Hadoop Network
需积分: 9 97 浏览量
2013-07-07
12:20:09
上传
评论
收藏 2.74MB PDF 举报


http://bradhedlund.com/?p=3108
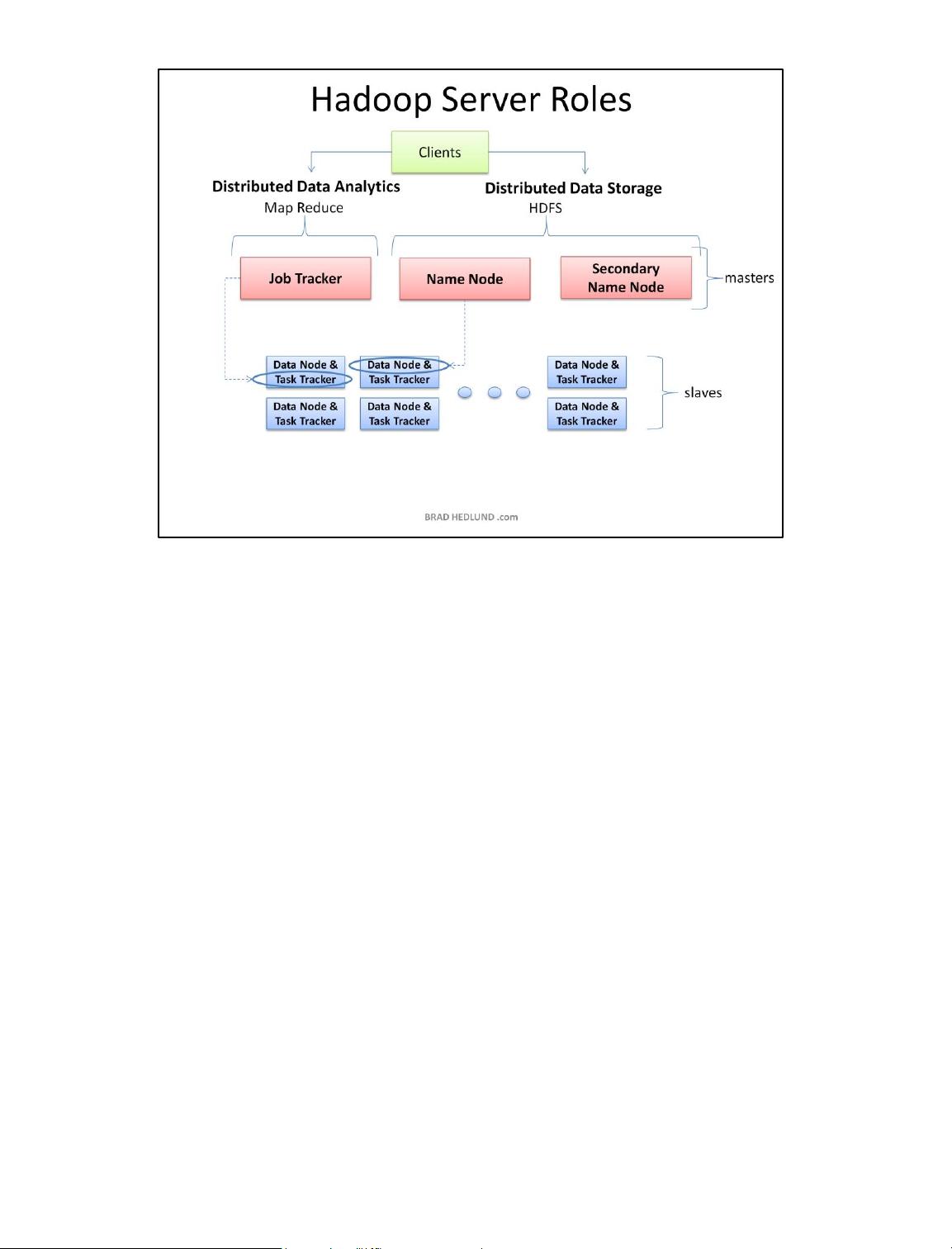
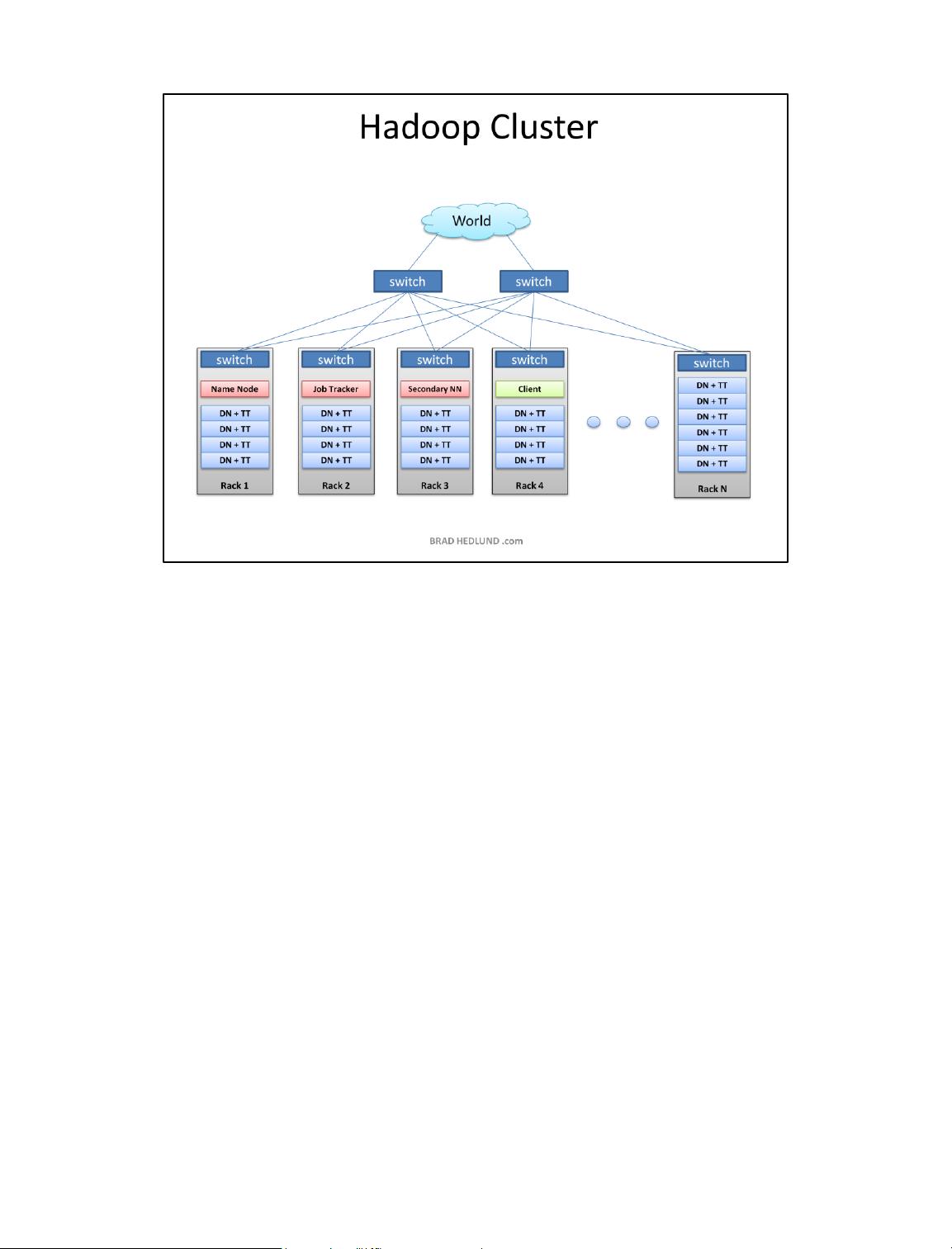
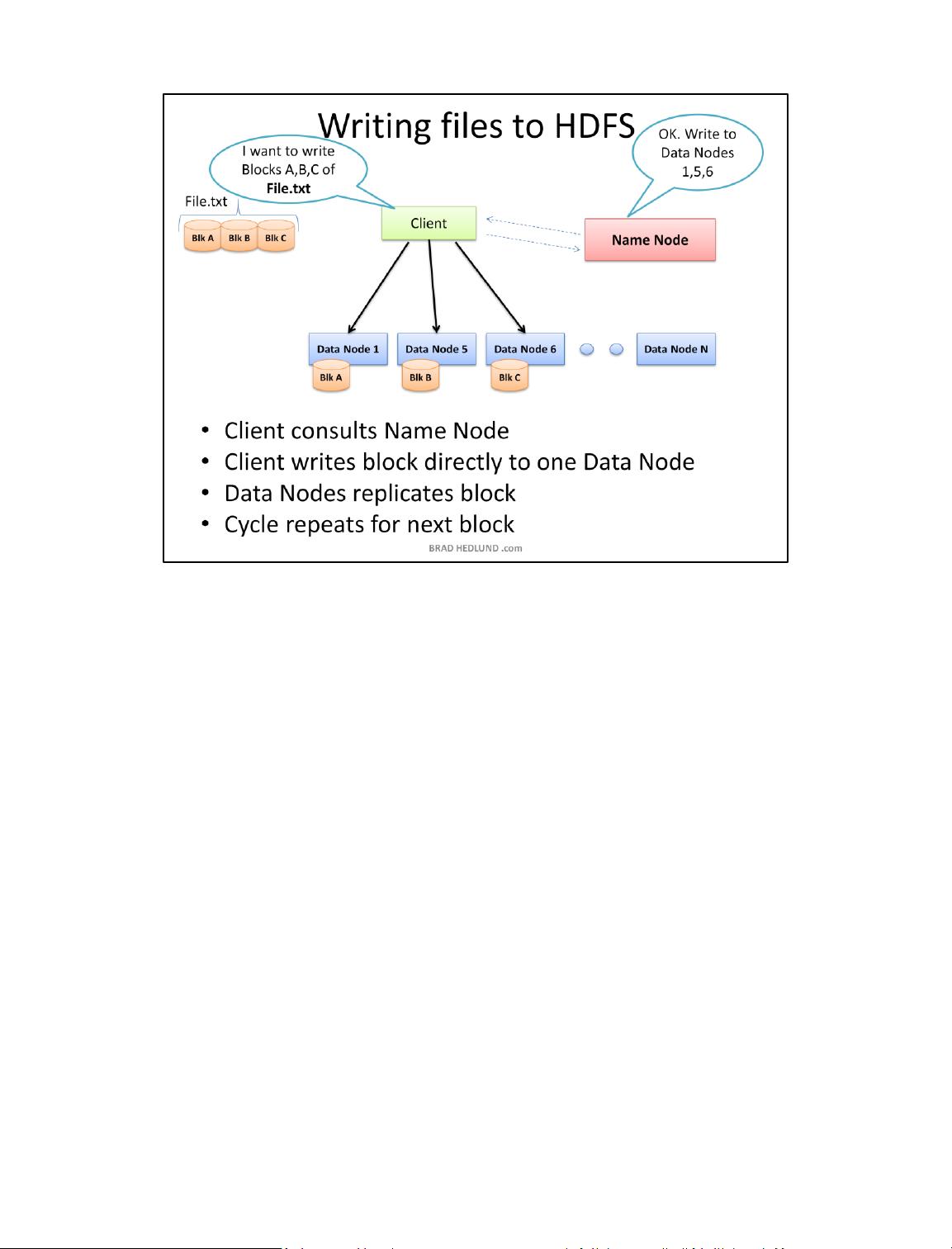
This article is Part 1 in series that will take a closer look at the architecture and
methods of a Hadoop cluster, and how it relates to the network and server
infrastructure. The content presented here is largely based on academic work
and conversations I‘ve had with customers running real production clusters. If you
run production Hadoop clusters in your data center, I'm hoping you'll provide your
valuable insight in the comments below. Subsequent articles to this will cover the
server and network architecture options in closer detail. Before we do that though,
lets start by learning some of the basics about how a Hadoop cluster works. OK, lets
get started!
1

剩余25页未读,继续阅读













评论0