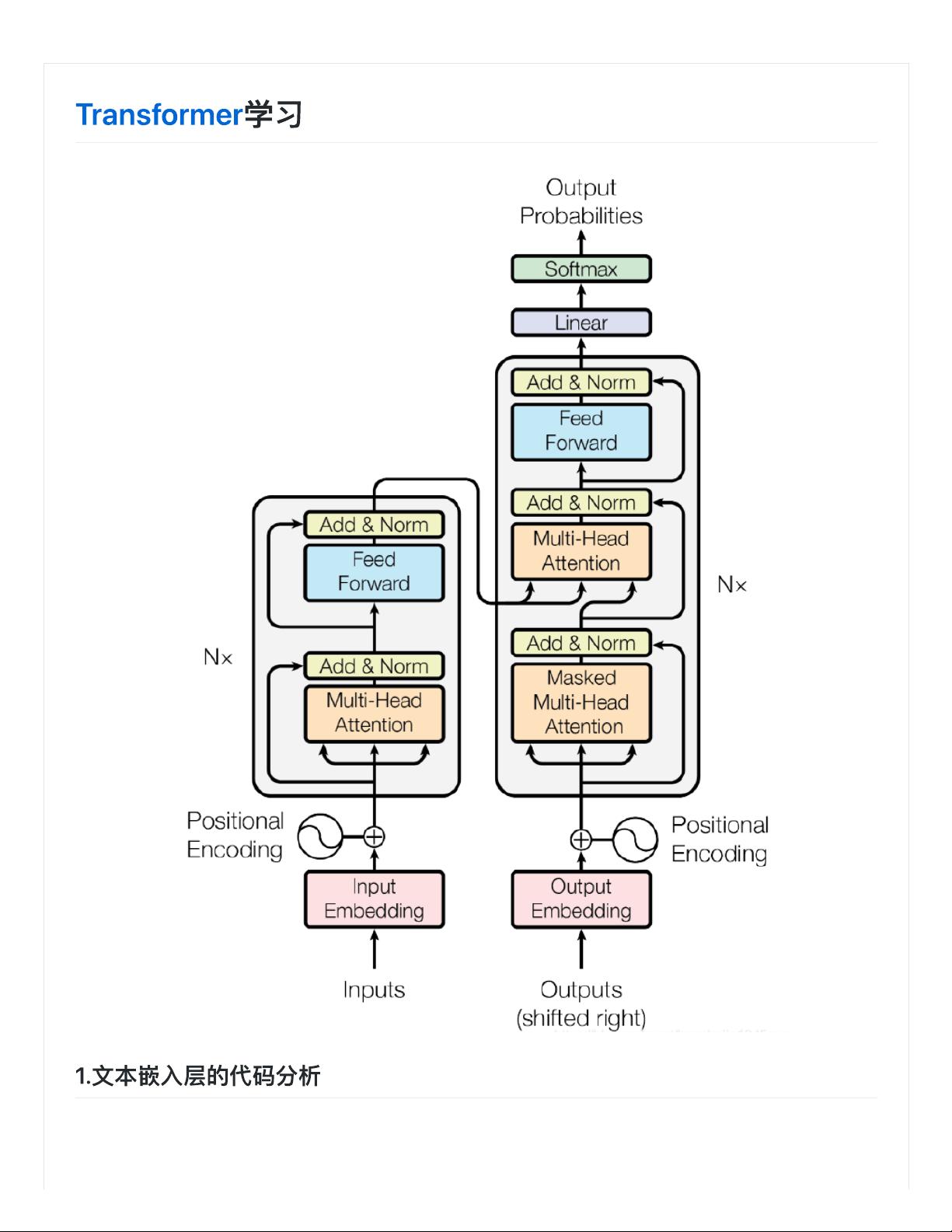
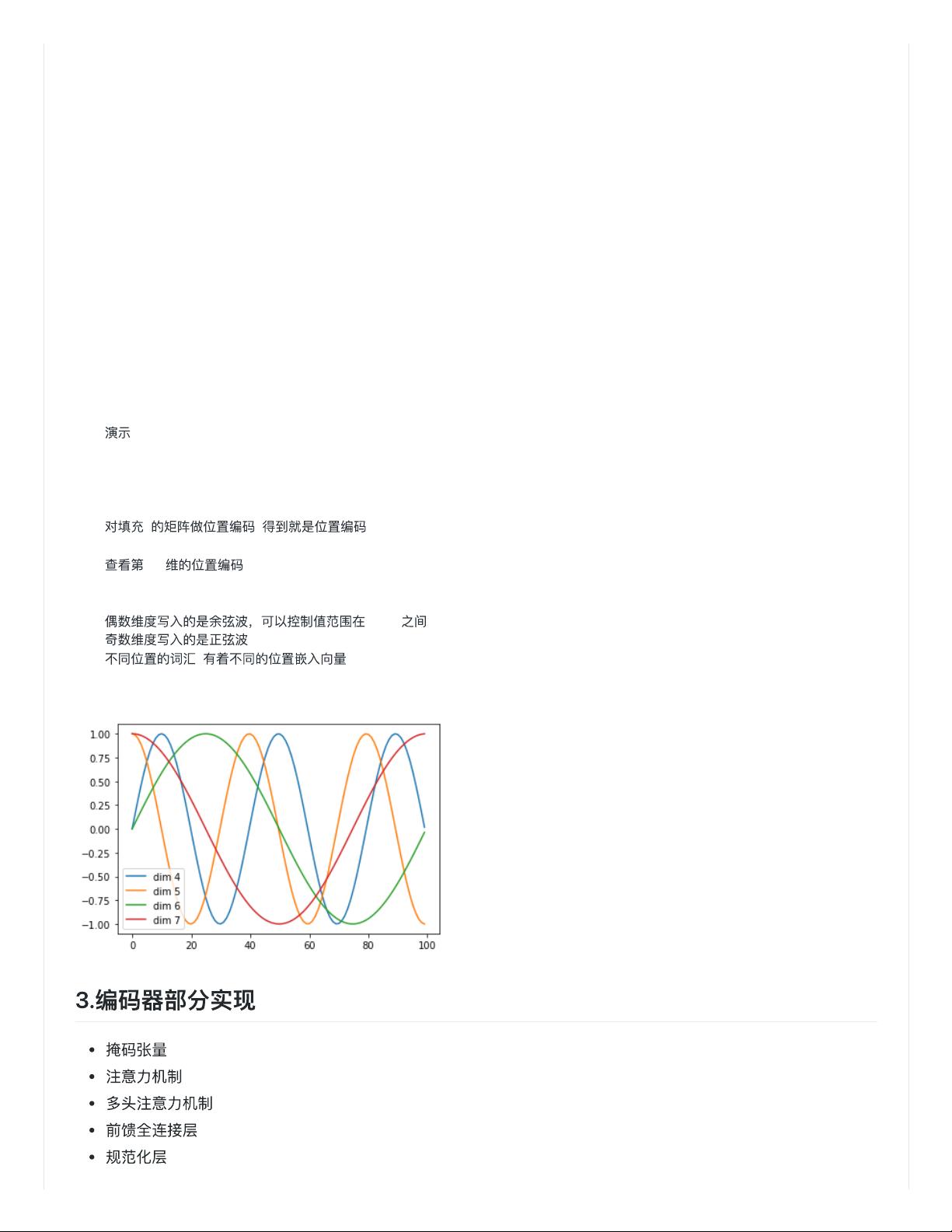
file:///Users/huaqiang/Downloads/Transformer应⽤实践/Transformer应⽤实践.md
from torch.autograd import Variable #
import numpy as np
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
# d_model:
# vocab:
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model) # Embedding
self.d_model = d_model
def forward(self, x):
# x lut d_model
return self.lut(x) * math.sqrt(self.d_model)
#
embedding = nn.Embedding(10, 3) #
embedding(torch.LongTensor([[1,0,3,0],[5,0,7,0]]))
tensor([[[ 0.1369, -1.1720, -0.3088],
[-0.2342, 0.0257, -0.1409],
[-2.0039, 0.6588, 1.1285],
[-0.2342, 0.0257, -0.1409]],
[[-0.7278, -0.5684, 0.8189],
[-0.2342, 0.0257, -0.1409],
[-1.5166, 0.1493, 0.2819],
[-0.2342, 0.0257, -0.1409]]], grad_fn=<EmbeddingBackward>)
embedding = nn.Embedding(10, 3, padding_idx=0)
embedding(torch.LongTensor([[1,0,3,0],[5,0,7,0]]))
tensor([[[-0.1809, -0.1365, 1.2656],
[ 0.0000, 0.0000, 0.0000],
[-0.4129, 0.9765, 1.2057],
[ 0.0000, 0.0000, 0.0000]],
[[ 1.8736, -1.4908, -0.4024],
[ 0.0000, 0.0000, 0.0000],
[ 0.4857, 0.1198, -0.8273],
[ 0.0000, 0.0000, 0.0000]]], grad_fn=<EmbeddingBackward>)
d_model = 512 #
vocab = 1000 #
x = Variable(torch.LongTensor([[100,2,421,508],[491,998,1,221]]))
x