
1
深入理解 Hadoop 集群和网络
本文将着重于讨论 Hadoop 集群的体系结构和方法,及它如何与网络和服务器基础设施的关
系。最开始我们先学习一下 Hadoop 集群运作的基础原理。
云计算和 Hadoop 中网络是讨论得相对比较少的领域。本文原文由 Dell 企业技术专家
Brad Hedlund
撰写,他曾在思科工作多年,专长是数据中心、云网络等。文章素材基于作
者自己的研究、实验和 Cloudera 的培训资料。
本文将着重于讨论 Hadoop 集群的体系结构和方法,及它如何与网络和服务器基础设施
的关系。最开始我们先学习一下 Hadoop 集群运作的基础原理。
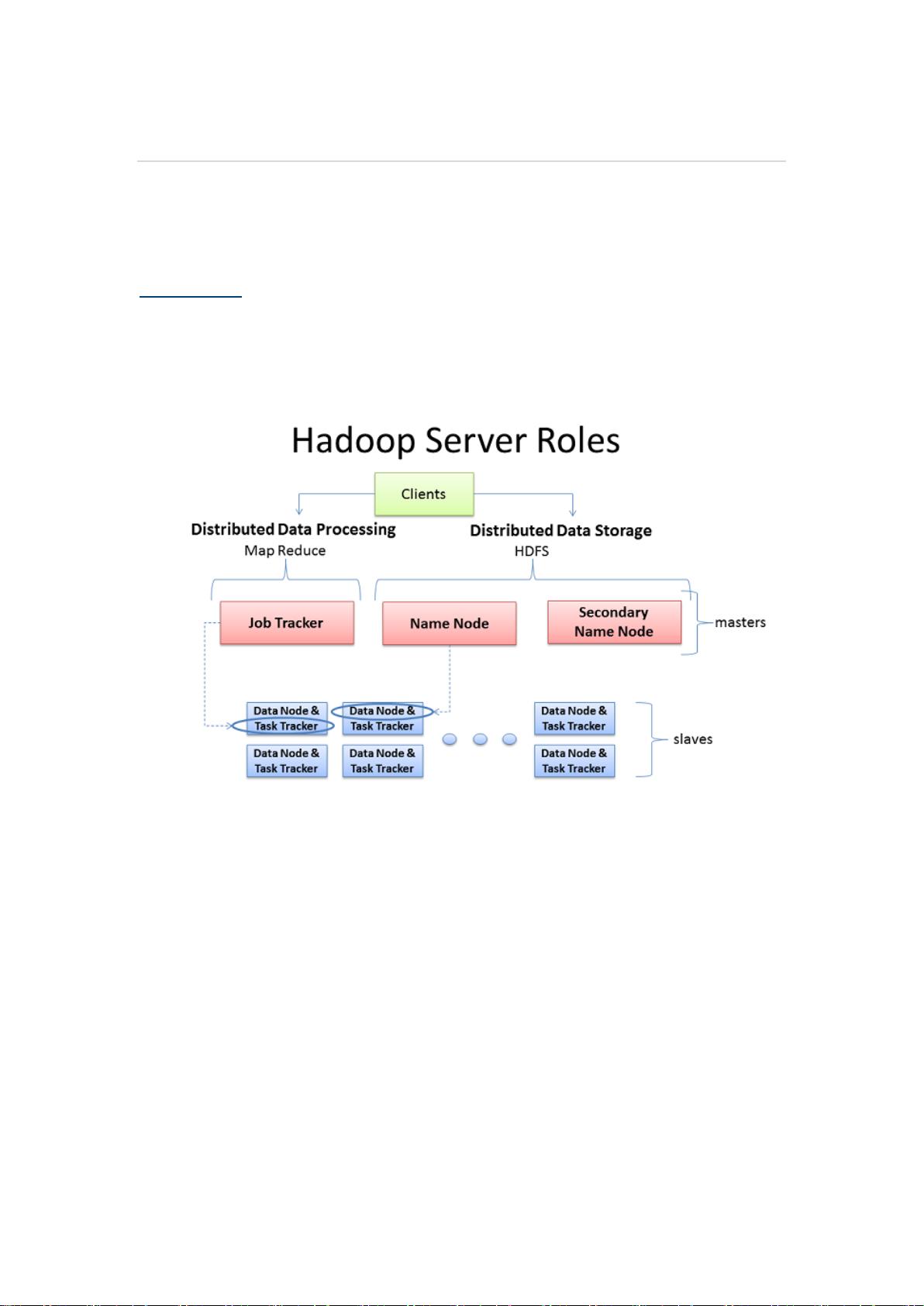
Hadoop 里的服务器角色
Hadoop 主要的任务部署分为 3 个部分,分别是:Client 机器,主节点和从节点。主节
点主要负责 Hadoop 两个关键功能模块 HDFS、Map Reduce 的监督。当 Job Tracker 使用 Map
Reduce 进行监控和调度数据的并行处理时,名称节点则负责 HDFS 监视和调度。从节点负责
了机器运行的绝大部分,担当所有数据储存和指令计算的苦差。每个从节点既扮演者数据节
点的角色又冲当与他们主节点通信的守护进程。守护进程隶属于 Job Tracker,数据节点在
归属于名称节点。
Client 机器集合了 Hadoop 上所有的集群设置,但既不包括主节点也不包括从节点。取
而代之的是客户端机器的作用是把数据加载到集群中,递交给 Map Reduce 数据处理工作的
描述,并在工作结束后取回或者查看结果。在小的集群中(大约 40 个节点)可能会面对单


剩余17页未读,继续阅读
资源评论

 yutao3142018-03-03写的不错,中文的,加油
yutao3142018-03-03写的不错,中文的,加油












