

Chapter 5
Least Squares
The term least squares describes a frequently used approach to solving overdeter-
mined or inexactly specified systems of equations in an approximate sense. Instead
of solving the equations exactly, we seek only to minimize the sum of the squares
of the residuals.
The least squares criterion has important statistical interpretations. If ap-
propriate probabilistic assumptions about underlying error distributions are made,
least squares produces what is known as the maximum-likelihood estimate of the pa-
rameters. Even if the probabilistic assumptions are not satisfied, years of experience
have shown that least squares produces useful results.
The computational techniques for linear least squares problems make use of
orthogonal matrix factorizations.
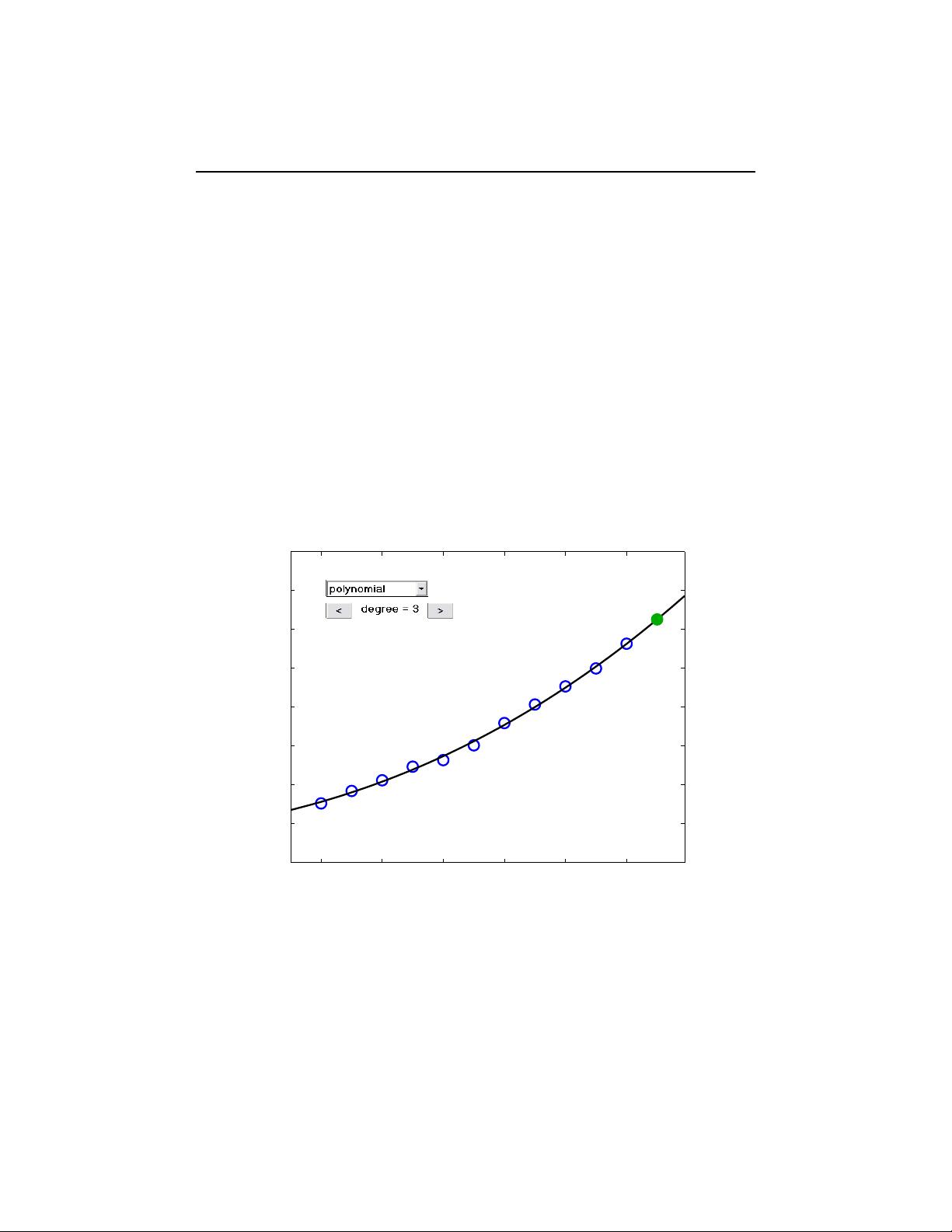
5.1 Models and Curve Fitting
A very common source of least squares problems is curve fitting. Let t be the
independent variable and let y(t) denote an unknown function of t that we want
to approximate. Assume there are m observations, i.e. values of y measured at
specified values of t.
y
i
= y(t
i
), i = 1, . . . , m
The idea is to model y(t) by a linear combination of n basis functions,
y(t) ≈ β
1
φ
1
(t) + . . . + β
n
φ
n
(t)
The design matrix X is a rectangular matrix of order m-by-n with elements
x
i,j
= φ
j
(t
i
)
The design matrix usually has more rows than columns. In matrix-vector notation,
the model is
y ≈ Xβ
1



剩余26页未读,继续阅读

zxjnttc
- 粉丝: 0
- 资源: 7









最新资源
- package-demo
- sglang0.4.1版本
- 基于comsol激光熔覆技术的多层多道熔覆方法及其实验视频与模型资源解析,COMSOL激光熔覆技术:多层多道工艺详解,融合视频教程与模型解析,comsol激光熔覆 多层多道 包括视频和模型 ,coms
- 三轴步进电机控制实现:基于博途1200 PLC与WinCC程序的集成,含运行步骤效果视频及CAD接线图解析 ,三轴步进电机控制:博途1200PLC与WinCC程序整合实践,V15.1版本详解,附运行操
- Blood Cell images for Cancer detection dataset-用于癌症检测的血细胞图像数据集
- Dynamic Class Loading in the JavaTM Virtual Machin
- 基于粒子群算法的四粒子MPPT最大功率点追踪与仿真模拟(负载变化及迭代性能分析),粒子群算法MPPT追踪最大功率点:双模型仿真及负载变化分析,1粒子群算法mppt(四个粒子),代码注释清晰, 2
- 大学实验课设无忧 - 基于FPGA流水灯
- “人工势场法路径规划算法:高效势函数法引领未来智能导航新篇章”,人工势场法路径规划算法-势函数法APF简洁高效实现,人工势场法 路径规划算法 势函数法 APF 简单,高效 ,人工势场法;路径规划算法
- Oasys Primer教程:JFOLD安全气囊仿真折叠,详细教程含所有K文件及结果,TUCK折叠到内侧实战指南,Oasys Primer之JFOLD安全气囊仿真折叠手册:步骤详解及软件应用,从TUC
- IRIS数据集-分类-IRIS dataset - Classification
- 搞懂网络安全等级保护,弄懂这253张拓扑图就够了
- 跨操作系统Java开发环境搭建详解与高级配置
- CyberChef解密工具
- 前列腺癌症的临床病理特征数据集-Prostate Cancer Clinical and Pathological Features
- 安川控制器Mp2000运动模块使用说明
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0