
ChartLlama论文

需积分: 0 172 浏览量
更新于2024-07-15
1
收藏 2.51MB PDF 举报
### ChartLlama论文知识点概述
#### 一、论文背景与目的
**背景:**
随着人工智能技术的发展,尤其是自然语言处理(NLP)领域的突破,多模态大语言模型在多种视觉语言任务上展现出了强大的能力。然而,在面对特定领域数据时,尤其是在图表理解方面,这些模型的表现往往不尽如人意。这主要是因为缺乏高质量的多模态指令微调数据集。
**目的:**
本论文旨在通过创建一个高质量的多模态指令微调数据集来提升模型在图表理解和生成方面的性能。该数据集基于GPT-4开发,并通过一个多步骤的数据生成流程来确保其质量和多样性。
#### 二、ChartLlama简介
**定义:**
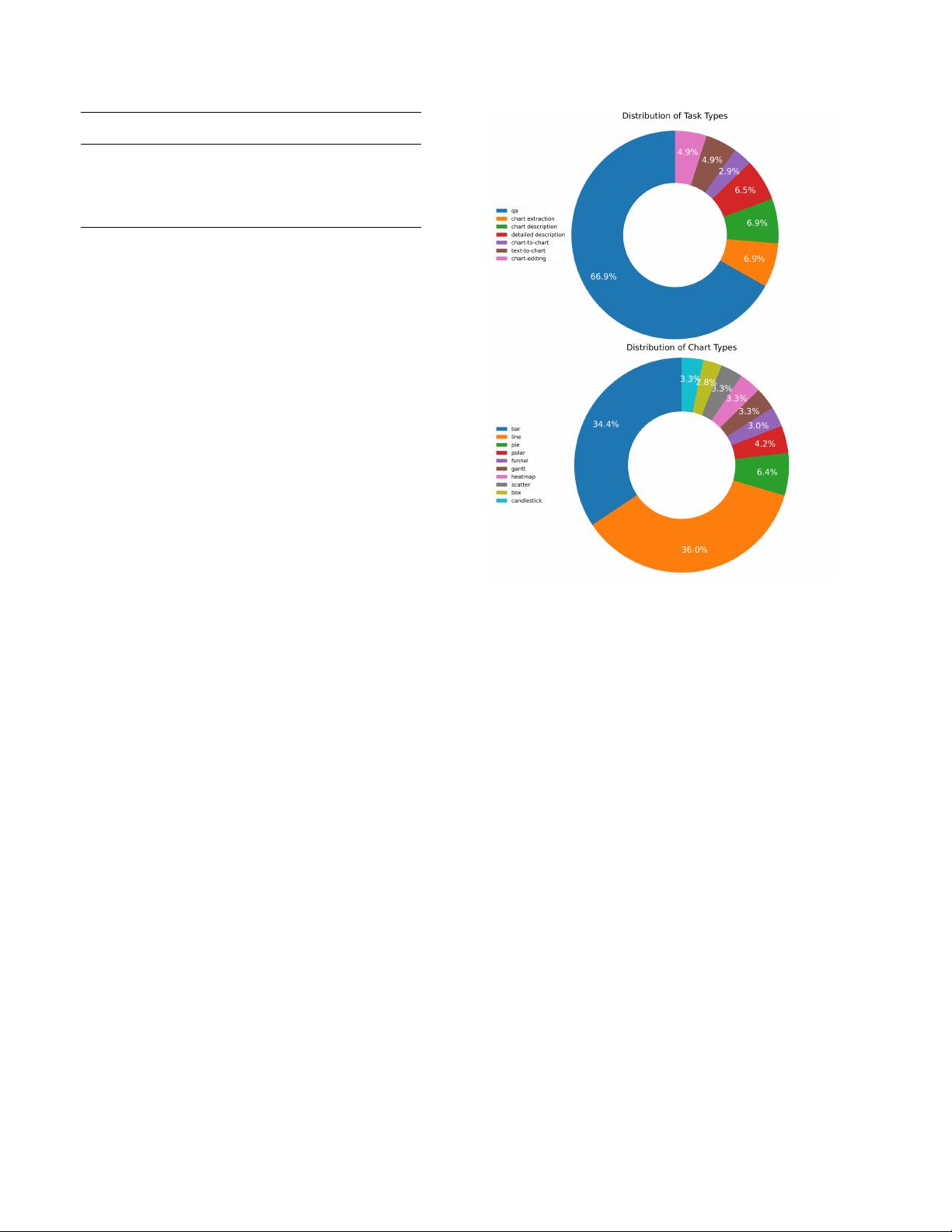
ChartLlama是一款专为图表理解和生成设计的多模态大语言模型。它能够处理复杂的图表结构,并具备将图表转换为文本描述、图表间转换以及图表编辑等多种能力。
**核心功能:**
1. **图表描述**:能够根据给定的图表生成详细的文本描述。
2. **图表提取**:能够从图表中提取具体的信息或数据。
3. **图表转表格**:能够将图表中的数据转换成表格形式。
4. **图表到图表**:能够将一种类型的图表转换为另一种类型,比如柱状图转饼图。
5. **文本到图表**:根据文本描述自动生成相应的图表。
6. **图表编辑**:能够进行图表背景更改、网格线去除等操作。
#### 三、数据集创建与训练过程
**数据集创建:**
为了训练ChartLlama模型,本研究团队提出了一种基于GPT-4的高质量多模态指令微调数据集创建方法。该方法包括以下几个关键步骤:
1. **数据收集**:收集大量包含图表的文档,涵盖不同领域和类型的图表。
2. **数据预处理**:对收集到的数据进行清洗、标注和格式化,确保数据质量。
3. **数据增强**:通过数据增强技术增加数据集的多样性和复杂性。
4. **指令设计**:设计一系列指令模板,用于指导模型完成特定任务,如图表描述、图表转文本等。
5. **质量控制**:通过人工评估和自动化检查来确保数据集的质量。
**模型训练:**
训练过程主要分为以下几个阶段:
1. **预训练**:利用大规模文本语料库对模型进行预训练,建立基本的语言理解能力。
2. **指令微调**:在上述创建的多模态指令微调数据集上对模型进行进一步训练,使其具备处理图表相关任务的能力。
3. **评估与优化**:通过多种评估指标监测模型性能,并针对不足之处进行迭代优化。
#### 四、应用场景与展望
**应用场景:**
ChartLlama模型可以应用于多个场景,包括但不限于:
- **商业智能**:帮助企业快速理解复杂的数据报告和市场趋势。
- **教育领域**:辅助教学资源的制作,帮助学生更好地理解统计数据。
- **新闻报道**:自动分析和解释数据图表,提高新闻报道的质量和效率。
- **科研工作**:支持科研人员快速解读实验结果和科学数据。
**未来展望:**
随着技术的不断进步,ChartLlama模型有望在更多领域得到应用和发展。未来的研究方向可能包括模型的可扩展性、多语言支持、以及更高级的图表理解和生成能力等方面。此外,探索如何使模型更加人性化、易于使用也将成为重要的研究课题之一。

