

统计工具箱在聚类分析中的应用
MATLAB
统汁工具箱提供给人们一个强有力的统计分析工具,是口前国际 上流
MATLAB
行的科学计算软件,具有强大的矩阵计算和数据可视化能力,可实现数据讣 算、图形
处理、自动处理和信息处理等多种功能;同时,随着经济社会的飞速发 展,大数据时
代已经悄然来临,海量的数据分类、处理工作显得尤为繁杂,而聚 类分析在解决这一
繁杂工作的过程中起着不可替代的作用。那么釆取何种办法对 样本点进行聚类,才
能使得大量的样本按照各自特性进行合理分类,也是一个值
得探究的问题。在
MATLAB
统计工具箱中提供了许多聚类分析工具,
k-means 聚类就是其中一种,也叫
k
均值聚类,本文主要探讨
聚类方法,并将其 运用于实例分析。
k-means
关键词,
matlab
统计工具箱,聚类分析,
k-means
聚类
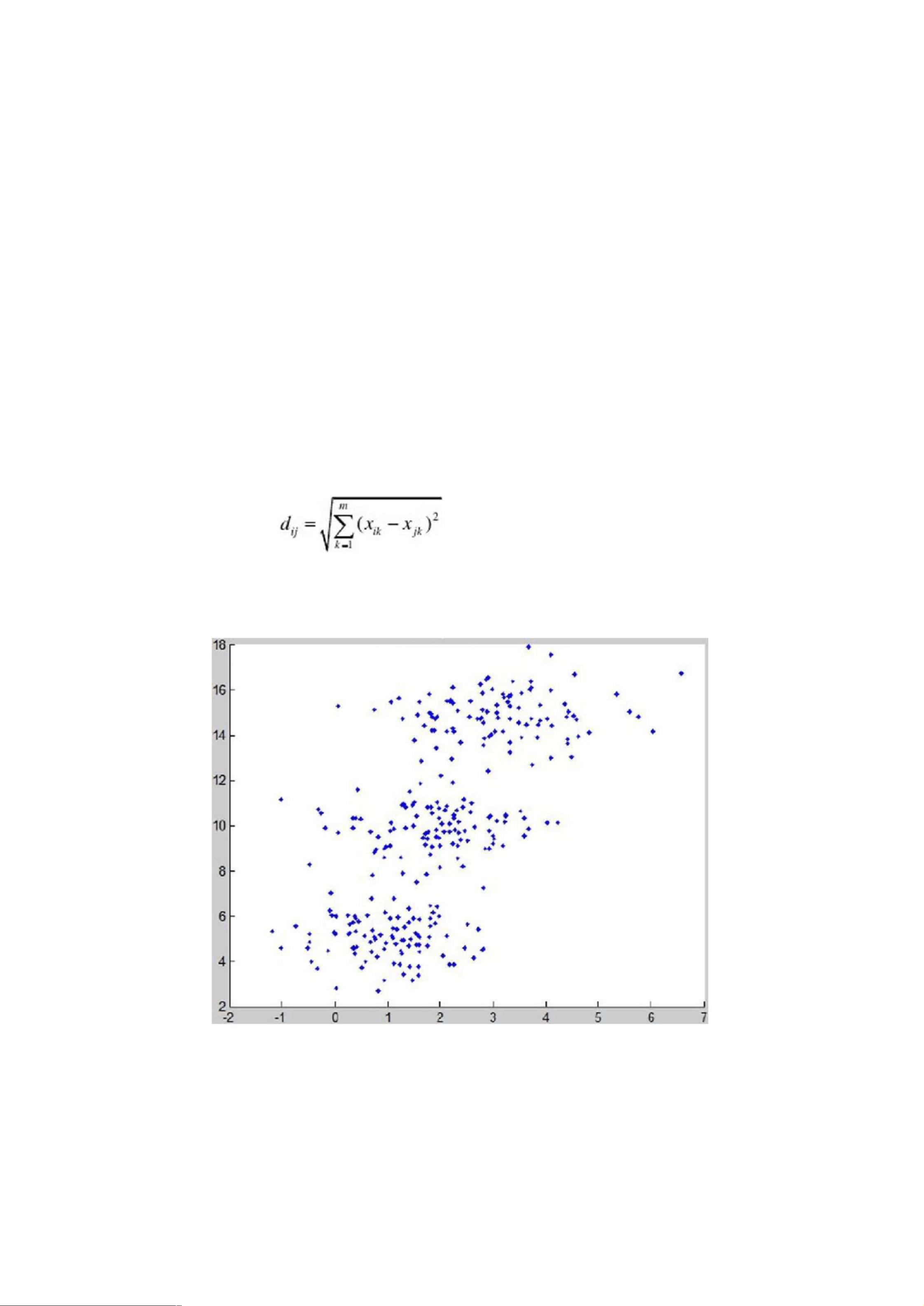
问题背景
1.1
聚类分析
(ClusterAnalysis),
是将一组研究对象分为相对同质的群组的 统汁分
析技术,乂称群分析或分类分析,通俗易懂的来说,它是根据“物以 类聚”的道
理,对某些指标或样品进行分类的一种多元统计分析方法。也就 是说,它们以大
量的样品为讨论对象,在没有任何模式依循或可供参考的条 件下,要求能够合理
地按照各自的特性或属性来进行合理的分类,是在没有 先验知识的悄况下进行
的。也就是说聚类与分类的不同在于,聚类所要求划 分的类是未知的,是将数据
分类到不同的类或者簇这样的一个过程,所以在 同一个簇中的对象有很大的相
似性,而不同簇间的对象有很大的相异性。从 统讣学的观点看,聚类分析是通过
数据建模简化数据的一种方法。
当今社会正处于大数据时代,在商业方面,聚类分析是细分市场的有效 工
具,同时也可用于研究消费者行为,寻找新的潜在市场、选择实验的市场, 并作
为多元分析的预处理;在经济领域,其可以帮助市场分析人员从客户数 据库中发
现不同的客户群,并且用购买模式来刻画不同客户群的特征;对住 宅区进行聚
类,确定自动提款机 的安放位置;对股票市场板块分析,找 出最具活力的
ATM
板块龙头股;还可用于企业信用等级分类等方面。在生物学领 域,其可推到动、
植物的分类;也可对基因分类,获得对种群的认识;在数据挖掘领域,其可作为

剩余13页未读,继续阅读
资源评论













