支持向量机SVM通俗理解(python代码实现).pdf

这是第三次来“复习”SVM了,第一次是使用SVM包,调用包并尝试调节参数。听闻了“流弊”SVM的算法。第二次学习理
论,看了李航的《统计学习方法》以及网上的博客。看完后感觉,满满的公式。。。记不住啊。第三次,也就是这次通
过python代码手动来实现SVM,才让我突然对SVM不有畏惧感。希望这里我能通过简单粗暴的文字,能让读者理解到底
什么是SVM,这货的算法思想是怎么样的。看之前千万不要畏惧,说到底就是个算法,每天啃一点,总能啃完它,慢慢
来还可以加深印象。
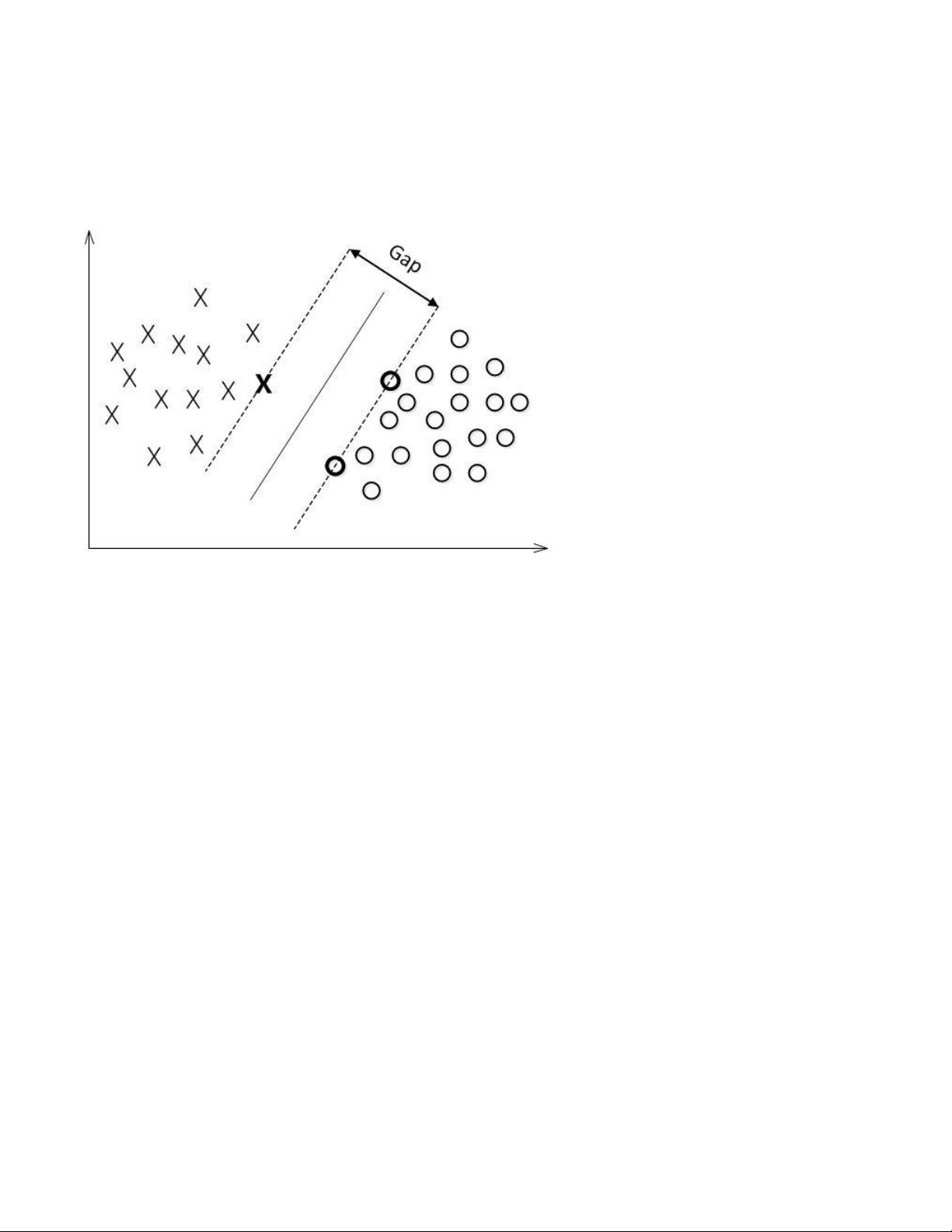
SVM是用来解决分类问题的,如果解决两个变量的分类问题,可以理解成用一条直线把点给分开,完成分类。如下:
上面这些点很明显不一样,我们从中间画一条直线就可以用来分割这些点,但是什么样的直线才是最好的呢?通俗的
说,就是一条直线“最能”分割这些点,也就是上图中的直线。他是最好的一条直线,使所有的点都“尽量”远离中间那条直
线。总得的来说,SVM就是为了找出一条分割的效果最好的直线。怎么样找出这条直线,就变成了一个数学问题,通过
数学一步一步的推导,最后转化成程序。这里举例是二个特征的分类问题,如果有三个特征,分类线就变成了分类平
面,多个特征的话就变成了超平面。从这个角度出发去看待SVM,会比较轻松。


剩余10页未读,继续阅读
资源评论

 Asama浅间2023-07-24作者对SVM算法的解释很中肯,避免了过于专业化的术语,使得读者更容易理解。
Asama浅间2023-07-24作者对SVM算法的解释很中肯,避免了过于专业化的术语,使得读者更容易理解。 yiyi分析亲密关系2023-07-24作者在该文件中通过简单易懂的Python代码实现了SVM算法,帮助读者更好地理解其原理。
yiyi分析亲密关系2023-07-24作者在该文件中通过简单易懂的Python代码实现了SVM算法,帮助读者更好地理解其原理。 王者丶君临天下2023-07-24这本文件的实用性很强,为读者提供了一种简单有效的方法来解决分类问题。
王者丶君临天下2023-07-24这本文件的实用性很强,为读者提供了一种简单有效的方法来解决分类问题。 高工-老罗2023-07-24这本文件对SVM算法的介绍非常详细,对于想深入学习和应用SVM的人来说是一本很有价值的资料。
高工-老罗2023-07-24这本文件对SVM算法的介绍非常详细,对于想深入学习和应用SVM的人来说是一本很有价值的资料。 首席程序IT2023-07-24这本文件对支持向量机进行了通俗易懂的解释,非常适合初学者入门。
首席程序IT2023-07-24这本文件对支持向量机进行了通俗易懂的解释,非常适合初学者入门。












