

Benchmarking Foundation Models with
Language-Model-as-an-Examiner
Yushi Bai
1∗
, Jiahao Ying
2∗
, Yixin Cao
2
, Xin Lv
1
, Yuze He
1
,
Xiaozhi Wang
1
, Jifan Yu
1
, Kaisheng Zeng
1
, Yijia Xiao
3
,
Haozhe Lyu
4
, Jiayin Zhang
1
, Juanzi Li
1
, Lei Hou
1B
1
Tsinghua University, Beijing, China
2
Singapore Management University, Singapore
3
University of California, Los Angeles, CA, USA
4
Beijing University of Posts and Telecommunications, Beijing, China
Abstract
Numerous benchmarks have been established to assess the performance of founda-
tion models on open-ended question answering, which serves as a comprehensive
test of a model’s ability to understand and generate language in a manner similar to
humans. Most of these works focus on proposing new datasets, however, we see
two main issues within previous benchmarking pipelines, namely testing leakage
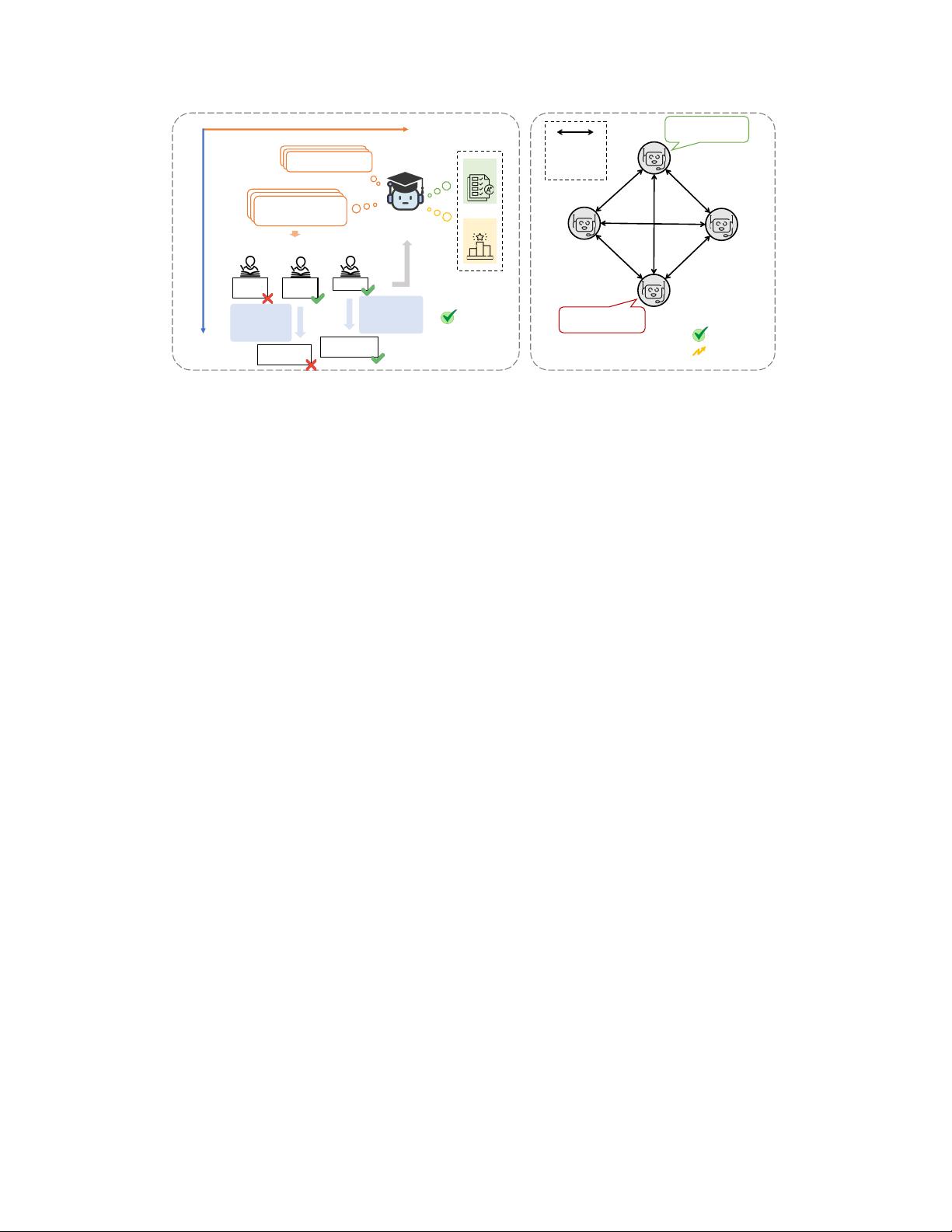
and evaluation automation. In this paper, we propose a novel benchmarking frame-
work, Language-Model-as-an-Examiner, where the LM serves as a knowledgeable
examiner that formulates questions based on its knowledge and evaluates responses
in a reference-free manner. Our framework allows for effortless extensibility as
various LMs can be adopted as the examiner, and the questions can be constantly
updated given more diverse trigger topics. For a more comprehensive and equitable
evaluation, we devise three strategies: (1) We instruct the LM examiner to generate
questions across a multitude of domains to probe for a broad acquisition, and raise
follow-up questions to engage in a more in-depth assessment. (2) Upon evaluation,
the examiner combines both scoring and ranking measurements, providing a reli-