ChartLlama: A Multimodal LLM for Chart Understanding and Generation
Yucheng Han
1,2∗
Chi Zhang
2∗†
Xin Chen
2
Xu Yang
3
Zhibin Wang
2
Gang Yu
2
Bin Fu
2
Hanwang Zhang
1
1
Nanyang Technological University
2
Tencent
3
Southeast University
1
{yucheng002, hanwangzhang}@ntu.edu.sg
2
{johnczhang, shingxchen, billzbwang, skicyyu, brianfu}@tencent.com
3
xuyang palm@seu.edu.cn
https://tingxueronghua.github.io/ChartLlama/
Q&A
Chart description
Chart extraction
Q: What is the
number of Pop
songs in the 2000s
according to the
chart?
A: 50
Q: Please summarize
the chart with text.
A: The chart presents
data on the popularity
of various gadgets
from 2016 to…
Q: Convert the
figure into table.
A:
Flood 30.0%
Earthquake 15.0%
Hurricane 20.0%
Tornado 15.0%
Wildfire 10.0%
More chart types and abilities…
Chart-to-chart
Q: Derender the given image to Python code
using matplotlib.
Text-to-chart
A:
import …
ax=plt.subplots(figsize=(10, 6))
ax.plot(x, y,
label=column, linewidth=2,
marker='o', markersize=10,
alpha=0.7)
for i,txt in enumerate(df['2020’]):…
Chart editing
Q: Change the background of the figure to
white and remove the grid lines.
Q: Change the color of the image by setting
a different color for each category of bars.
Q: Convert the
figure into pie table.
Facebook 30.0%
Twitter 15.0%
Wechat 20.0%
Tiktok 35.0%
Figure 1. Capability demonstration of ChartLlama. An instruction-tuning dataset is created based on our proposed data generation
pipeline. We train ChartLlama on this dataset and achieve the abilities shown in the figure.
Abstract
Multi-modal large language models have demonstrated
impressive performances on most vision-language tasks.
However, the model generally lacks the understanding ca-
pabilities for specific domain data, particularly when it
comes to interpreting chart figures. This is mainly due to
the lack of relevant multi-modal instruction tuning datasets.
In this article, we create a high-quality instruction-tuning
dataset leveraging GPT-4. We develop a multi-step data
generation process in which different steps are respon-
*
Equal contributions. Work was done when Yucheng Han was a Re-
search Intern at Tencent.
†
Corresponding Author.
sible for generating tabular data, creating chart figures,
and designing instruction tuning data separately. Our
method’s flexibility enables us to generate diverse, high-
quality instruction-tuning data consistently and efficiently
while maintaining a low resource expenditure. Addition-
ally, it allows us to incorporate a wider variety of chart and
task types not yet featured in existing datasets. Next, we in-
troduce ChartLlama, a multi-modal large language model
that we’ve trained using our created dataset. ChartLlama
outperforms all prior methods in ChartQA, Chart-to-text,
and Chart-extraction evaluation benchmarks. Additionally,
ChartLlama significantly improves upon the baseline in our
specially compiled chart dataset, which includes new chart
and task types. The results of ChartLlama confirm the value
1
arXiv:2311.16483v1 [cs.CV] 27 Nov 2023


剩余18页未读,继续阅读
2023-03-21 上传
180 浏览量
172 浏览量
188 浏览量
156 浏览量
2023-05-01 上传
170 浏览量
125 浏览量
2023-04-12 上传
176 浏览量
153 浏览量
2024-02-03 上传
151 浏览量
189 浏览量
106 浏览量
193 浏览量
177 浏览量
186 浏览量
165 浏览量
170 浏览量
资源评论


需要重新演唱
- 粉丝: 8824
- 资源: 3









最新资源
- ztree的demo入门
- STM32定时器对象捕获功能测量市电频率
- 1717skddhscq_downcc.zip
- 2022年电赛e题声源定位跟踪系统.zip
- Mini-Imagenet数据集文件
- MATLAB实现SSA-CNN-LSTM-Multihead-Attention多头注意力机制多变量时间序列预测(含完整的程序,GUI设计和代码详解)
- Matlab实现MTF-CNN-Mutilhead-Attention基于马尔可夫转移场-卷积神经网络融合多头注意力多特征数据分类预测(含完整的程序,GUI设计和代码详解)
- 知行乐评ver1.1.0
- treegird的demo
- Towards a Digital Engineering Initialization Framework迈向数字工程初始化框架