able result as it aligns closely with human annotations. (3) We additionally propose
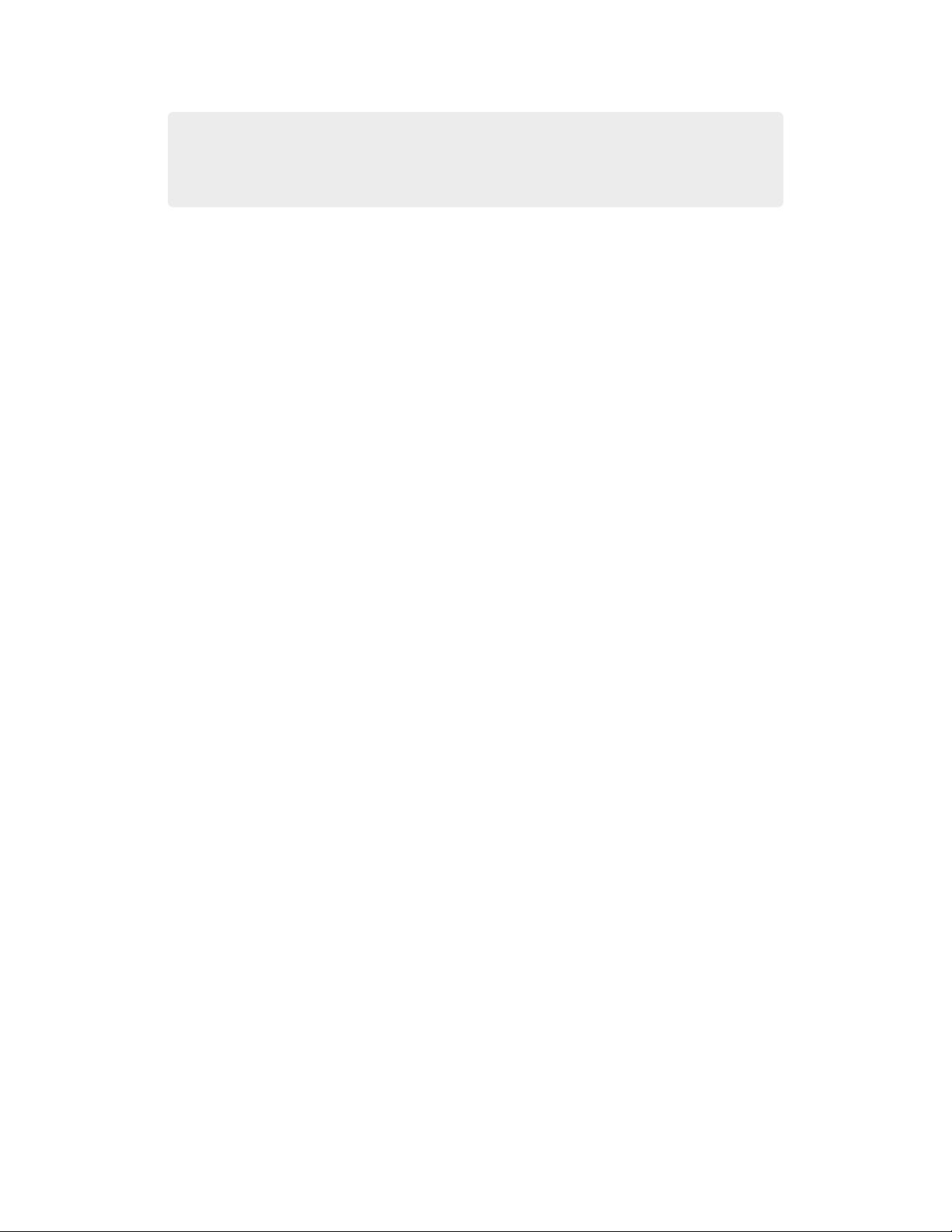
a decentralized Peer-examination method to address the biases in a single examiner.
Our data and benchmarking results are available at: http://lmexam.xlore.cn.
1 Introduction
Recently, many large foundation models [
1
], such as ChatGPT [
2
], LLaMA [
3
], and PaLM [
4
], have
emerged with impressive general intelligence and assisted billions of users worldwide. For various
users’ questions, they can generate a human-like response. However, the answers are not always
trustworthy, e.g., hallucination [
5
]. To understand the strengths and weaknesses of foundation models,
various benchmarks have been established [6, 7, 8, 9, 10].
Nevertheless, we see two main hurdles in existing benchmarking methods, as summarized below. (1)
Testing leakage. Along with increasing tasks and corpus involved in pre-training, the answer to the
testing sample may have been seen and the performance is thus over-estimated. (2) Evaluation au-
tomation. Evaluating machine-generated texts is a long-standing challenge. Thus, researchers often
convert the tasks into multi-choice problems to ease the quantitative analysis. This is clearly against
real scenarios — as user-machine communications are mostly open-ended Question Answering (QA)
or freeform QA [
11
]. On the other hand, due to the existence of a vast number of valid “good”
answers, it is impossible to define one or several groundtruth, making similarity-based matching
∗
Equal contribution
37th Conference on Neural Information Processing Systems (NeurIPS 2023) Track on Datasets and Benchmarks.


剩余25页未读,继续阅读
资源评论













